|
7. SSD와 서버: SSD
스토리지 클라우드를 구성하는 장비 내부는 결국 하드디스크들의 블럭 쌓기입니다. 거대한 클라우드도 한 개의 디스크로부터 출발합니다. SSD가 성능이 뛰어나기는 하지만 단순히 하드디스크를 SSD로 교체한다고 해서 전체 시스템의 성능이 그 만큼 좋아진다고 말할 수 없습니다. 아직은 가격, 용량, 특성에서 하드디스크가 장점이 더 많기 때문에 SSD가 잘 할 수 있는 분야를 찾아내는 것이 중요합니다. 이제 서버 분야에서 디스크 블럭을 SSD로 교체 하려면 어떤 전제가 필요한지 알아 보도록 하겠습니다.
7.1 SSD는 하드디스크에 최적화된 현재의 시스템 구성으로 사용되어서는 안 된다.
컴퓨터 디바이스와 프로그램들은 하드디스크의 느린 액세스 타임을 이해하는 소프트웨어의 도움을 받아 여러 가지 방법으로 최적화 되어 있습니다. 버퍼, 캐시, NCQ, TCQ등이 이 것입니다..
하드디스크에 작업을 요청하는 프로세스가 많아질수록 각각의 서비스 품질은 저하됩니다. 그러나 버퍼 캐시의 도움을 받은 상태에서 요청들을 재배열하여 최적화할 수 있기 때문에 전체적으로는 높은 대역폭을 낼 수 있습니다. 동시에 여러 프로세스가 다량의 데이터 요청을 하는 서버에서는 특히 이런 효과가 극대화됩니다.

하드디스크의 특성: 한 번에 요청하는 데이터 단위가 클수록 더 높은 전송률을 보입니다.

랜덤 읽기 테스트: 각각의 다른 데이터 요청을 하는 프로세스 수를 1,4,8~128개까지 증가시켰을 때 전체 데이터를 읽어오는데 걸리는 시간을 측정합니다. 프로세스가 늘어날수록 각각의 요청에 걸리는 시간이 늘어나고 전체 작업의 효율도 낮아지고 있습니다.

프로세스 수에 따른 전송률 그래프: 랜덤 읽기 테스트 결과의 전체 전송률을 나타낸 그래프입니다. 프로세스가 일정 개수 이하일 때는 그 수가 늘어남에 따라 전송률도 같이 높아집니다. 16~ 32개의 프로세스일 때 최대값이 나오고 있습니다. 그 후 프로세스 수가 더 많아져도 전체 대역폭은 크게 줄지 않습니다.
요청은 대기큐에 담기고 암 이동에 따라 재배열되면서 어느 순간까지는 프로세스 수에 비례하여 성능이 증가합니다. 블럭 디바이스의 최적화 루틴은 이렇게 하드디스크의 특성을 감안한 상태에서 최대한의 대역폭을 얻기 위해서 노력합니다. 그러나 SSD는 다릅니다.

SSD 전송률 그래프: SSD를 사용해서 같은 테스트 한 결과입니다. SSD는 초기부터 거의 최대 성능이 나오고 있으며 프로세스가 많아질수록 오히려 성능이 떨어지고 있습니다.
하드디스크의 동작 방식에 최적화된 현 시스템은 SSD에 오히려 불리하게 작용합니다. SSD를 위해서는 필요한 요청이 즉각적으로 처리되어야 하며 데이터 전송은 그대로 SSD로 보내는 것이 더 효율적입니다. 블록 전송을 위해 버퍼가 찰 때까지 기다리는 현 방식의 지연은 그대로 성능 저하로 나타나며 하드디스크 특성을 이용한 요청 재정렬은 SSD에게 있어서 무의미한 시간 낭비일 뿐입니다.
SSD는 아무런 스케줄링을 하지 않는 것이 최고의 성능을 낼 수 있는 방법입니다. SSD를 위한 디바이스 드라이버를 만들어 이런 스케줄링을 회피할 수 있게 하는 것이 한 방법이지만 블럭 디바이스 루틴과 연계되어 있기 때문에 현재로서는 운영체계 소스 코드 수준의 변경이 있어야 가능합니다.
오픈 소스가 아닌 윈도우에서는 마이크로소프트가 이 일을 해 줄 때까지 기다려야 합니다. SSD 특정 업체와 MS가 SSD에 맞춘 운영체계 새 버전을 준비하고 있다는 기사들이 나오고 있는데 대단한 작업을 하고 있는 것처럼 보이지만 알고 보면 그들이 할 일이란 "SSD 일 때 최적화 없음"으로 돌리도록 설정하는 것일 뿐입니다.
MS가 하드디스크와 블럭 디바이스의 최적화 설정 변경 기능을 제공했다면 업체들이 자체적으로 성능 향상을 위해 이 값을 변경해 볼 수 있었겠지만 그들은 타 업체에게 이런 자율권을 준 적이 없습니다. 샌디스크 같은 업체들이 비스타가 SSD에 최적화 되어 있지 않다고 비난하는 이유가 여기에 있습니다.
마치 멀쩡한 XP를 버리고 비스타 판매를 늘이기 위해서 다이렉트X 10을 비스타에만 사용가능하도록 만들었던 때와 같이 마이크로소프트는 SSD에는 "하드디스크 최적화 루틴 사용하지 않음"이라는 설정 변경을 다음 버전 윈도우의 주요한 기능으로 포장하기를 원할지도 모릅니다. 그렇게 되면 사람들은 SSD를 제대로 쓰고 싶어서 앞다투어 새버전 윈도우를 구입할 것이며 너도나도 벤치마크를 돌리며 달라진 결과에 행복해 할 것입니다. 언제나 그렇듯 기술은 마케팅을 이길 수 없습니다.
다행히 커널 소스가 공개된 리눅스에서는 이런 부분을 SSD에 맞게 변경할 수 있습니다. 어렵게 커널 소스를 고칠 필요도 없습니다. 간단한 플래그 세팅만으로도 하드디스크 최적화 루틴을 건너뛸 수 있습니다. 현재 리눅스에서 제공하는 블럭 디바이스 스케줄링 알고리즘은 다음과 같습니다.
Complete Fair Queuing(CFQ),
Deadline,
Anticipatory
No-op
이 중 3개는 하드디스크에 최적화된 블럭 디바이스 스케줄링 알고리즘이며 no-op는 스케줄링을 하지 않도록 하는 옵션입니다.

스케줄러에 따른 성능 변화: 하드디스크를 위한 스케줄러를 제거했을 때 SSD에서 좋은 성능이 나옵니다.

스케줄러에 따른 성능 변화: 8개의 하드디스크와 8개의 SSD를 묶어 테스트 했을 때의 그래프입니다. (8HDD CFQ는 8SSD CFQ와 겹쳐 있어서 잘 보이지 않습니다.)
8개를 한 단위로 사용했을 때 SSD와 하드디스크를 한 개씩 사용했을 때보다 더 큰 성능 차이를 보입니다. 하드디스크와 SSD의 최대 대역폭은 비슷하기 때문에 스케줄링을 사용했을 때 성능 차이가 보이지 않지만 스케쥴링을 제거했을 때 SSD에서 극적인 성능 향상이 있습니다.
현재의 스케쥴링 방식하에서는 SSD가 제 성능을 낼 수 없습니다. 지금 현재 리눅스는 간단한 설정 변경으로 SSD에 최적화를 시킬 수 있으며 윈도우도 차기 버전에서 SSD용 드라이버를 사용하고 블럭 디바이스 드라이버 설정 변경으로 SSD에 최적화 될 것입니다. 어떤 경우든 앞으로는 SSD를 하드디스크와는 다른 방식으로 처리해야 할 것입니다.

새로운 인터페이스: 인텔을 포함한 업체들은 차후 SATA와 같은 하드디스크 인터페이스를 제거하고 SSD를 바로 CPU와 메모리가 연결된 버스에 붙여서 최대 성능을 내도록 하려고 제안을 하고 있습니다. 이런 식으로 SSD를 사용하는 것이 대세가 될 것으로 예상합니다.
이미지 출처: http://www.flashmemorysummit.com/ English/Collaterals/Presentations/2008/20080813_T2A_Huffman.pdf
(위 사이트에서 SSD의 미래를 고민하는 관계사들의 자료들을 구할 수 있습니다.)
7.2 SSD는 아직 신뢰성 없는 저장장치이다.

SSD 읽기 에러: 응용 프로그램에서 종종 에러가 발생하며 아직은 대책이 없습니다.
하드디스크에 비해 안정적일 것이라는 믿음과는 달리 SSD는 아직 여러 가지 면에서 하드디스크에 미치지 못하고 있습니다. 에러 발생 빈도가 높은 편이며 그럼에도 복구 대책은 전무합니다. 특히 전원과 열 부분에 상당히 취약한 편입니다.
비정상적인 종료, 갑작스런 정전 등에도 SSD는 스토리지로서의 기능을 상실합니다. 이렇게 된 SSD는 전용 프로그램으로 초기화하지 않으면 인식조차 되지 않습니다. 특히 노트북의 슬립 기능이 잘못되었을 때 SSD에게는 치명적인 손상이 발생 합니다. 노트북을 사용하다가 끄지 않고 슬립 상태로 이동하는 경우에 어떤 이유로 슬립이 되지 않을 경우가 있습니다. 이 상태로 밀폐된 가방에 넣으면 노트북은 다운되기 전까지 온도가 올라갑니다. 뒤늦게 이 것을 발견하여 열을 식히고 나면 다른 부분은 정상으로 되돌아 오지만 SSD만 고장 나 있을 가능성이 높습니다. 고온에서 낸드플래시와 SSD 컨트롤러가 비정상 동작을 하게 되고 그에 따라 데이터가 손상 당하기 때문입니다.
전기적인 특성은 특히 많은 문제를 일으킵니다. 아날로그로 움직이는 기계적인 부분이 있는 하드디스크는 전원이 불량하면 동작 속도가 느려지는 식으로 적응을 하지만 SSD는 기동에 필요한 전압과 전류가 충분하지 않으면 정상 동작조차 하지 못하며 좀 더 심각해지면 잘못된 동작으로 데이터까지 날아가 버립니다.
호환성 부분도 문제가 심각합니다. 수십 년간 사용된 하드디스크 인터페이스에 맞추는 일은 SSD 입장에서 보면 아직 갈 길이 멀기만 합니다. 운영체계, 인터페이스, 사용 전압에 따라 제 각각인 방식에 적응하여야 하며, 칩셋 업체, 레이드 모드가 바뀔 때마다 문제가 발생하며 그 때마다 그 모든 경우에 대응할 수 있는 해결책을 내 놓아야 합니다. 여태까지 테스트 한 모든 업체의 SSD는 전부 이런 문제가 있었으며 버전업 하면서 겨우 하나씩 해결되어 왔습니다. 하드디스크와 동등한 SSD가 되기 위해서는 아직도 많은 시간이 필요할 것으로 생각됩니다.

전원 문제: SSD는 충분한 기동전압이 없으면 정상동작을 하지 못합니다. 하드디스크형 캠코더에 SSD를 장착하면 진동과 충격에도 강하게 만들 수 있지만 충분한 전원을 공급하지 못하는 한 SSD형 캠코더를 제대로 사용할 수 없습니다.

리눅스 인식 불량: 정상 응답을 하지 않는 SSD에 대해서 DMA 모드가 아닌 PIO 모드를 사용합니다. 그러나 이 SSD는 특정 섹터에 에러가 있어서 읽기 명령에 제대로 대응하지 못하고 있습니다. 하드디스크와 달리 SSD는 에러 난 영역을 건너뛰고 처리하는 식의 대응이 제대로 확립되어 있지 않습니다.

윈도우에서의 성능 저하: 윈도우는 특정 하드디스크와 SSD에 대한 정보를 기억하고 있습니다. 한 번 에러 난 제품은 윈도우가 계속해서 낮은 처리 속도로 사용합니다. SSD가 갑자기 느려졌다면 DMA가 아닌 PIO 모드로 처리되기 때문입니다. 이 때에는 장치관리자의 SSD가 연결된 채널(그림에서는 "기본 IDE 채널")을 삭제하고 재부팅하면 제 성능을 찾을 수 있습니다. 물론 SSD가 정상이고 일시적인 에러 때문인 경우에만 해당되는 이야기입니다.

불안정한 SSD: SSD에 데이터를 모두 채우기 테스트를 하고 나면 엄청난 성능 저하가 생기는 현상이 있습니다. 윈도우(xcopy /e /y c:\*.* d:\usrN 파일 복사 반복)와 리눅스(cp –a /usr /intel-ssd/usrN 반복) 양쪽에서 모두 발생하며 그 원인은 생산 업체에서도 찾고 있는 중입니다.

호환성: 스팩과는 달리 SATA 방식의 SSD를 장착하면 에러가 생기는 SAS 칩셋, 업체들은 하드디스크들만을 테스트 해서 출시하기 때문에 SSD는 이런 여러 가지 상황에 맞추어 개별적인 호환성 테스트를 따로 해야만 합니다.
그러나 무엇보다도 가장 큰 문제점은 에러가 났을 때 데이터를 살릴 방법이 없다는 것입니다. 하드디스크가 에러 났을 때는 불량 섹터를 건너뛰고 정상 섹터만 읽어서 일부 데이터를 찾을 수 있습니다. 회로부분이 고장났다면 정상 보드로 교체하여 살릴 수도 있습니다. 그러나 SSD는 웨어레벨링을 하기 때문에 낸드플래시의 논리 섹터를 순서대로 읽어서 데이터를 찾아 낼 수가 없습니다. 섹터 에러난 SSD에서 그 부분을 건너뛰고 읽을 수도 없습니다. 무엇보다도 하드디스크를 에물레이션하는 SSD 컨트롤러가 고장나고 나면 논리 섹터 정보가 들어있는 메타데이터가 날아가 버려서 스토리지로서의 기능을 상실해버립니다. 초기화를 거쳐 다시 정상상태로 돌아왔더라도 이미 데이터는 완전히 사라진 다음입니다. 물리적인 SSD는 고쳐서 쓸 수 있지만 데이터는 결코 다시 살릴 수가 없습니다.

컨트롤러와 플래시: SSD는 하드디스크를 에물레이션 할 뿐 그 자체는 아니기 때문에 에러 발생 후에 복구 대책은 하드디스크와 같을 수 없습니다. 낸드를 병렬로 처리하는 특성 상 한 개의 낸드가 에러가 생기면 마치 레이드0와 같이 모든 데이터를 읽을 수 없게 됩니다. 버퍼로 쓰는 DRAM은 전원이 갑자기 나갈 때 메타데이터까지 사라져서 SSD의 데이터를 못쓰게 만들 수도 있습니다.
지금까지의 SSD는 호환성이 부족하고 안정성도 떨어지며 에러 상황에서 데이터 복구가 거의 불가능하기 때문에 쓰기 위주의 저장장치로 쓰기에는 부족함이 많습니다. 노트북이나 데스크탑에 사용하려면 속도가 중요한 부팅 영역과 임시 데이터 저장소로 사용하는 것이 최선이며 데이터를 저장한다면 반드시 이중화하거나 수시로 백업을 하며 사용해야 합니다.
서버쪽에는 데이터가 날아가도 상관없는 영역에 한정하여 SSD를 사용하는 것이 최선입니다. 이중화된 캐시 서버, 동일한 데이터를 가지고 서비스하는 웹서버, 원본이 따로 보관된 스트리밍 서버, 읽기 전용의 검색용 인덱스 서버 등이 그 영역입니다. 메인 데이터베이스 서버 등에 사용하게 되면 심각한 문제가 있을 수 있다는 점을 명심해야 할 것입니다.

MLC SSD: SLC의 한 셀을 2bit 처리를 가능하게 만든 MLC를 사용한 SSD. MLC는 SSD에 비해 10분의 1에 불과한 수명, 훨씬 더 높은 에러 발생률, 극히 신뢰할 수 없는 데이터 안정성, 낮은 쓰기 속도 등으로 볼 때 데이터 저장 장치로 쓰기에는 문제가 많습니다. 아직 SLC 제품도 안정적이지 못한 지금 상황에서 MLC를 사용해서 SSD를 만드는 것은 너무 위험한 선택으로 보입니다. MLC가 안정화되고, 모든 문제를 처리할 수 있는 제대로 된 컨트롤러가 나온 이후에야 스토리지 장치로 고려해 볼 수 있습니다. 넷북과 같이 데이터를 별로 생성하지 않는 극히 제한된 영역을 제외하고는 대중적으로 쓰이기에는 많은 문제가 있습니다. 특히 서버에서는 결코 사용해서는 안 되는 제품입니다.
7.3 최상의 조건에서 최대의 성능보다는 최악의 상황에서 최선의 성능이 필요하다.
PATA와 SATA1을 지원하며 읽기 쓰기가 150MB/s 이하의 1세대 SLC SSD가 출현한 후로 SATA2를 지원하고 읽기 쓰기 속도가 300MB/s에 육박하는 2세대 제품들이 쏟아져 나오고 있습니다. 넷북에서는 자체 인터페이스를 채택하여 하드디스크 모드가 아닌 버스에 바로 연결되는 형태도 있으며 ExpressCard 방식도 출현하였습니다. I-RAM과 같은 방식으로 PCI-Express 카드 형태로 나와 경이적인 속도를 내는 제품도 있습니다. 이 모든 제품들은 속도 경쟁을 통해 자신들이 최고라고 주장하고 있습니다.

차세대 SSD: MLC로도 충분한 안정성과 속도를 낼 수 있다고 자신하고 있는 제품. 애초에 MLC를 기준으로 만든 컨트롤러이며 MLC로도 초당 읽기/쓰기 200MB/160MB를 낼 수 있다고 주장합니다. 물론 그 결과는 제품 출하 후에 시장에서 판단하게 될 것입니다.

ExpressCard 형 SSD: 하드디스크 에물레이션 레이어가 필요없기 때문에 오버헤드 없이 고속으로 사용할 수 있으며 원하는 형태로 다양하게 만들 수 있다는 장점이 있습니다.

PCI-Express 형 SSD: 높은 버스 대역폭을 최대한으로 활용할 수 있어서 경이적인 속도를 낼 수 있는 제품입니다. 이런 높은 대역폭과 빠른 응답속도가 필요한 서버 분야에 채택되고 있습니다.
이미지 출처: http;//www.fusionio.com
실제로 2세대 제품들을 벤치마크 해보면 읽기 쓰기 속도에서 상당한 향상이 있음을 알 수 있습니다. 또한 4KB와 같은 작은 사이즈의 데이터 랜덤 쓰기에 대해서 내부적으로 특별한 처리를 함으로써 속도뿐만 아니라 IOPS에서도 뛰어난 성능이 나오도록 해 놓았습니다. 그러나 이런 장점에도 불구하고 속도만을 신경 쓴 제품들은 안정성에 심각한 문제를 가지고 있습니다. 우선 MLC를 사용한 제품은 사용 시간에 비례한 급격한 성능 저하, 원인을 알 수 없는 에러가 발생하고 있으며 리부팅 후 파일 시스템이 사라져 버리는 현상도 일어나고 있습니다.
하드디스크의 드럼에 비해 낸드 플래시의 셀들은 안정적이지 못합니다. 낸드플래시는 내부에 여분의 블럭을 내장하고 있으며 베드블럭이 발생했을 때 에러 난 블럭의 데이터를 읽어서 문제 없는 블럭으로 대피시켜서 에러를 감춥니다. 이런 내부 동작 때문에 바빠서 일시적으로 응답을 하지 않는 낸드 플래시가 있으면 그 순간 성능이 급격히 떨어지게 됩니다.
다수의 낸드 플래시를 관리하는 컨트롤러는 여러 가지 상황을 처리해야 하는데, 특히 데이터가 많아져서 낸드 플래시에 여분의 공간이 적어지고 디스크 단편화가 진행되면서 컨트롤러가 데이터를 여러 블럭에 나누어 저장해야 할 때 문제가 발생합니다.
현재와 같이 SSD 용량이 작은 상황에서는 대부분 SSD에 데이터를 거의 꽉 채운 상태로 쓰기 마련인데 이럴 때가 가장 심각한 상황입니다. 단편화된 파일시스템에 데이터 쓰기는 한 번에 여러 블럭에 걸친 쓰기가 필요해집니다. 블럭 방식 SSD는 다수의 블럭 단위 읽고 쓰기로 성능이 저하되며 페이지 방식 SSD는 쓰레기 수집에 많은 시간이 걸립니다.

성능 비교 그래프: 최대 대역폭이 높은 인텔 MLC SSD가 우수한 성능을 보입니다. 요청 데이터가 커질수록 대역폭 차이 만큼 성능이 우수하게 나타납니다.

인텔만의 그래프: 인텔 SSD만을 대상으로 테스트 한 결과입니다. 모든 결과에 대해서 우수한 성능을 내고 있습니다.
그러나 인텔 SSD를 포맷하고 마운트해서 파일을 꽉 채운 다음부터는 성능이 비정상적으로 나빠집니다. 이런 증상은 새로 포맷해도 개선되지 않습니다. 반복적으로 채우기 테스트를 하면 아예 죽어버려서 인식조차 되지 않습니다. 인텔에 문의한 결과 아직은 그 원인을 찾고 있다고 합니다.

최악의 상황에서의 테스트: 데이터를 꽉 채운 후에 테스트 하면 이전과 달리 상당한 성능 저하가 발생합니다. 특히 SSD 내부적으로 특별한 최적화로 성능을 끌어 올린 것으로 의심되는 랜덤쓰기에서 이런 현상이 심하게 나타나고 있습니다.
최적인 상황하에서의 테스트는 각 제품이 낼 수 있는 최대값을 얻을 수 있습니다. 하지만 실제 상황에서는 이런 식으로 사용되지 않습니다. 서버를 사용하다 보면 여러 가지 복잡한 이유로 최악의 상황에 처하게 됩니다. 이럴 때도 최선의 성능을 내줄 수 있는 제품이 필요합니다.
SSD에 4KB 파일을 채웁니다.
cp 4KB-file >a00001; cp 4KB-file >a0000N 무한 반복
이제 짝수 번째 파일을 지웁니다.
rm a00002 a0004…
SSD의 파일시스템은 4KB의 데이터와 4KB의 빈 공간이 교차하는 상태가 됩니다. 이렇게 이빨 빠진 상태에서 다시 7KB 파일을 채웁니다.
cp 7KB-file >b0001; cp 7KB-file >b000N 무한 반복
다시 짝수 번째 파일을 지웁니다.
rm b0002 b0004…
이제 파일시스템에서 연속된 빈 영역은 최대 4KB이며 대부분은 3KB, 2KB, 1KB짜리 조각들입니다. 이 상태에서 벤치마크를 실행합니다.

나빠진 랜덤 읽기: 이빨 빠진 상태에서는 랜덤 읽기도 성능이 극악으로 떨어집니다. 이렇게 특별한 최적화는 비정상 상황에서 문제를 일으킵니다.

파일 시스템 만들기 테스트: 리눅스 파일 시스템을 만들 때 작은 파일을 많이 생성하기 위해서 i-node 개수를 2000만개 생성하도록 합니다. 이 테스트는 작은 파일 생성에 대한 효율을 알 수 있는 또 다른 테스트입니다. 여러 업체가 작은 파일 쓰기에 최적화를 했지만 MLC의 특성을 완전히 감추지는 못했습니다. MLC는 이 테스트에서 낮은 성능을 보이고 있습니다.
서버에서는 최악의 상황에서도 기대치 이상의 성능을 내 줄 수 있는 제품이 필요합니다. 최대값이 아무리 높다고 해도 불안정하거나 로드가 심하게 걸리는 상황에서 정상 동작을 하지 못한다면 쓸모 없는 제품일 뿐입니다. 그럼에도 옥상 옥을 쌓듯이 이런 비정상 상황을 해결하기 위해 특별한 솔루션이 제안될 때도 있습니다.
SSD의 낮은 랜덤쓰기 성능을 외부 프로그램으로 해결할 수 있다는 주장이 있습니다. MFT(Managed Flash Technology) 프로그램이 그 것입니다. SSD 쓰기 요청을 가로채 SSD 특성에 맞게 블럭을 재조정함으로써 최대 성능을 내도록 해 준다고 합니다. 쓰기 최적화는 낸드 플래시의 수명도 늘여주는 효과까지 있다고 합니다. 실제로 사용해 보면 작은 파일 쓰기에 문제가 많은 MLC 버전 SSD에서 상당한 성능 향상을 얻을 수 있습니다.
그러나 MFT의 효과 대부분은 SSD만을 위한 전용의 버퍼캐시를 설정했기 때문에 생기는 것입니다. 작은 파일 쓰기가 많을 때 이 것들을 버퍼에 모았다가 한 번에 쓰기 때문에 생기는 향상입니다. MFT는 이를 위해서 SSD의 파일 시스템 페이지 재조정까지 감행하여 가능하면 작은 파일들이 SSD 쓰기 단위와 같은 크기의 블럭에 모이도록 설정합니다. 성능은 증가할지 모르지만 이런 이중의 개입은 또 다른 문제를 일으킵니다.
전원이 나가면 필요 이상으로 많이 설정된 버퍼캐시에 있던 데이터가 사라져서 파일 시스템 안정성에 문제가 발생합니다. 버퍼와 캐시를 무효화하도록 운영체계에 요청하여 직접 저장장치를 접근하는 데이터베이스 프로그램들은 그들이 예측한대로 시스템이 동작할 것이라고 믿고 데이터를 처리합니다. 그러나 버퍼 캐시 무효화 요청을 무시하고 독자적인 알고리즘에 따라 SSD를 처리하는 MFT가 중간에 끼여 있을 때 심각한 데이터 손상이 올 수 있습니다. 쓰기 성능을 올려 준다고 해서 이런 프로그램을 서버에서 사용해서는 안됩니다. 시스템의 안정성을 특별한 프로그램의 동작에 맡기는 행위는 결코 해서는 안 되는 일입니다.

MFT 테스트: 읽기와 쓰기를 4:1 비율로 테스트한 결과. 작은 블럭 읽고/쓰기에 대해서 성능 향상이 있습니다.
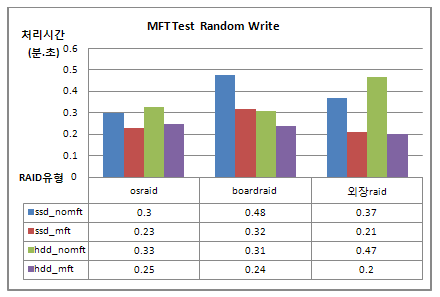
하드디스크와의 비교: SSD에 적용했을 때와 하드디스크에 적용했을 때의 성능 변화가 거의 비슷합니다. 이 것은 MFT가 버퍼 캐시를 활용한다는 것을 보여 주는 증거입니다.
최상의 조건에서 최대 성능을 뽐내는 제품들은 특별한 방식으로 최적화를 했기 때문에 상황이 나빠지면 마이너스 효과가 발생하게 됩니다. 안정성, 신뢰성등에 대한 기준을 중요시하지 않고 MLC와 SLC에 대한 차이에 눈을 감아서도 안됩니다. 아직 신뢰할 수 없는 MLC는 서버 스토리지 장치로 사용해서는 안됩니다. 특별한 외부 프로그램을 사용하여 성능을 올리면 돌발 상황에서 데이터의 손상이 생길 수 있습니다. 서버 스토리지를 위해서는 최악의 상황에서도 최선의 성능이 보장되는 제품을 사용해야 할 것입니다. 지금은 SLC 낸드 플래시를 사용한 SSD, 안정적인 컨트롤러가 장착된 SSD가 최선의 선택입니다.

JMicron SLC SSD: 저가형 MLC SSD 제품용 컨트롤러를 판매하는 JMicron의 평가 보드에 SLC를 붙인 테스트 제품. JMicron 컨트롤러 명세에 지원하는 SLC를 붙였으나 MLC에 비해 큰 성능 향상은 없습니다. JMicron 컨트롤러가 장착된 MLC SSD는 안정적이지 못합니다. 또한 컨트롤러 수준에서 최대 성능이 좋지 않기 때문에 SLC를 붙인 제품도 의미가 없습니다.
7.4 SSD의 특성과 적용 가능 서버
7.4.1 SSD의 쓰기 성능
리눅스 /usr 디렉토리에서 일부 하위 디렉토리를 지워서 1.5GB로 만듭니다. 파일 수는 55,000개인데 이 때 파일 평균 크기는 27.27KB가 됩니다. 이 데이터를 램디스크에 올린 다음 각각 SSD, SATA에 복사 테스트를 합니다.
cp –a /ramdisk/usr /ssd/usrN
이런 프로세스를 1개에서 128개까지 증가시키며 테스트를 진행합니다. 1개에 가까울수록 순차쓰기 성격이 높으며 128개에 가까울수록 랜덤쓰기에 가깝게 됩니다.

쓰기 성능 테스트: 각각 5개씩의 SSD, SATA로 구성된 레이드-0 모드 상태에서의 테스트. 동시 쓰기 프로세스가 적을 때는 레이드 효과를 볼 수 없어서 낮은 성능이 나옵니다. 최고 성능은 최대 대역폭의 영향을 받습니다. 일정 수 이상의 프로세스를 넘어가면 다른 부분의 오버헤드로 오히려 성능이 떨어지고 있습니다.
표에서 보듯이 SSD는 하드디스크에 비해 쓰기 성능이 크게 좋지 않습니다. 현재 시중에 나와 있는 SSD는 모두 마찬가지입니다. 동시에 다수의 프로세스가 데이터를 쓰게 되는 서버 쪽에서는 특히 큰 차이를 얻기 힘듭니다.
대용량 메일 서버는 엄청난 양의 메일을 주고 받는데 일단 보낼 메일 데이터를 큐에 쌓아 놓고 순차적으로 전송합니다. 부하가 많이 걸리면 메일 전송에 장애가 생기므로 큐를 효율적으로 관리해야 합니다.
생성하는 파일 수가 늘어나면서 파일 처리에 드는 오버헤드가 큰 비중을 차지 합니다. 현재는 큐에 너무 많은 메일이 쌓이지 않도록 부하가 늘어나면 메일 큐 전용 서버를 늘려서 문제를 해결하고 있습니다. 그러나 필요하다고 무한정으로 서버 수를 늘릴 수가 없습니다. 만약 하드디스크를 SSD로 대체하여 시간당 메일 처리 량을 높일 수 있다면 큐 서버를 줄일 수 있을 것입니다.
TCO 관점에서 관리해야 할 서버를 줄일 수 있다면 SSD를 사용하지 않을 이유가 없습니다. 또한 메일 데이터는 잠시 쓰였다가 전송 후에 사라지는 데이터이기 때문에 SSD가 에러가 생겨도 상관없습니다. 극단적으로 무책임하게 이야기하자면 메일은 기본적으로 복제 되어 보내지기 때문에 전송되지 않아도 상관없습니다. 꼭 필요한 메일이라면 다시 보내게 됩니다. 어쨌든 보낸 메일함에서 원본을 찾을 수 있으니까요.
SSD 적용 가능성을 보기 위해 대용량 메일 서버의 메일 큐 시물레이션 테스트를 합니다.
100만개의 File을 생성하는 Thread 10개를 실행합니다. 이 중 8개의 Thread는 10 Kbytes, 2개의 Thread는 100 Kbytes로 랜덤한 내용의 파일을 만듭니다. 한 편 생성된 파일을 리스팅하고 삭제하는 Process를 10개 동작시킵니다. 큐에 쌓는 프로세스와 메일을 전송하고 지우는 프로세스를 흉내 낸 것입니다.
SATA 하드디스크
|
수행시간 |
86분 57.52초 |
|
Load Average |
9.91 ~ 22.89 |
|
iowait |
2.50% ~ 15.88% |
|
CPU utilization |
40.14% ~ 96.20% |
|
Used memory |
1.4GB ~ 3.1GB |
SSD
|
수행시간 |
34분 26.12초 |
|
Load Average |
10.30 ~ 22.39 |
|
iowait |
1.56% ~ 9.75% |
|
CPU utilization |
23.10% ~ 91.99% |
|
Used memory |
2.3GB ~ 2.5GB |
전반적으로 SSD가 두배 정도 성능이 더 좋은 것으로 나왔습니다. 수행시간도 2배 정도 차이가 납니다. 그러나 SSD가격으로 비교해 볼 때 최소한 5~10배 정도는 차이가 나야 가격대 성능비로 따져서 채택할 만 합니다. 현재의 쓰기 성능으로는 이런 상황에 SSD를 도입할 이유가 없습니다.
SSD의 쓰기 성능은 하드디스크와 큰 차이가 없으므로 용량이 작고 가격이 비싼 SSD를 이런 응용에 쓸 이유가 없습니다. 더구나 아직은 안정성이 검증되지 않았기 때문에 쓰기 위주의 응용에 사용하는 것은 위험합니다. 차세대 SSD들의 쓰기 성능이 향상되고 안정성까지 검증된 이후에 다시 도입을 검토해도 늦지 않을 것입니다.
7.4.2 SSD의 읽기 성능
|
% of Access Specification |
Transfer Size Request |
% Reads |
% Random |
|
File Server Access Pattern (as defined by Intel) |
|
0.5 KBytes |
80% |
100% |
|
5% |
1 KBytes |
80% |
100% |
|
5% |
2 KBytes |
80% |
100% |
|
60% |
4 KBytes |
80% |
100% |
|
2% |
8 KBytes |
80% |
100% |
|
4% |
16 KBytes |
80% |
100% |
|
4% |
32 KBytes |
80% |
100% |
|
10% |
64 KBytes |
80% |
100% |
위의 표는 인텔이 규정한 서버 테스트 워크로드 중에서 파일서버 액세스 패턴입니다. 대부분의 테스트 프로그램은 이 값을 기준으로 서버를 비교 테스트합니다.
여기서 정의한 대로 테스트를 실시합니다. 다만 표에서는 읽기/쓰기 80/20 비율이지만 여기서는 읽기 100%로 했습니다.

파일서버 액세스 패턴 테스트: iometer를 사용한 테스트입니다. 8개의 하드디스크와 SSD를 각각 레이드-0로 두고 로드를 1에서 256까지 증가시키면서 읽기 속도를 테스트합니다. 프로세스가 1개 일 때는 순차 읽기 성격이 강하며 프로세스가 늘어날수록 랜덤 읽기 성격이 강합니다. 어떤 경우든 SSD는 하드디스크에 비해 경이적인 성능 향상이 있습니다.
지금까지의 오랜 테스트를 통해 SSD는 읽기 성능 특히 랜덤 읽기에서 탁월한 성능을 발휘한다는 것을 알고 계실 것으로 믿습니다. 서버에서의 모든 읽기는 랜덤 읽기라고 말할 수 있습니다. 순차 읽기 요청도 동시에 다량으로 처리되어야 하는 상황이므로 전체 읽기 요청을 스토리지 입장에서 보면 랜덤성이 강하기 때문입니다. 그러므로 읽기 전용 서버에 SSD를 도입하는 것은 최상의 선택이라고 말할 수 있습니다.
특히 SSD의 안정성 측면에서 볼 때 읽기 전용은 위험 부담이 적습니다. 물론 이중화를 해서 SSD의 에러에 대한 대책을 수립해 놓고 있어야 하지만 쓰기에 비해 읽기 안정성은 쉽게 확보할 수 있으므로 크게 걱정할 필요는 없습니다. 읽기 전용 서버에 SSD를 도입했을 때 어떤 성능 향상이 있는지 실전 테스트 결과를 놓고 이야기 해 보기로 합니다.
7.5 실제 파일 서버에 SSD를 도입하여 성능 개선 시키기

웹하드 서버: 24시간 데이터 전송을 하는 파일서버. 빈번한 읽기에 비하면 쓰기 동작은 거의 일어나지 않는다고 볼 수 있습니다.
인터넷에서 파일 서비스를 하는 서버들은 언제나 하드디스크가 병목입니다. 동시에 많은 사용자들이 접속하여 용량이 큰 파일 요청을 하면 하드디스크가 데이터를 보내 줄 때까지 각 프로세스들은 메모리를 차지한 상태에서 대기해야 합니다. CPU는 이런 프로세스들을 스케쥴링 하기 위해 타스크 스위칭에 대부분의 시간을 소모하게 됩니다. 로드가 걸릴수록 지연시간은 늘어나고 서비스 품질은 떨어지면서 서버가 응답조차 하지 않는 상황까지 가게 됩니다.
부하가 몰리는 시간 대에 운영팀들은 비상 대기를 하면서 필요한 조치를 즉각 취하는 형태로 유지 관리를 합니다. 어느 한 서버가 에러가 나면 다른 쪽으로 트래픽이 몰려 나머지 서버들도 차례로 죽기 때문에 서비스 품질이 급격히 떨어집니다. 업체들은 여러 가지 방법으로 최적화를 하고 성능과 안정성을 확보하려고 노력하지만 쉽지 않은 일입니다. 이런 분야에 SSD가 한가지 대안이 될 수 있습니다.
7.5.1 실제 서비스 하는 하드디스크 시스템의 성능
네트웍 스위치는 서버들이 네트웍으로 주고 받은 데이터량을 로그로 남겨 둡니다. 이 값을 받아서 그래프를 그릴 수 있는데 이것을 MRTG(Multi Router Traffic Grapher)라고 합니다. MRTG를 통해서 파일 서버의 네트웍 트래픽을 보면 그 서버의 서비스 상태 경과를 알 수 있습니다.

실제 네트웍 트래픽: 하드디스크를 장착한 파일 서버의 MRTG. 오후 2시에서 9시까지의 네트웍 트랙픽을 보여 주고 있습니다. 대충 300Mb/s에서 600Mb/s 사이의 속도로 서비스 했습니다. 최대 대역폭은 571.5Mb/s입니다.
7500rpm SATA 하드디스크 9개를 레이드-0 모드로 장착한 상태입니다. 메모리는 8G이며 1G 랜카드 2개를 본딩하여 최대 네트웍 대역폭이 2Gb/s인 상태입니다. 접속 사용자 비율과 그들의 서비스 품질은 다음과 같습니다.
600KB/s 정도의 속도인 ADSL 사용자 70명 : 182KB/s(평균 데이터 전송 속도)
6MB/s 정도인 라이트급 사용자 30명 : 746KB/s
60MB/s 정도인 광랜 사용자 27명 : 2539KB/s
이 때의 sar를 통해 본 시스템 정보는 다음과 같습니다.
|
Load Average |
69.81 ~ 112.87 |
|
iowait |
36.32% ~ 79.51% |
|
CPU utilization |
39.98% ~ 82.06% |
|
Used memory |
2.5GB ~ 4.3GB |
7.5.2 SSD서버의 성능
위와 같은 상황에서 SSD를 사용하면 상황이 어떻게 변하는지 알아봅니다.

SSD 서버 트래픽: 하드디스크 병목이 해소되어 최대 성능이 나왔습니다. 본딩한 네트웍 카드가 더 이상 성능을 낼 수 없어서 최대값이 제한되고 있습니다. 8개의 SSD를 레이드-0로 사용했으며 나머지는 하드디스크 서버와 같습니다. 이제 네트웍 카드의 병목을 제거하기 위해 1G 랜카드 4개를 본딩하여 테스트 합니다.
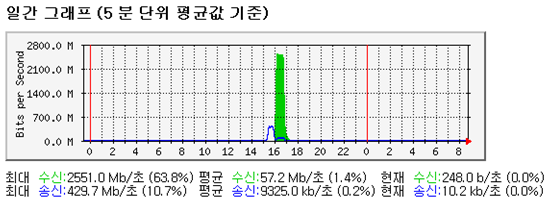
4G 네트웍 대역폭에서의 성능: 이 때의 SSD 서버의 최대값은 2551.0Mb/s 정도입니다.
하드디스크 서버와 같은 조건에서 SSD 서버가 낼 수 있는 성능은 최대값 기준으로 571.5Mb:2551.0Mb로 약 4.5배 정도의 성능 향상이 있다고 말할 수 있습니다.
7.5.3 SSD 서버의 스케줄링 제거 효과
4.5배 향상도 훌륭한 성능 개선입니다. 그러나 아직 여러 가지 튜닝 요소가 남아 있습니다. 위 결과들은 스케줄링 제거인 no-op 옵션을 사용하지 않은 것입니다. No-op를 적용한 상태에서 같은 테스트를 다시 했습니다.

No-op 결과: SSD서버는 하드디스크를 위한 스케줄링을 제거 했을 때 좀 더 높은 성능을 보이고 있습니다.
No-op를 사용했을 때(2784.0Mb/s)가 cfq 스케쥴러를 사용했을 때(2551.0Mb/s) 보다 좀 더 나은 성능이 나옵니다. 그러나 그렇게 큰 차이가 나지 않는 것처럼 보입니다. 이 것은 네트웍 카드 4개를 본딩해서 테스트 했기 때문입니다. 4G 채널 본딩을 했을 때 여러 가지 오버헤드로 인해 네트웍 카드가 낼 수 있는 최대 대역폭이 2.8G 정도에 불과하며 때문에 no-op의 효과가 크게 나타나지 않고 있습니다. 이를 해소하기 위해서 자체 컨트롤러를 가지고 있는 고속의 10Gb 랜카드를 사용하여 병목을 해소한 상태에서 테스트를 다시 했습니다.

10G 랜카드: TOE(TCP Offload Engine) 기능으로 서버에 부하를 주지 않으면서도 10Gb 속도를 제대로 내 줄 수 있는 제품. 아직은 아니지만 서버쪽을 시작으로 언젠가는PC까지 도달할 것으로 보이는 제품.

10Gb 랜카드를 사용한 결과: 최대값 6942.9Mb/s로 거의 7Gb에 육박한 속도가 나왔습니다.
이 때 sar를 이용한 서버 정보는 다음과 같습니다.
|
Load Average |
28.43 ~ 36.78 |
|
iowait |
13.85% ~ 14.29% |
|
CPU utilization |
78.06% ~ 98.60% |
|
Used memory |
1.3GB ~ 4.0GB |
병목이 될만한 요소를 제거하자 읽기 전용 서버로서의 SSD 서버의 진가가 드러납니다. 하드디스크 서버에 비해 경이적인 성능 향상이 있습니다. 그럼에도 오히려 시스템 부하는 더 줄어서 서버가 훨씬 원활하게 서비스 할 수 있는 상태입니다.
약 12배 정도의 성능 향상은 SSD와 하드디스크의 가격대 성능비를 따져도 SSD가 밀리지 않습니다. 더구나 SSD 서버 한 대 도입으로 12대의 하드디스크 서버를 줄일 수 있기 때문에 관리의 이점도 있습니다. 줄어드는 데이터 센터 공간 사용료 또한 무시하지 못할 요인입니다.
SSD를 도입한다면 최대 성능뿐만 아니라 각각의 커넥션에 대한 서비스 품질도 최대한으로 높일 수 있습니다. 그러므로SSD는 잘 튜닝된 형태의 읽기 전용 서버에 가장 적합한 솔루션입니다.
7.6 SSD: 진정한 캐시 서버의 구현
하드디스크의 느린 성능을 메우기 위해서 메모리를 통한 캐시가 있어왔지만 서버들 간에 이런 기능을 할 수 있는 것은 없었습니다. 캐시 서버라고 불리는 것들은 사용자가 많이 요청하는 데이타를 미리 찾아 놓거나 같은 데이터를 가진 서버를 여러 대 준비하여 부하를 분산하는 정도가 고작이었습니다. 캐시 서버들은 원본 데이터를 가진 서버에 비해 성능이 뛰어나지 않았기 때문에 L4 캐시 서버와 같이 데이터에 접근하는 경로를 줄여 주는 프락시 기능은 부하가 걸릴 때 전체 서비스를 마비시키기도 했습니다. 따지고 보면 여태까지 진정한 의미의 캐시 서버는 존재한 적이 없다고 말할 수 있습니다.

DRAM 고속 디스크: 캐시 서버로 초고속을 구현할 수 있는 메모리 디스크 드라이버. 월등한 성능은 진짜 캐시 서버의 능력을 발휘할 수 있지만 전원에 취약하고 고가이며 적은 용량으로 본격적으로 도입되기에는 무리가 있습니다.

캐시: 검색의 효율성을 높이기 위해서 사용자들이 많이 찾는 데이터는 이미 검색 결과가 만들어져 있습니다. 역으로 사람들은 남들이 많이 찾은 결과에 흥미를 느끼기 때문에 인기 데이터는 점점 더 많은 사람들이 찾게 됩니다.

포탈 첫 페이지 서버: 첫 페이지는 무조건 빨리 떠야 합니다. 이를 위해서 현재 모든 포탈들은 수십 대에서 수백 대의 첫 페이지 전용 서버를 갖추고 있습니다. 이들은 모두 같은 데이터를 가지고 있으며 검색이나 디렉토리 요청은 다른 서버에 넘김으로써 언제나 지연 없이 첫 페이지를 사용자들에게 보여줄 수 있습니다.
SSD를 도입함으로써 이제 진정한 캐싱을 구현할 수 있습니다. 가장 많이 요청하는 파일들 만을 모아서 SSD서버에 둘 수 있습니다. 하드디스크 서버에 비해 월등한 성능을 가지고 있기 때문에 한 대의 SSD 서버가 5~10배의 성능을 낼 수 있습니다. 고성능 SSD 서버에 인기 데이터를 몰아 버림으로써 원 데이터 서버들의 부하를 줄일 수 있습니다. 트래픽은 캐시 서버에 몰리니까 이들만 잘 관리하면 전체 시스템을 안정적으로 유지하기가 좀 더 쉬워집니다.
같은 데이터가 담긴 서버 수를 늘리는 캐싱에서 적은 수의 고성능 SSD 서버 캐싱으로 변경함으로써 유지 관리가 편해지고 비용이 줄어듭니다. 인기 데이터를 제거한 파일 서버들은 적정한 규모의 접속을 안정적으로 서비스 할 수 있습니다. 만약 갑자기 일반 파일 서버의 특정 파일에 대한 요청이 몰린다면 실시간으로 이 파일을 캐시 서버에 옮겨서 문제를 해결할 수 있습니다.

서비스 지연 시간의 해소: 한 포탈의 검색용 인덱스 데이터 갱신 상황에 대한 실제 그래프입니다. 사용자들이 요청한 검색은 인덱스 데이터를 통해 처리됩니다. 검색을 계속할수록 하드디스크에 있던 데이터가 메모리로 올라 오기 때문에 검색 응답 속도가 점차 빨라집니다. 그림에서 보듯이 20ms 정도였던 응답 속도가 시간이 지나면서 약 6~8ms 정도로 줄어든 후 안정됩니다. 새벽 4시경 새로운 인덱스 데이터로 갱신하고 데몬을 리스타트하면 서비스 응답 속도가 다시 느려진 후 그 상태가 오랫동안 지속됩니다.(그림의 녹색과 빨간색 그래프) 그러나 SSD 서버(노란색 그래프)는 전반적으로 빠른 응답 속도를 유지할 뿐만 아니라 인덱스 데이터 갱신 후에도 응답 속도 변화가 거의 없으며 신속하게 최상의 상태로 복귀함을 알 수 있습니다.

SSD 서버의 대역폭을 늘여서 성능을 높이기 위해서는 최소한 8개 이상의 SSD를 레이드로 묶어야 하며 가능하면 그보다 더 많이 쓰는 것이 좋습니다. 12개 이상의 SSD를 묶으면 10G 이상의 대역폭도 가능합니다.

안정적인 캐시 서버 구조:파일 서버들 앞에 캐시 서버 한 조를 구성하고 인기 데이타를 모아서 서비스 합니다. 캐시 서버의 안정성을 위해서는 한 개의 캐시 서버를 서비스 하지 않는 대기 상태로 두거나 두 서버의 부하를 50% 이하로 유지하는 방법을 써야 합니다. 만약 1개의 캐시 서버만 운영하다가 그 서버가 죽게 되면 뒤에 있는 파일 서버에 트래픽이 몰려 시스템 전체에 심각한 문제가 생길 수 있기 때문입니다.
SSD서버는 전원이 나간다고 데이터가 사라지지도 않으며 비슷한 하드웨어로도 하드디스크 서버에 비해 충분히 높은 성능을 낼 수 있습니다. 특히 어떤 것으로도 개선할 수 없었던 커넥션 각각의 서비스 품질 향상이 가능합니다. SSD는 진정한 캐시 서버를 위한 탁월한 선택입니다.
그러나 2008년 겨울, 또 다시 어려운 시간이 찾아 왔습니다. 모든 테스트를 완료하고 타겟 시장을 정했지만 갑자기 세상이 달라져 버렸습니다. 한 해 동안 이슈가 되던 SSD는 서버 업체들이 공황 상태에 빠짐으로써 적극적인 도입은 요원한 일이 되었습니다. 이런 때일수록 새로운 것에 대한 관심을 잃지 않아야 미래를 대비할 작은 희망을 가질 수 있을 것입니다.
그러나 현실의 어려움 때문에 아무도 이런 말에 귀 기울이지 않습니다. 산처럼 쌓인 SSD 테스트 결과는 휴지 조각이 되고 SSD를 위한 수 많은 튜닝 노하우는 쓸모 없는 지식에 불과하게 되었습니다. 앞으로의 전망도 어둡습니다. 불황에 더해서 극심한 경쟁까지 기다리고 있습니다. 아아 위태로운 SSD 비즈니스, 도대체 희망은 어디에 있는 것일까요?
김인성. | 





