|
이 글은 한빛미디어에 기고했던 글입니다. 시스템엔지니어에 대한 제 생각을 쓴 것입니다. 제가 쓴 글을 한 곳에 모아 놓을 필요가 있는 것 같아서 게시합니다.
시스템 엔지니어
필자는 리눅스 시스템 엔지니어이다.
현업에서 리눅스 시스템 엔지니어로 인정 받으려면 대개 팔방미인이어야 한다. 리눅스가 주로 인터넷 서버로 사용되기 때문에 서버/클라이언트 환경에서의 프로그래밍(C,C++ 또는 java)은 기본이다.
또한 아파치 등의 각종 데몬 컴파일, 최적화, 문제 해결 능력도 수행해야 하며, 서버 관리를 위해서 /etc 아래에 있는 기동 파일을 조작하기 위해서는 어느 정도의 셸스크립트에 대한 지식도 있어야 한다. 그에 따라 각종 필터 프로그램(grep, sed, awk등)을 사용할 줄 알아야 한다. 물론 간단한 작업을 손쉽게 처리하기 위해서는 익숙한 스크립트 언어(php, perl, tcl, python등)도 한 개 정도는 있어야 한다.
서버 프로그래머, 시스템 관리자, 시스템 엔지니어
유닉스 프로그래머는 php 등을 이용해서 웹 응용 프로그램을 작성하는 사람들, 한글 패치를 하는 사람들, 배포판 프로그래머 등이 있다. 물론 데몬 프로그래밍을 하는 프로그래머도 있고 리눅스를 임베디드 플랫폼에 포팅하는 경우도 있지만 한국에서는 손꼽을 정도다.
서버 프로그래머, 시스템 관리자, 시스템 엔지니어를 구별하는 요소는 간단히 말하자면 "문제 해결을 시스템적으로 생각하는가" 하는 여부의 차이라고 말할 수 있다. 이 글의 핵심은 바로 여기에 있다. 긴 글이지만 끝까지 읽어주기 바란다. 핵심은 뒤에 있기 때문이다.
적성에 맞다. 재미도 있다. 또한 수명도 길다
한국에서 소프트웨어 패키지로 성공한 업체는 거의 없다. 패키지가 아니라면 남는 것은 고객의 요구에 따라 부품 단위나 기능 단위의 소프트웨어 제작 용역인데, 마찬가지로 용역당 수익이 크기는 하지만 일년 단위로 나누어 보면 이익이 남지 않는다.
프로그래머라는 직업 자체도 수명이 짧다. 30대 후반이 되면 프로젝트 매니저를 하거나 경영 쪽으로 전향해야 하는데 두 가지 다 내가 원하는 것이 아니다. 하지만 시스템 엔지니어는 세월이 갈수록 오히려 그 가치가 증가한다. 60이 넘어서도 이 직업을 유지할 수 있을 것으로 생각한다.
시스템 엔지니어는 지휘자이다
시스템 엔지니어는 일부의 인식과 달리 프로그래머, 시스템 관리자의 다음 버전이다. 프로그래머가 만든 소프트웨어를 부품으로 사용하고 시스템 관리자가 맹신하는 소프트웨어 운영, 관리 매뉴얼의 수준을 넘어서야 한다. 거기에 매력이 있다.
특히 리눅스는 모든 소스가 공개되어 있어서 더욱 그렇다. 프로그램의 모든 옵션을 최대한으로 쥐어 짜내고 원하는 기능이 없으면 또 다른 소프트웨어로 대체하고 그래도 안되면 직접 소스를 고칠 수 있다. 프로그램을 조합하고 스크립트 언어로 이들을 엮어서 또 다른 기능을 만들어 낸다. 시스템 엔지니어는 거대한 서버 집단을 조화롭게 동작하도록 만드는 지휘자와 같다.
이 분야는 일정 정도 중독성이 있다. 나에게 이 일을 시작하게 된 동기는 담배를 피게 된 동기와 같이 들린다. 담배는 젊은 시절 언젠가 친구 앞에서 꿇리기 싫어서 피웠을 수도 있고, 멋있어 보여서 시작했을 수도 있지만 그 동기는 전혀 중요하지 않다. 결국은 끊고 싶어도 끊을 수 없도록 중독되기 마련이기 때문이다.
시스템 엔지니어도 마찬가지다. 어쩌다 서버들 간의 관계 설정, 최적화를 해야 했던 날이 있었고 이 것이 재미 있음을 발견하는 순간, 그 마력에 빠져 벗어나지 못하게 될 뿐이다. 오늘도 나는 "어떻게 하면 수백 대 리눅스 서버들의 커널 업그레이드를 자동화 할 수 있을 것인가?" 에 대해서 고민하고 있다.
재미 있는가? 재미 있다. 끝내주게.
전공과 나의 직업
컴퓨터 안에는 세상과 격리된 새로운 세상이 있다. 내가 지배하는 세상, 그 세상에 우연히 빠져 들었고 아직도 헤어나지 못하고 있다. 솔직하게 말해서 나는 컴퓨터 중독자다. 놀러 갈 때도 노트북을 가지고 가야 안심이 되고 술자리가 길어지면 노트북을 펼쳐 보고 싶은 생각이 더 간절해진다. 이런 심한 비유를 해도 되는지 모르겠지만 감옥에 가더라도 컴퓨터만 쓸 수 있다면 견딜 수 있을 것이다.
컴퓨터 안에 있는 세상은 언제나 조화롭다. 그러나 윈도우 세상은 별로 조화롭지 않다. 그래서 그런지 컴퓨터를 처음 시작할 때부터 도스 환경보다는 유닉스 환경이 좋았다. 또한 채팅도 별로 좋아 하지 않는다. 내가 지배하는 세상 건너편에 나의 즉각적인 반응을 요구하는 인간이 있다는 것이 마음에 들지 않았기 때문이다. 내가 지배하는 세상, 나는 이 것을 컴퓨터 속에서 찾았다.
컴퓨터 분야는 전공자와 비전공자의 차이가 별로 없는 것 같다. 기초 과학과 같이 반드시 알고 있어야 하는 근본 원리도 별로 없는 것 같고 항상 새로운 이론이 등장하기 때문이다. 자료구조나 알고리즘, 오토마타이론 등이 있기는 하지만 관련된 책을 쉽게 구해서 읽어 볼 수 있고, 대부분은 라이브러리에 최척화된 상태로 구현이 되어 있어서 가져다 쓰기만 하면 되고, 파서 등은 정규식만 제대로 만들면 전용 프로그램이 훌륭한 결과물을 만들어 주기 때문이다.
하지만 컴퓨터를 전공한 것이 빠른 이해에 도움이 되기는 한다. 학교에서 강제로 공부해야 했던 것들이 결국에는 기초를 이루게 하고 새로운 개념이나 방법론을 받아 들일 때 훌륭한 무기가 되기 때문이다. 독학으로는 얻기 힘든 이런 부분은 "배울 시기에 배워 놓은" 것의 장점을 보여 준다. 한국 축구의 고질적인 문제점처럼 개인기는 나이 들어서 습득하기 힘든 것이다.
시스템 엔지니어(SE)가 되고 싶은가?
필자는 SE로서 인터넷 업체를 지원하면서 어느 정도 엔지니어들 사이에서는 인정을 받고 있는 편이다. 대부분의 사이트에서 호소하는 웬만한 문제는 쉽게 해결할 수 있다.
문제 처리는 단순하다
필자가 문제를 처리하는 방식은 매우 단순하다. 시스템을 살펴보고 에러 메시지를 확인한다. /var/log/messages를 살펴본다. 또한 프로그램이 로그를 만든다면 대부분 로그에 에러의 원인이 나와 있다.
여기에 쓸만한 정보가 없으면 ps를 때리고 그 프로세스에 strace를 걸어서 시스템 콜이나 open하는 파일을 살펴 본다. 한 95% 정도는 이 단계에서 문제가 해결된다. 그래도 안되면 debug 위에서 프로그램을 돌린다. gdb 명령어는 복잡하지만 쓰는 것은 몇 개 되지 않는다.
이로써 99% 정도의 문제는 처리할 수 있다. 나머지는 대부분 시스템 설정의 문제이거나 방화벽 코드 이상, 옵션값 없음 등이다. 물론 성능 튜닝이나 구조 재설계 등이 필요한 경우도 있지만 크게 어려운 일이 아니다. 여태까지 시스템적인 문제에서 벽에 부딪힌 기억은 없다.
인터넷 업체 기술 지원을 시작하면서 나는 이런 해결책은 리눅스/유닉스를 사용하는 사람이면 누구나 다 할 수 있을 것으로 생각했다.
당구를 시작한 이유
필자는 대학 시절부터 당구를 쳤지만 큰 흥미를 느끼지 못했고, 친구들과 사교의 의미 밖에 두지 않았기에 현재 120에 머무르고 있다. 배울 때 배우지 않은 탓일까?
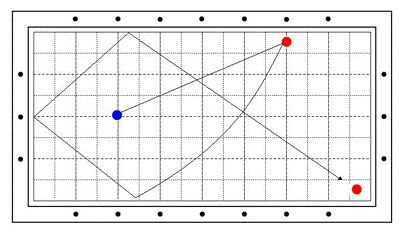
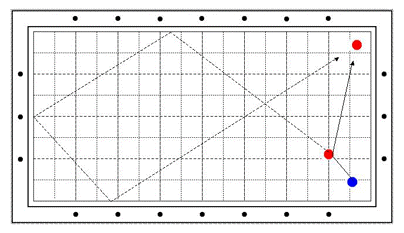
[그림 1] 예술구 대회 11점 문제 : 당구 집대성, p247, 로버트 바이런, 박용수 번역, 오성 출판사, 1993
[그림1]은 세계 예술구 대회에서 가장 고난도로 치는 11점을 획득할 수 있는 문제이다. 극심한 끌어치기를 해야 한다. 공은 첫번째 적구까지 미끌어진 다음, 그 공에 부딪힌 후 뒤로 끌리며 휘어져 첫번째 긴 쿠션을 맞는다. 그 다음부터는 회전력으로 굴러서 건너편 구석까지 가야 한다. 강력한 스트로크, 끝까지 살아 있는 회전이 생명이다.
자, 독자 여러분도 이제 이 문제를 알았으니 예술구 대회를 나갈 수 있을 것이다. 나머지 허접한 1-2 점짜리는 [그림1]의 참고 도서에 자세한 그림이 다 나오니 연습하면 익힐 수 있다. 더구나 예술구 대회는 3번까지 같은 공을 시도할 수 있다지 않은가!
허접하게 왜 당구 이야기를 하는 것일까? 개구리 올챙이적 시절을 기억하지 못하기에 필자의 SE에 대한 이야기는 현재로 과거를 날조하는 성공담 밖에 되지 않는다. 그 보다는 당구 이야기가 훨씬 설득력이 있기 때문이다.
당구의 달인들에게 [그림1]의 공을 어떻게 치면 되는지 물어보면 "잘 치면 된다" 라고 답할 것이다. 물론 나에게 어떻게 하면 좋은 SE가 될 수 있는지 물어 보면 이렇게 대답할 것이다. "잘--"
시스템을 버려라
당구에는 여러 가지 시스템이 있다. 대표적인 것이 [그림 2]에 나오는 파이브앤하프 시스템이고 이를 보완한 플러스투 시스템, 맥시멈 잉글리시 시스템, 노잉글리시 시스템 등이 있다. 물론 스리온투 시스템이니 리버스 시스템이니 하는 것도 있고 고수들은 자신만의 시스템을 가지고 있기도 하다.
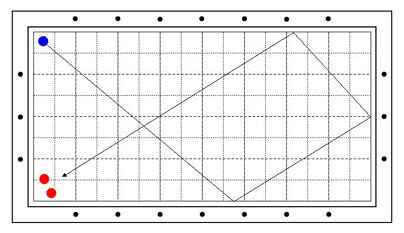
[그림 2] 파이브엔하프 시스템 : 아카데미 4구 p207, 손형복, 삼호 미디어, 1997
사실 이런 시스템을 전혀 몰라도 당구는 칠 수 있다. 사실 고수가 된 사람들 중에는 처음부터 시스템을 무시한 사람도 많다. 중요한 것은 시스템을 알든 모르든 고수가 되고 나면 시스템을 버린다는 사실이다. 시스템을 잊어야 진정한 고수가 되는 것이다. 때문에 우리가 첫번째 쿠션의 포인트로 2.3에 보내야 하는지 3.1에 보내야 하는 지 물어도 고수들은 답을 할 수 없는 것이다. 정답은 "대충 보내면 된다".
필자 같은 당구 초보자는 항상 이 시스템을 적용해 보고자 노력한다. 당구는 당점, 회전, 치는 속도, 칠 때의 큐 동작에 따라 다양한 결과가 나오기 때문에 아무리 시스템을 적용해서 첫번째 쿠션의 2.3에 보내도 공이 맞지 않는 경우가 많다.
초보와 고수의 차이
초보자와 고수의 차이는 이런 곳에 있지 않다. 양귀문의 당구 교실 비디오에 보면 밀어치기, 중앙치기, 끌어치기를 설명하는 부분이 있다. 놀랍게도 양귀문씨가 직접 치는 부분에서 밀어치기를 한 공은 적구가 돌아와서 정확하게 다시 맞고, 중앙치기를 한 공은 제자리에 머물러 있고 적구가 다시 와서 이 공을 쳤고, 끌어치기를 한 공은 적구가 돌아 올 동안 짧은 쿠션을 맞고 올라가 적구와 정확하게 부딪혔다. 스트로크가 정확했기 때문에 공들이 휘어지지 않고 직선으로 움직였기 때문에 가능한 일이었다.
[그림 3] 기본 공치기 : 양귀문의 당구 교실(비디오) : 양귀문, 비엠코리아, 1993
바로 고수와 초보자의 차이는 얼마나 정확한 스트로크를 하는가에 달린 것이다. 서초동에 있는 아카데미 당구교실에서 300점이 되기 전까지는 시스템, 포지션 플레이 등을 가르치는데, 그 이상의 고수가 되고자 하면 비디오 카메라를 사용하여 스트로크 자세를 고치는 일부터 다시 한다고 한다.
SE로서 가장 중요한 기초가 무엇인가를 나에게 묻는다면 나는 셸스크립트라고 대답할 것이다. 수많은 컴파일 언어, 스크립트 언어가 있지만 가장 중요한 것은 셸스크립트라고 나는 자신할 수 있다. 고수가 되고 싶은가? 셸스크립트를 익혀라.
리눅스 시스템의 대부분의 동작은 셸스크립트로 이루어져 있다. /usr/bin에는 수많은 셸스크립트가 존재한다. 시스템 기동 스크립트는 모두 셸스크립트로 짜여져 있다. 셸스크립트를 이해하지 않고는 시스템에 접근할 수 없다.
왜 셸스크립트가 중요한가?
사실 셸스크립트 문법은 매우 단순하다. 몇 가지 자료형과 몇 가지 제어문 밖에 없다. 그런데 왜 셸스크립트가 중요한 것일까?
유닉스는 "작은 것이 아름다운" 전통 때문에 /usr/bin에 있는 대부분의 프로그램이 단순한 동작밖에 할 수 없도록 되어 있다. 그러나 이들은 표준 입력과 표준 출력을 재지정할 수 있도록 되어 있고 시스템에서 파이프를 지원하기 때문에 프로그램의 조합이 가능하다. 셸스크립트를 한다는 것은 이런 단위 프로그램을 조합하여 내가 원하는 작업을 처리한다는 뜻이다. 즉 셸스크립트의 미약한 성능 때문에 오히려 전통적인 유닉스 필터 프로그램에 대한 지식을 넓힐 수 있게 되는 것이다.
파일 소팅이 필요한가? sort를 사용하라. sort는 수십 년간 다듬어져 왔으면 최신 정렬 이론이 그대로 구현되어 있다. 당신이 아무리 뛰어난 프로그래머라도 유닉스의 sort보다 더 뛰어난 소팅 프로그램을 만들 수 없다. 아니다. 잘못 말했을 수도 있다. 당신이 매우 훌륭한 프로그래머라서 더 좋은 프로그램을 만들 수 있을지도 모른다. 하지만 왜 바퀴를 새로 개발하려고 하는가? sort 프로그램을 그냥 사용하면 되는데,,,
유닉스 필터 프로그램의 정확한 사용법과 활용법을 익히는 것은 당구의 스트로크를 연습하는 것과 같다. ls에도 수많은 옵션이 있다. 나는 지금 옵션을 외우라고 말하고 있는 것이 아니다. 필터 프로그램의 사용법을 한 번은 보고 실행해서 그 결과를 알고 있어야 한다는 뜻이다.
안정된 자세와 정확한 스크로크는 하루 아침에 이루어지지 않는다. 정확한 스트로크를 익히는 것은 몸이 그 동작을 기억하도록 하는 시간의 함수이다. 반복, 또 반복을 거듭해서 어떤 상황에서라도 안정된 스트로크를 구사할 줄 알아야 실력이 느는 법이다.
apache, mysql, samba, bind, sendmail, inet, nfs 등에 관한 경험은 그 다음이다. 마치 [그림 4]의 공모으기를 위해서 제1적구를 두껍게 치고 수구에 오른쪽 회전을 줘서 제1적구가 왼쪽 회전으로 돌아 오도록 세게 쳐야 한다는 것을 알게 되는 것과 같다. 스트로크가 안정되어 있지 않다면 이런 지식을 가지고 있어도 실전에서는 제2적구가 맞지 않을까 두려워 대부분 수구를 살짝 굴려 우선 한 개 치는 것에 급급하게 된다.
[그림 4] 공모으기 : 당구 매니아 64p, 최명호, 일신서적출판사, 2000년
몸에 익히는 기술은 세월이 필요하지만 익힐수록 더 쉬워지고 세월이 가도 잊어 먹지 않으며 고급 기술을 익히는 데 남들보다 더 적은 시간이 필요하게 되며 새로운 상황에 대응하는 능력이 길러진다. 소위 각조립이 가능한 것이다. 초구 끌어치기, 밀어치기 3쿠션도 이 단계에서는 더 이상 엽기가 아니다.
셸스크립트를 사용하면서 /usr/bin의 필터 프로그램을 익혀 놓으면 웬만한 문제는 필터 프로그램으로 해결 가능하다. 이런 단계에 다달았다면 필터 프로그램에 없는 기능을 스스로 만들어도 된다. 원하는 기능이 필터 프로그램들에 없다는 확신을 가질 수 있을 정도의 수준이 되기 위해서는 수많은 세월이 필요하겠지만.
유닉스 전통을 역행하고 있는 펄을 사용한다면 이 모든 작업에 펄을 사용 할 수 있다. 하지만 내가 원하는 모듈이 없을 때 필연적으로 상상력에 제약을 받을 수 밖에 없다. 원하는 기능을 하는 모듈이 나올 때까지 기다리든지 내가 직접 만들어야 한다. 이 문제는 최근에 유행하는 파이썬도 마찬가지다.
SE는 시스템에 대한 지식을 가지고 있어야 하는데 시스템에 대한 지식이란 다양한 프로그램에 대한 사용 경험에서 나온다. 물론 스크립트 언어도 사용할 줄 알아야 하지만 셸스크립트를 잘 쓸 줄 모른다면 아무리 훌륭한 스크립트 언어라도 SE를 가두는 감옥일 뿐이다.
필자는 시간이 있을 때 /usr/bin에 가서 ls를 치는 취미가 있다. 적지 않은 세월 동안 리눅스를 사용했지만 아직도 /usr/bin에는 내가 모르는 프로그램이 더 많다. 그 안에 있는 셸스크립트 프로그램을 뒤져 보면서 필터 프로그램의 또 다른 활용법에 감탄하고는 한다. 고수가 되고 싶은가? 셸스크립트를 익혀라.
시스템적으로 생각하자
리눅스에 대한 경험이 많다면 리눅스 시스템을 거대한 필터 프로그램의 조합이라고 생각할 수 있게 될 것이다. 웬만한 문제는 몇 개의 프로그램 조합과 셸스크립트로 해결할 수 있다.
기존 프로그램과 언어를 활용하자
두 개의 웹 서버에 생기는 아파치 로그를 한 서버로 옮겨서 분석을 하고 싶다고 하자. 아파치에는 로그를 syslog로 보내는 기능이 있다. 이렇게 해서 syslog의 원격 전송 기능을 활용하면 두 서버의 로그를 syslog를 통해서 받을 수 있다. syslog는 UDP를 사용하는데 부하가 걸리면 소실되는 부분이 생긴다. C로 소켓을 이용해서 TCP 전송을 하게 하면 아파치가 로그 전송을 위해서 대기하기 때문에 웹 서버 성능이 급격하게 떨어진다.
최종적으로 가장 효과적인 방법은 지정 시간마다 아파치 로그 파일을 아파치에서 분리하고(USR1 시그널 이용) rsync를 사용해서 전송하는 것이다. rsync는 어떤 프로그램보다 원격 데이터 전송에 효율적이고 아파치는 로그 전송에 신경 쓸 필요도 없기 때문에 성능 감소가 없다. 이 과정에서 스크립트 언어를 사용하여 소켓 프로그래밍을 하고 분리한 아파치 로그를 전송하는 간단한 네트워크 파일 전송 서버/클라이언트 데몬을 만들 생각을 할 수도 있겠지만 개발에 편자일 뿐이다.
당신이 어떻게 만들어도 rsync의 능력을 뛰어 넘기 힘들고 시간비용이 너무 크다. rsync를 사용하면 된다는 생각을 해내는 것이 바로 시스템적으로 생각하기의 전형이다. 새로운 프로그램을 만들지 않고 기존 프로그램의 기능을 활용하고 여기에 부수적인 시스템 동작 방식을 조립하여(아파치에 USR1 시그널을 날려 로그 분리해 내기) 문제를 해결한다.
다시 로그를 생각해 보자. 두 개의 시스템에서 로그를 보내 왔는데 이들을 합쳐서 분석하고 싶다. 분석 프로그램이 각각의 로그라인의 시간을 읽어 들여서 이들 시간을 기록해 놓았다가 처리하면 될 것이다. 즉 a 서버의 로그를 모두 읽어서 시간 배열(혹은 연결리스트)을 만들어 내고 두번째 b 서버의 로그를 읽어서 각각 라인의 시간값을 읽어서 시간 배열의 적절한 위치에 삽입해서 처리한다고 생각하고 프로그램을 작성하면 된다.
물론 적절한 위치를 찾기 위해서 프로그래밍을 해야 하는데 당연히 sort보다 느릴 것이다. 또한 전송 과정에서 잘못되어 무한히 긴 라인이 들어왔다든지, 처리의 기준이 되는 시간 데이터 형식이 잘못되었다든지, 웹 서버가 동작 중에 재부팅했고 바이오스 시간이 잘못되어 있어서 로그의 시작에는 오늘 날짜로, 재부팅한 중간 지점에는 어제 날짜로 바뀌어 날아왔다든지 하는 문제를 해결하기 위해서는 수많은 경우에 대처할 수 있도록 코드를 작성해야 한다.
문제 처리 시간은 점점 늘어나고 해결책은 점점 멀어지고 성능을 위해서 다시 알고리즘 책을 들여다 보게 된다. 프로그래머적인 관점에서 문제를 해결한다는 것은 때로는 문제 해결을 복잡하게 만들고 더 어려운 길로 가면서 지엽적인 부분에 얽매이는 경향이 있다.
신뢰할 수 있는 기초 작업 후에 필요 작업을 찾자
시스템 엔지니어는 어떤 경우에도 "반드시 생각대로 동작할 것"이라고 가정해서는 안된다. 시스템은 언제나 시간이 잘못될 수 있다. ntp를 사용하여 시간을 정확하게 맞추고 있었더라도 시스템 시간이 항상 정상일 것이라고 생각해서는 안된다. 시간을 보내 주는 타임 서버가 비정상적으로 동작할 수도 있다. 때문에 시간을 가져오는 서버를 여러 개로 설정해서 문제를 해결했다고 생각해서도 안된다. 모든 타임 서버가 잘못될 수도 있기 때문이다.
사실 지금 필자가 말하고 있는 사항들은 실제로 필드에서 겪었던 일들이다. 필자도 모든 부분에서 완전한 해결책은 하나도 가지고 있지 않다. 다만 가능한 모든 사항에 대한 고려를 함으로써 에러 발생률을 최소한으로 줄일 수 있을 뿐이다. 시스템은 원래 그렇다.
예를 통해 살펴보자. 아파치에 부하가 걸리면 로그에 쓰레기 값을 적는 경우가 발생한다. 그러므로 날아온 로그를 처리하기 전에 다음과 같은 코드를 사용하여 로그를 유효한 데이터로 변환시켜야 한다.
[아파치 로그 형태(combined 포맷)]
211.178.82.98 - - [01/Jan/2001:01:01:01 +0900] "GET /img2/today_eval_small.gif
HTTP/1.1" 200 - "http://a.com/" "Mozilla/4.0 (compatible; MSIE 5.0; Windows 98;
DigExt; Hotbar 2.0)"
grep "^[0-9]*.[0-9]*.[0-9]*.[0-9]*" | \
grep "\[[0-9][0-9]/[A-Z][a-z][a-z]/[0-9][0-9][0-9][0-9]:[0-9][0-9]:[0-9][0-9]:[0-9][0-9] \
[+-]*[0-9][0-9][0-9][0-9]]" > ${LOG_FILE.NORMAL}
물론 이렇게 걸러내도 무의미한 라인이 100% 걸러지는 것은 아니다. 하지만 99%는 확신할 수 있으므로 그 다음 단계로 넘어 갈 수 있다.
로그 분석을 위한 프로그램은 어떤 것이라도 상관없다. 상용일 수도 있고 오픈 소스일 수도 있다. 이들은 NCSA에서 정한 공통 로그 포맷을 사용하므로 이 포맷으로 된 한 개의 소팅된 로그 파일을 만들어 내기만 하면 된다. 프로그램 자체에서 로그를 소팅하는 일은 무의미한 시간 낭비일 뿐이다. 때문에 sort 필터를 사용하기로 하자.
날아온 로그 파일을 cat *.log > log.total 로 통합하고 sort 프로그램을 돌리면 된다. 문제는 sort 프로그램은 한 개의 필드 구분자(FS)를 사용한다는 것이다. 또한 아파치 로그의 시간 포맷이 소팅하기에 그렇게 적절한 형태가 아니다.
Perl 등의 소트 함수도 마찬가지이다. sort 프로그램의 소스가 있으므로 FS를 여러 개 쓸 수 있도록 만들기 위해서 뒤져 보았는데 효율성을 위해서 엄청나게 복잡하게 짜여져 있어서 고치는데 많은 시간이 들 것으로 판단되었다. 더구나 sort 프로그램이 업그레이드 되면 또다시 업그레이드 된 sort에 맞게 패치해야 하고 다른 시스템에 동작하게 할 때 변경된 GNU sort를 포팅해야 하는 문제가 발생한다.
가장 간단히 문제를 해결하는 방법은? sort가 원하는 형태로 데이터를 변환하는 간단한 프로그램을 만들면 된다. 파일을 읽어서 첫번째 "["를 "/"로 바꾸고 둘째 "/" 세째 "/"를 카운트 한 후에 그 다음에 나오는 ":"를 모두 "/"로 바꾸면 된다. 이렇게 바꾸고 나면 다음과 같다.
211.178.82.98 - - /01/Jan/2001/01/01/01 +0900] "GET /img2/today_eval_small.gif
HTTP/1.1" 200 - "http://a.com/" "Mozilla/4.0 (compatible; MSIE 5.0; Windows 98;
DigExt; Hotbar 2.0)"
sort 프로그램은 이제 "/"를 단 한개의 필드 구분자로 인식하여 2,3,4,5,6,7 번째 필드를 기준으로 소팅을 할 수 있다. 소팅 루틴은 다음과 같을 것이다(sort의 플래그는 매뉴얼 페이지를 참고 할 것).
sort -T ${LOG_DIR} -t / -k 4n -k 3M -k 2n -k 5n -k 6n -k 7n < ${LOG_INPUT} > ${LOG_OUTPUT}
결과물을 다시 공통 로그 포맷으로 바꾸기 위해서는 "/"를 "["와 ":"로 역변환 해주면 된다.
그 외 로그 파일의 시간처리 문제, 일정 시점에서 로그를 보내지 않은 시스템의 로그를 대기해야 하는 문제등의 복잡한 상황이 발생한다. 시스템은 항상 불안정하고 모든 동작은 시간의 함수와 상관관계가 있다. 지정된 시간에 발생해야 하는 사건이 발생하지 않았을 때 단순히 기다릴 수도 없고 무시할 수도 없다.
예를 들어 1시에서 2시까지 정상 동작하던 웹 서버가 2시 5분에 죽었다가 2시 10분에 살아 났다고 할 때, 로그 처리 서버가 2시 6분에 로그 전송 여부를 검사하는 루틴에서 전송되지 않은 서버를 무시할 수 없다. 한 시간 분량의 유효한 로그를 처리하지 않는다면, 그날 페이지뷰가 정확해지지 않기 때문이다. 그렇다고 무한히 기다릴 수도 없다. 로그가 올 때까지 기다렸을 경우 금요일 저녁에 관리자가 퇴근하여 월요일 아침에 출근할 때까지 시스템에 쌓인 로그가 파일 시스템을 다 채울 수 있기 때문이다. 이와 같이 시스템 동작과 정확한 로그데이터 처리 사이의 상관관계를 고려한다면 문제가 복잡해지지 않을 수 없다.
이런 복잡한 얘기를 계속하는데 질렸을 독자를 위해 결과 스크립트의 일부를 보여 주겠다.
###################################################
#
# 이런 복잡한 내용은 몰라도 된다. 코드 부분은 패스 하시길.
#
#
# 모든 웹 서버가 로그를 보냈는지 체크
LOG_COMPLETE=1
check_log $*
# 로그를 안 보낸 서버가 있을 경우 처리를 유보한다.
if [ ${LOG_COMPLETE} -eq 0 -a ${CHECK_FORCE} -ne 1 ]; then
return
fi
# 임시 파일을 지운다.
rm -f ${LOG_TOTAL} ${LOG_TOTAL_TMP} ${LOG_EARLY} 2>/dev/null
# 웹 서버가 보낸 로그를 모은다.
if [ $# -eq 1 ]; then
LOG_SERVER_NUMBER_IS_ONE=1
treat_this_log $1
else
LOG_SERVER_NUMBER_IS_ONE=0
while [ $# -ne 0 ]; do
treat_this_log $1
shift
done
fi
# 합쳐진 로그 파일이 없으면 실행을 중단한다.
if [ ! -s ${LOG_TOTAL} ]; then
rm ${LOG_TOTAL} 2>/dev/null
return
fi
# 지난 번 시점에 공통 부분보다 시간이 나중이었던 로그를 합친다.
cat ${LOG_LAST} >> ${LOG_TOTAL} 2>/dev/null
#########################################################
# 각 서버의 최종 시간 중에서 가장 빠른 로그 한 줄을 추출한다.
#
rm -f postsort.tmp presort.tmp 2>/dev/null
LOG_EARLY_INSTANCE=""
if [ -s ${LOG_EARLY} ]; then
if [ ${IS_TOTAL} -ne 1 -a ${IS_UP} -ne 1 ]; then
presort ${LOG_EARLY}
fi
sort -T ${LOG_DIR} -t / -k 4n -k 3M -k 2n -k 5n -k 6n -k 7n < ${LOG_EARLY} > ${LOG_EARLY}.tmp
mv ${LOG_EARLY}.tmp ${LOG_EARLY}
LOG_EARLY_INSTANCE=$(head -n 1 ${LOG_EARLY}|cut -b1-49)
rm -f ${LOG_EARLY}
fi
#########################################################
# 공통 시간의 최종 시간을 추출하여 이전 로그만 처리한다.
# 뒷부분은 다음 처리 시점에 합치게 된다.
#
rm -f postsort.tmp presort.tmp 2>/dev/null
if [ ${IS_TOTAL} -ne 1 -a ${IS_UP} -ne 1 ]; then
presort ${LOG_TOTAL}
fi
sort -T ${LOG_DIR} -t / -k 4n -k 3M -k 2n -k 5n -k 6n -k 7n < ${LOG_TOTAL} > ${LOG_TOTAL_TMP}
if [ "${LOG_EARLY_INSTANCE}" != "" ]; then
TOTAL_LINE_NUM=$(wc ${LOG_TOTAL_TMP} |awk '{print $1}')
LINE_NUM=$(grep -n -F -a "${LOG_EARLY_INSTANCE}" ${LOG_TOTAL_TMP} |awk -F: '{print $1}' |head -n 1)
head -n ${LINE_NUM} ${LOG_TOTAL_TMP} > ${LOG_TOTAL}
tail -n $(( $TOTAL_LINE_NUM - $LINE_NUM )) ${LOG_TOTAL_TMP} >${LOG_LAST}
if [ ${IS_TOTAL} -ne 1 -a ${IS_UP} -ne 1 ]; then
postsort ${LOG_LAST} ${LOG_LAST}.tmp
mv ${LOG_LAST}.tmp ${LOG_LAST}
fi
mv ${LOG_TOTAL} ${LOG_TOTAL_TMP}
fi
if [ ${IS_TOTAL} -ne 1 ]; then
cp ${LOG_TOTAL_TMP} ${LOG_UP}/access.${LOG_HOSTNAME}.$(date +%Y%m%d%H%M)
fi
postsort ${LOG_TOTAL_TMP} ${LOG_TOTAL}
##############################################
참고로 이 스크립트는 현재 하루 페이지뷰 1300만 정도인 사이트의 100여대 웹 서버에서 보내오는 로그를 1시간 단위로 처리하고 있다. 스크립트의 길이는 600여 라인 정도 되는데 설명과 공백을 빼면 500라인 조금 못된다.
또한 이 스크립트는 사이트의 요구에 따라 subsub1.com, subsub2.com, subsub3.com, subsub4.com 각각의 페이지 통계 처리를 하고 다시 각각의 결과 로그를 통합해서 sub1.com, sub2.com 에 대한 페이지 통계를 만들어 낸 다음, total.com 이라는 회사 전체의 모든 통계를 만들어 낸다.
즉 subsub1.com에서 작업하는 사람들은 subsub1.com에 대한 히트카운트, 페이지뷰를 볼 수 있으며 subsub1.com, subsub2.com 둘 다 관련된 사람들은 sub1.com의 통계를 보면 되고 회사 전체의 페이지뷰에 관심 있는 사람들은 total.com의 페이지뷰를 볼 수 있도록 되어 있다.
예를 들고 보여준 모든 로그와 프로그램에서 특정 회사와 관련된 부분과 시간 값은 중립적인 값으로 변경한 점도 말해둔다.
시스템적으로 생각하기가 무엇인지 알기 위해 너무 복잡한 이야기를 한 것 같다. 간단히 정리하면 다음과 같다.
큰 작업을 위해 훌륭한 언어가 필요한 것은 아니다.
모든 것을 개발할 필요는 없다. 리눅스는 거대한 필터 프로그램의 집합이며 가능한 이미 발명된 바퀴를 굴려서 문제를 해결할 수 있다.
시스템이 불변의 어떤 것을 제공할 것이라고 믿어서도 안된다.
항상 신뢰할 수 있을 정도의 기초 작업을 한 후에 필요한 작업을 진행하도록 해야 한다.
변경은 최소화 하는 것이 좋다.
현재의 특정한 상황만을 고려하여 작업을 한다면(sort 소스 고치기와 같은) 나중에 더 많은 시간을 투여해서 또 다른 상황에 맞추는 작업을 해야 할 수도 있다. 변경은 최소화하고 어디서나 사용 가능한 상태로 문제를 해결하는 것이 가장 좋은 방법이다.
무의미한 것에 답이 있다
어느 날 당구 아카데미에서 혼자 연습하고 있는 양귀문씨를 본 적이 있다. 대부분의 공을 맞추었지만 내가 잘치는 공을 못치는 경우도 있었다. 연습 중이어서 그랬는지 자세도 대충 잡고 치기도 했다. 나는 그 모습을 보면서 고수 혹은 도통한 사람들의 일반적인 모습이 이럴 것이라고 생각했다. 시스템을 익히고 나면 시스템을 버리고 스트로크를 몸에 익히고 나면 스트로크의 자세까지 버리는 모습. 고수가 되면 오히려 더 평범한 모습을 띄게 되는 것이다.
80/20 이론이란 것이 있다. 사회 인구의 20%가 부의 80%를 차치하고, 회사 인력의 20%가 80%의 수익을 발생시킨다는 이론이다. 이 이론을 책으로 낸 저자는 대학 시절 교과서의 20% 부분만 공부해서 80 점 이상을 받아 냈다고 자랑하고 있다. 필자도 점수의 80%는 고작 20% 정도의 기본 공 형태에서 얻고 내가 치는 차례의 80%는 점수를 못내고 있다는 것을 알고 있다. 또한 일반적으로 잘 나오는 형태의 공을 몇 개만 집중적으로 연습하면 금방 200 이상을 칠 수 있음을 알고 있다.
그러나 이 이론은 진정한 고수가 되는 방법에 대한 통찰력은 없는 듯하다. 실생활에서 충분히 응용할 수 있는 이론이지만 모든 것을 경험한 사람에게서 느낄 수 있는 인간의 깊이라는 부분이 빠져 있는 것이다.
고수가 되기 위해서는 비록 외우지는 못하더라도 시간을 내서 ls의 모든 옵션은 살펴 볼 필요가 있다. 처음부터 이럴 필요는 없다. 하지만 당신이 여러 해 동안 노력했음에도 실력에 변화가 없을 때 혹시 알고 있는 것만을 알고 있고, 사용하던 것만을 사용하고 있는 것은 아닌지 의심해 보아야 한다. 필요 없다고 무시했던, 80%에 속한, 무의미한 것이라고 간과하고 있었던 것에서 진짜 답이 있을 수 있기 때문이다.
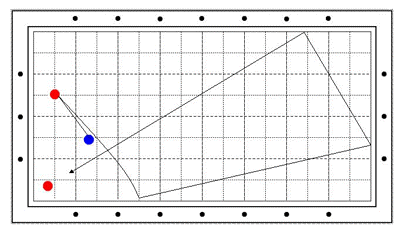
[그림 5] 스트로크 연습용 끌어치기 : 김인성
필자는 [그림 5]와 같은 끌어치기 쓰리쿠션을 자주 연습한다. 이 공을 연습하는 동안 스트로크에 대한 감을 잡을 수 있기 때문이다. 하지만 오늘도 친구와 당구를 쳤는데 2패였다. 현재 필자의 구력은 170점 정도 된다. 잘 칠 때는 200과 같이 치고 보통 때는 150정도이므로 올릴 수도 그대로 있을 수도 없어서 이렇게 생각하고 당구를 치고 있다. 하지만 맨날 지고 있으니 정말 소 한 마리 잡아야 300이 되는 날이 올 것 같다.
부록 - 내가 읽은 책들
마지막으로 내가 읽은 책들에 대해 이야기하고자 한다. 필자에게도 특별한 방법이 있는 것은 아니다. 배울 시기에 부지런히 읽어두자는 의미에서 정리했다.
기본서
배울 시기에 읽었던 책 대부분은 어디론가 없어졌다. 그나마 내 책장에 남아 있는 책과 지금은 없지만 기억 나는 책들을 정리한다.
유닉스의 내부 구조 전공 과목의 참고 서적
요즘은 Design 4.3 BSD UNIX? (Samuel J. Leffler, Marshall Kirk McKusick, Michael J. Karels)라는 책도 보는 것으로 알고 있다.
Operating Systems: Design And Implementation (Andrew S. Tanenbaum, Albert S. Woodhull)
나도 리누스 토발즈와 마찬가지로 미닉스를 해킹했었다.
유닉스 시스템 프로그래밍
예전부터 이런 팔리지도 않을 책을 많이 만드는 출판사가 있었다.
Compilers : Principles, Techniques, and Tools (Alfred V. Aho, Ravi Sethi, Jeffrey D. Ullman)
이 책을 읽고 나면 세상의 모든 소프트웨어는 파서이거나 완전한 컴파일러로 보일 것이다. 물론 이런 관점이 과히 틀린 것은 아니다.
The C Programming Language (Brian W. Kernighan, Dennis M. Ritchie)
더 말할 필요도 없는 바이블이다.
그 외 알고리즘, 이산수학(NAND의 놀라움이여!)등에 관한 책
현업에 가면 아무도 애기하지 않지만 반드시 필요한 기초이다.
최근에 본 책
sendmail, 2nd Edition (O'Reilly)
qmail, postfix가 아무리 노력해도 sendmail 이상이 될 수 없음을 증명하는 책이다. 수많은 세월 동안 사용자의 다양한 요구를 충족시켜온 sendmail은 그래도 소스가 걸레가 되지 않고 살아 남았다. 엄청난 설정 옵션에 질릴 수도 있지만 이 옵션들이 만들어져야만 했던 역사가 있음을 안다면 경외감을 느낄 수 있을 것이다. 인터넷의 시작과 끝은 이메일이고 이메일의 표준은 sendmail이며 그에 관한 바이블은 이 책이다. 필자가 항상 옆에 놓고 보는 책.
† 참고로 최근에 모 웹 메일 사이트는 처음에 qmail로 셋업을 했으나 DSN이 없음을 알고 다시 sendmail로 전환했다. 시스템적으로 말한다면 개개의 소프트웨어의 성능은 크게 중요하지 않다. 프로그램이 느리면 서버 몇 대 더 사서 붙이면 된다. 기회 비용으로 따질 때 프로그램에 종속적인 개발에 드는 추가 비용이 서버 가격을 훨씬 상회함을 알아야 할 것이다. DSN이 뭐냐고? RTFM!
오라일리의 책 대부분
시스템 엔지니어라는 관점에서 보면 오라일리 책들은 필독서이다. 한빛미디어(주)에서 번역서로 출간된 DNS와 BIND , TCP/IP 네트워크 관리, 파이썬 시작하기, 삼바 활용하기 등은 꼭 챙겨두어야 할 책이다.
특히 유닉스 파워 툴은 놀라운 책이다. 유닉스 시스템에 관한 노하우를 모두 배울 수 있다. 이 책은 유닉스 시스템 엔지니어의 수명이 길 수 밖에 없음을 증명하는 책으로, 1970년대에 배운 유닉스 지식으로도 2000년대에 버틸 수 있음을 보여 준다.
사놓고 못보고 있는 책
The Art of Computer Programming(3권) (Donald Ervin Knuth)
도날드 누스 교수는 60년대부터 이 책을 썼는데 아직도 끝을 못내고 교정만 보고 있다. 이 책을 위해서 TeX을 만들었다. 물론 TeX에 관한 5권의 책도 사놓고 The TeXBook만 보고 나머지는 못보고 있다. 나도 언젠가는 3벌체 메타폰트를 만들어 내가 쓰고 내가 조판해서 출판할 꿈을 꾸고 있다.
나오며
시간을 내서 스트로크 연습하러 가야 하는데 마음의 여유가 없어서 가지 못하고 있다. 여러분은 어떤가? 혹시 책상 앞에 보고 싶은 책 사놓고도 몇 달 째 인터넷 서핑하는 데 바빠서, 모질라 새 버전 테스트 하느라고 바빠서, 그놈 데스크탑 커스터마이징 하는 데 바빠서 아직도 못 읽고 있지는 않은가?
컴퓨터를 잘 하기 위해서는 컴퓨터를 꺼 놓아야 한다는 진리를 기억하기 바란다.
김인성.
|