미닉스의 작은 이야기들
리눅스와 윈도우의 공존 (주의: 스크롤 압박 있음) 본문
리눅스와 윈도우의 공존김인성
잡지 마이크로소프트웨어에 1998-1999년에 연재했던 내용의 원본을 이창재님의 홈페이지 아래(http://iskim.intosea.com)에도 있습니다. 기술적인 내용이 많기 때문에 리눅스에 대해서 모르시는 분들은 안 보셔도 됩니다.
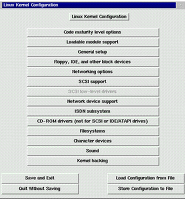
리눅스와 윈도우의 공존1. 리눅스와 윈도우의 공존 * 1.1 하드 디스크 에라 숨기기 * 1.2 박스기사 : 리눅스 작업 플로피 제작 2. 기업 환경을 위한 리눅스 블랙박스 만들기[2] * 2.1 작업 디스크를 이용한 윈도우 백업 * 2.2 제닉스 파일시스템을 구출하라 * 2.3 그밖의 활용 가능성 * 2.4 맺으며 * 2.5 이달의 숙제 : * 2.6 박스 기사 : 리눅스를 배워 보려는 사람들을 위한 조언 3. 기업 환경을 위한 리눅스 블랙박스 만들기[3] * 3.1 숙제 풀이 * 3.2 작업디스크와 관련된 두가지 사건 * 3.3 리눅서는 어떻게 크는가 * 3.4 박스 기사 : 리눅스 문서들 * 3.5 박스 기사 : EQL을 설정하자 4. 기업 환경을 위한 리눅스 블랙박스 만들기[4] * 4.1 윈도우에서 리눅스를 제어한다. * 4.2 숙제 풀이 * 4.3 리눅스로 부팅한 후에 할 최소한의 작업 * 4.4 linuxconf 의 사용 * 4.5 ip의 설정 * 4.6 telnet의 사용 * 4.7 webmin의 사용 * 4.8 webmin의 접근 제한 설정 * 4.9 webmin을 이용한 삼바 설정 * 4.10 webmin을 이용한 프로세스의 관리 * 4.11 리눅스 블랙박스화를 위하여 * 4.12 이달의 숙제 5. 기업 환경을 위한 리눅스 블랙박스 만들기[5] * 5.1 삼바 서버 만들기, 이보다 쉬울 순 없다. * 5.2 숙제 풀이 * 5.3 패키지 버전 따라잡기 * 5.4 삼바 주식회사 * 5.5 리눅스가 설 자리 * 5.6 윈도우 설정 * 5.7 리눅스 사용자 등록 * 5.8 삼바 기본 설정 * 5.9 삼바 home 설정 * 5.10 삼바 tmp 설정 * 5.11 삼바 agroup 설정 * 5.12 삼바의 재시작 * 5.13 쉬운 리눅스를 향하여 * 5.14 이달의 숙제 6. 기업 환경을 위한 리눅스 블랙박스 만들기[6] * 6.1 메일서버 세팅과 엑스윈도우 * 6.2 숙제 풀이 * 6.3 웹 방식 작업의 한계 * 6.4 윈도우에서 엑스윈도우를 사용한다 * 6.5 Xmanager를 리눅스 서버에 붙이기 * 6.6 박스 기사 : 엑스 서버에 대한 기초 지식 * 6.7 메일 서버의 설정 * 6.8 메일 서버의 인스톨 * 6.9 메일 서버 세팅 * 6.10 메일 사용자 만들기 * 6.11 박스 기사 : 메일 전송에 대해서 * 6.12 한글 메일의 처리 * 6.13 윈도우에서 메일 보내기 * 6.14 윈도우에서 메일 받기 * 6.15 sendmail의 보안 문제 * 6.16 메일 서버에 대한 나머지 얘기 * 6.17 이달의 숙제 7. 기업 환경을 위한 리눅스 블랙박스 만들기[7] * 7.1 20만통의 메일과 sendmail * 7.2 숙제풀이 * 7.3 이글의 범위 * 7.4 필요한 것들 * 7.5 1천통의 이메일 * 7.6 1만통의 이메일 * 7.7 5만통의 이메일 * 7.8 10만통의 이메일 * 7.9 20만통의 메일 * 7.10 100만통의 이메일 처리를 위하여 * 7.11 이 달의 숙제 8. 기업 환경을 위한 리눅스 블랙박스 만들기[8] * 8.1 아파치 웹서버의 설정 * 8.2 윈도우 사용자를 위해서 * 8.3 숙제 풀이 * 8.4 아파치 인스톨 * 8.5 아파치 기본 파일 위치 * 8.6 웹페이지를 윈도우에서 편집하기 * 8.7 아파치 기본 설정 * 8.8 이달의 숙제 * 8.9 박스 기사 : 리눅스 킬링 소프트웨어 아파치
1. 리눅스와 윈도우의 공존 리눅스가 윈도우 운영체계를 극복할 것인가 아닌가하는 것은 이 글의 논의 대상이 아니다. 모든 운영체계는 나름대로의 영역과 쓰임새가 있는 것이다. 거의 모든 부분에서 윈도우가 쓰이고 있지만 리눅스를 사용하는 것이 윈도우 보다 더 편리하고 더 쉽게 작업할 수 있는 영역도 존재하고 있다. 특히 리눅스의 네트웍 서버로서의 쓰임새는 윈도우 보다 더 좋다는 것을 누구나 인정하고 있다. 이제 윈도우를 사용하는 컴퓨터가 대부분인 환경에서도 리눅스를 사용하는 컴퓨터가 한대쯤 있어야 하지 않는가하는 생각을 해본다. 후발 운영체계이기 때문에 나름대로 윈도우와 공존을 위한 장치가 많고 그 장치를 이용한다면 윈도우가 해 줄 수 없는 역활을 충실히 해 줄 수 있기 때문이다. 이번 호에서는 리눅스가 하드웨어를 다루는 방식의 특성을 이용해서 윈도우의 사용에 편리함을 더하는 방법에 대해서 알아보기로 하자. 이 것은 어떤 운영체계가 주가 되고 어느 것이 종속적인가하는 문제가 아니다. 서로 보완할 수 있는 부분이 있다면 그 것을 적극적으로 활용하는 것이 운영체계를 목적이 아닌 수단으로 삼는 것이 되고 기업의 생산성에도 도움이 줄 수 있으며 리눅스가 보편적인 운영체계로 자리잡는 가장 빠른 방법이 되기 때문이다. 윈도우와 윈도우NT로만 되어 있는 환경에서 리눅스 박스를 두는 것은 어떤 장점이 있을까? 그 답은 리눅스 박스를 설치하고 사용해 보면 안다는 것이다. 하지만 윈도우 사용자가 리눅스를 인스톨하고 사용법을 익히는 것은 어려운 일이다. 우선 간단한 리눅스 작업 플로피를 만들어 보았다. 이 것으로 리눅스에 대한 경험을 쌓고 정말 쓸모 있다는 것을 몸으로 확인하고 나서 본격적으로 리눅스 박스를 설치해도 늦지 않을 것이다. 이 번 달에는 비록 한개짜리 플로피지만 리눅스를 이용해 윈도우 파티션에 대한 작업을 하면 얼마나 효율적이고 편리한가에 대해서 알아 보기로 하자.
박스 기사 : 리눅스 작업용 플로피 설명
리눅스 작업 플로피를 만들기 위해서는 이번 달에 제공되는 디스켓의 압축을 풀고 도스나 윈도우에서 다음 명령을 사용하면 된다. c:\> rawrite -f work-img.gz -d a 리눅스에서는 다음 명령을 써도 된다. # cat work-img.gz >/dev/fd0 이 리눅스 작업 플로피는 리눅스 파일 시스템으로 되어 있기 때문에 도스에서 읽지 못한다. 이제 이렇게 만든 플로피로 부팅을 한다. 초기화면에서 사용자의 입력을 기다리고 있을 때 잠시 기다리면 리눅스 부팅을 시작한다. 로그인 화면에서 root라고 치면 리눅스 프롬프트가 뜬다. 이제 이 글에서 설명하는 작업을 진행할 수 있다. 참고로 로그인 했을 때 있는 디렉토리는 /root 이다. 루트 디렉토리는 ls명령으로 볼 수 있다. #cd / #ls bin/ etc/ mnt/ root/ usr/ boot/ lib/ mnt2/ sbin/ var/ dev/ lost+found/ proc/ tmp/ /etc 디렉토리는 리눅스 부팅에 관련된 설정 파일들이 있고 /lib에는 프로그램이 실행 될 때 필요한 라이브러리가 있다. 그외 /tmp, /proc 등의 디렉토리들은 리눅스 실행에 필요한 디렉토리 들이다. 윈도우 사용자라면 크게 신경쓰지 않아도 된다. 윈도우 파티션을 /mnt, /mnt2에 붙일 수 있다. 이 것을 마운트 한다고 말하며 마운트한 윈도우 파티션은 리눅스 디렉토리처럼 간주하고 작업을 할 수 있다. 사용자가 알고 있어야할 실행가능 파일들은 /bin 과 /sbin에 있다. 윈도우와 관련된 작업을 위해서 필요한 최소한의 프로그램들을 모아 놓았다. 마찬 가지로 그 내용은 ls 명령으로 볼 수 있다. # ls /bin bash cut elvis login mv sh vi cat dd filesize ls ping sync zcat chmod df gzip mkdir rdev tar compress dirname hostname mknod rm tr cp e2fsck ipmask mount rmdir umount
#ls /sbin agetty brc ifconfig mount route smbumount badblocks fdisk init probe shutdown umount bdflush halt mke2fs reboot smbmount update 어떤 프로그램을 사용할지는 연재 중에 거의 나올 것이다. 관심있는 사용자라면 리눅스가 깔려 있는 컴퓨터, 즉 리눅스 박스에서 사용 설명서들을 읽어 보는 것도 좋을 것이다. 리눅스 사용자라면 이달의 디스켓 나머지 파일을 이용해서 직접 자신의 작업 디스켓을 만들 수 있다. 이 글의 뒷부분에 그 방법에 대해 설명했으니까 참조하기 바란다. 리눅스 작업 플로피가 인식할 수 있는 하드웨어는 IDE 장치, SCSI 장치, 네트웍 장치가 있다. IDE 하드디스크는 4개까지 모든 IDE CD-ROM을 인식할 수 있고 SCSI 카드는 Adaptec, buslogic, future domain, ncr등이다. 네트웍 장치는 3Com, intel eepro 계열, NE2000 호환 카드를 인식할 수 있다. 그밖의 다른 창치는 별로 중요하지 않기 때문에 커널에서 인식하지 않게 했다. 작업 플로피가 인식하지 못하는 하드웨어에 대한 지원이 필요하다면 스스로 제작하거나 주의의 리눅서들에게 부탁하기 바란다. 한개의 플로피에 모든 디바이스에 대한 지원을 할 수 없어서 이렇게 했을 뿐 리눅스가 인식할 수 있는 디바이스는 상당히 많이 있다. 네트웍 프로토콜은 TCP/IP가 지원되며 NFS를 사용해 다른 리눅스 박스를 마운트할 수 있고 samba 프로토콜을 이용해서 윈도우 박스의 하드디스크를 사용할 수 있도록 했다. samba와 NFS 사용법은 필요한 부분에서 적을 예정이므로 연재를 읽으면 알 수 있다. 1.1 하드 디스크 에라 숨기기 하드 디스크를 오래 사용하게 되면 에라가 나게 된다. 파일 시스템이 엉키는 간단한 것이라면 디스크 검사로 해결이 된다. 불량 섹터가 났을 때 도스나 리눅스 포맷으로 해결 되기도 한다. 이렇게 운 좋은 경우는 불안하지만 별 어려움 없이 사용 할 수가 있다. 어려운 것은 하드 디스크가 물리적인 에라가 났을 때이다. 물론 이 것도 로우레벨 포맷 프로그램이나 바이오스의 하드디스크 포맷으로 해결하는 경우도 있다. 이것은 그 섹터를 베드라고 설정하고 사용하지 않는 방법을 쓰는 것이다. 가장 심각한 것은 논리 포맷 프로그램과 로우레벨 포맷 프로그램이 실행 중에 에라가 난 부분에서 더 이상 진행하지 못하고 중단 되는 경우이다. 이 때에는 에프터 서비스를 받아야 한다. 에프터 서비스가 문제가 없다면 좋겠지만 종종 판매한 곳을 찾을 수 없어서 이 것이 불가능하거나 고치는 비용이 오히려 중고 가격을 능가하는 경우가 많다. 어쩔 수 없이 하드디스크를 폐기 처분해야 하는 것이다. 하드디스크가 완전히 고장나서 인식조차 되지 않을 때라면 더 이상 이야기 할 것이 없지만 만일 하드디스크의 일부 섹터가 물리적인 에라가 나서 정상작동을 하지 않는 경우라면 해결 방법이 있다. 리눅스의 mke2fs/badblocks 프로그램은 직접 하드디스크와 교신하기 때문에 하드 디스크의 물리적 에라에도 불구하고 끝까지 검사를 한다. 도스 포맷과 바이오스 포맷 은 맵핑하거나 베드섹터라고 표시할 수 없는 에라가 났을 때 포맷자체를 중단해 버리기 때문에 에라난 부분을 찾거나 그 부분의 크기를 알 수 없지만 리눅스에서는 이 부분을 정밀하게 찾아 낼 수 있다. 그렇다면 리눅스에서 하드디스크를 모두 조사하여 에라난 부분을 제외하고 파티션을 한다면 하드디스크의 용량을 크게 잃지 않고 안전하게 재활용 할 수가 있게 되지 않겠는가? 이렇게 할 수 있는 것은 하드디스크의 물리적 에라는 일시적인 충격에 의해서 일부분의 섹터가 긁혀 생기는 경우가 많기 때문이다. 이물질이 들어갔다면 물론 지속적으로 베드가 증가하게 되니까 이렇게 해도 쓸 수는 없을 것이다. 자 이제 하드디스크를 재활용할 수 있는 경우를 정리해 보자. 하드디스크가 인식은 되지만 베드섹터가 났거나 포맷이 안되며 에프터서비스를 받을 수 없는 상황이다. 하드디스크의 일부분이라도 살려서 사용하고 싶다. 이럴때 리눅스가 어떻게 도와 줄 수 있는가? 필자의 스카시 하드디스크가 일부 섹터가 에라가 났다. 이 것을 살려낸 과정을 보이기로 한다. 우선 리눅스 fdisk 프로그램을 이용해서 전체를 리눅스 파티션으로 잡았다. # fdisk /dev/sda
Disk /dev/sda: 17 heads, 62 sectors, 1020 cylinders Units = cylinders of 1054 * 512 bytes
Device Boot Begin Stat End Blocks Id System /dev/sda1 1 1 1020 537509 83 Liux native fdisk 사용법은 m이라고 치면 자세하게 나온다. 주로 쓰는 것은 d(지우기), n(추가하기), t(ID 바꾸기), a(부트 파티션 설정하기), w(변경사항 실제로 쓰기) 등이다. 명령마다 간단한 메뉴가 나오기 때문에 사용에 어려움은 없을 것이다. 에라난 디스크를 다루고 있으므로 걱정하지 말고 명령을 시험해 보기 바란다. 이 글은 fdisk 사용법에 대한 글이 아니다. 명령 사용법은 스스로 조사해 익히기 바란다. 앞으로도 자세한 명령 사용법은 언급하지 않을 것이다. 실린더가 1020, 실린더당섹터가 62, 헤드수가 17개이며 리눅스 섹터는 512바이트이므로 모두 곱하면 약 540M 가 된다. 이 중 일부 섹터가 에라가 나서 전체를 쓸 수 없게 된 것이다. 어느 부분이 에라가 났는지 살펴보자. # mke2fs -c /dev/sda1
... Checking for bad blocks (read-only test): ...
Current error sd08:01: sense key Medium Error Additional sense indicates Unrecovered read error Scsidisk I/O error: dev 08:01, sector 1092, absolute sector 1154 scsi0: MEDIUM EROR on channel 0, id0, lun0, CDB: Request Sense 00 00 00 10 00 ...
... Current error sd08:01: sense key Medium Error Additional sense indicates Unrecovered read error Scsidisk I/O error: dev 08:01, sector 414286, absolute sector 414348 scsi0: MEDIUM EROR on channel 0, id0, lun0, CDB: Request Sense 00 00 00 10 00 ... 필요한 부분을 제외하고는 모두 생략했다. mke2fs의 -c 옵션은 badblock 프로그램을 부른다. 이 프로그램은 물리섹터를 조사해 불량 유무를 조사하는 프로그램이다. 화면에서 물리 섹터 1154와 414348 부분이 에라가 났다. 실제로는 1154부터 약 300개 414348부터 약 100개 정도의 불량섹터가 있었다. 편의상 생략한 것이다. 불량섹터는 불량섹터를 부른다. 불량섹터 큰처를 억세스하게 되면 하드디스크의 이상 동작으로 계속 이 것이 증가하는 경향이 있다. 그러므로 가능하다면 불량섹터를 중심으로 어느 정도의 여유를 두고 이를 제외한 파티션을 한다면 불량섹터가 증가할 가능성이 적어진다. 이 하드디스크의 섹터수를 2로 나누면 그 부분의 위치를 1k바이트 단위로 알 수 있다. 위에서 1154섹터는 577k 바이트 부근이며 414348섹터는 207174k 바이트 부근이다. 이제 이 곳을 제외한 파티션을 새로 해 보자 # fdisk /dev/sda
... Device Boot Begin Stat End Blocks Id System /dev/sda1 * 3 3 380 199206 6 DOS 16-bit >=32M /dev/sda2 421 421 1020 316200 6 DOS 16-bit >=32M ... 이 디스크의 실린더는 1020이므로 1실린더가 약 500K 정도이다. 첫번째 베드섹터를 피하기 위해서 첫번째 파티션은 실린더 3부터 시작했다. 두번쩨 베드섹터가 200M 근처에 있으므로 앞뒤로 1-2메가 정도의 여유를 두었다. 화면에서 보듯이 도스에서는 두번째 파티션을 확장파티션으로 설정해야 하지만 리눅스에서는 아무 상관이 없다. 이렇게 만든 파티션도 윈도우에서 문제 없이 쓸 수 있다. 물론 이렇게 쓰기 위해서는 첫번째 파티션을 부트가능하게 만들어야 한다. 불안하다면 두번째 파티션을 ID 5번 확장 파티션을 만들고 도스 fdisk 프로그램으로 그 안에 논리 드라이브를 만들면 된다. fdisk에서 파티션을 변경하는 것은 d로 지우고 n으로 추가하고 t로 아이디를 바꾸는 작업이다. ID 값을 알고 싶으면 l이라고 치면 된다. 조금만 해 보면 쉽게 모든 조작을 할 수 있을 것이다. 필자는 특수한 경우를 위해서 스카시 하드 디스크를 예로 들었지만 IDE 하드 디스크도 마찬 가지이다. 첫번째 IDE 디스크는 hda, 두번째는 hdb라는 이름을 가진다. 도스의 C:,D:와는 개념이 다르기 때문에 주의해야 한다. 에라난 디스크를 다룬다고는 하지만 무척 중대한 작업이니까 리눅스에 대한 이해가 조금은 있는 사람과 함께 하거나 스스로 리눅스에 대한 이해를 한 후에 도전하기 바란다. 리눅스에 대한 이해를 위해 필요한 모든 정보는 쉽게 구할 수 있고 무료이기 때문에 어렵지 않을 것이다. 리눅스에 대해 알고 있는 것이 앞으로 많은 도움이 될 수 있다. 요즘 같이 어려운 시기에 하드디스크 하나도 아쉬운 상황이므로 이 방법을 사용해 볼만하다. 이 하드디스크의 전체 용량에서 약 5메가 바이트 정도만 손해보고 정상적 으로 사용할 수 있으니까 좋은 일이다. 물론 리눅스를 인스톨 해서 쓴다면 더욱 좋겠지만 그건 사용자 마음에 달려 있는 일이다. 참고로 이렇게 쓰는 하드디스크는 중요한 시스템 디스크로 사용하기 보다는 보조적인 용도로 쓰는 것이 좋을 것이다. 하드디스크 청소하기 하드 디스크를 여러 컴퓨터에 옮기며 사용하다 보면 특이한 문제가 생기는 경우가 있다. LBA모드 등에 대해서 롬바이오스가 잘못 판단하는 경우 등인데 한 컴퓨터에서 LBA 모드로 포맷해서 사용하다가 다른 컴퓨터에 연결했을 때 하드디스크의 설정이 LBA로 보이지 않거나 이렇게 강제로 설정해도 부팅 후에 바뀌거나 도스 fdisk 프로그램이 제대로 디스크 용량을 인식하지 못하고 엉뚱한 크기로 파악하는 경우등이다. 이 것은 근본 원인을 알 수 없지만 하드디스크의 마스터 부트 섹터가 이상이 있거나 LBA 모드를 파악하는 방법이 컴퓨터 바이오스에 따라서 제대로 적용되지 않을 때 문제가 생기는 듯하다. 원인은 알 수 없지만 일반적으로 이런 경우에는 간단한 방법이 있다. 리눅스 플로피로 부팅해서 다음 명령을 실행해보자. # cat /dev/zero >/dev/hda 이 명령은 0을 하드디스크 전체에 쓰는 명령이다. 리눅스는 하드디스크를 물리적인 스트림의 저장체로 보기 때문에 이 명령은 하드디스크의 물리적인 영역 모두에 0을 쓰게 된다. hda는 마스터 부트 섹터부터 하드 디스크 끝까지를 의하며 hda1은 하드 디스크의 첫번째 논리적 파티션이 점유하고 있는 물리적 파티션 전체를 의미한다. 그러므로 위의 명령은 물리적 하드 디스크 전체를 0으로 초기화 하는 것이다. 이 명령을 실행하고 나면 파티션 정보를 포함한 모든 내용이 지워진다. 이제 바이오스에서도 하드디스크의 용량을 제대로 잡을 수 있고 도스 포맷에서도 문제가 없을 것이다. 이렇게 처리한 하드 디스크에 대해서 도스에서 꼭 해야 할 것이다. 마스터 부트 섹터를 초기화 했기 때문에 파티션을 새로 잡아도 부팅되지 않는다. 이럴 때 리눅스 사용자만이 알고 있는 다음과 같은 도스 명령을 사용해야 한다. a:> fdisk /mbr 리눅스 사용자 사이에서는 아주 유명하지만 윈도우 사용자는 한 번도 본 적이 없을 것이다. fdisk /? 를 사용해도 나오지 않기 때문이며 도스만을 사용한다면 전혀 쓸 일이 없는 옵션이기 때문이다. 이 옵션은 하드 디스크 마스터 부트 섹터의 파티션 정보를 제외한 모든 부분을 새로 쓰게 된다. 컴퓨터에 붙어 있는 첫번째 하드 디스크에만 사용 할 수 있기 때문에 이 명령을 실행해야 할 하드 디스크는 반드시 첫번째로 연결해 놓아야 한다. 이 명령은 다른 용도로도 사용할 수 있는데 예를들어 마스터 부트 섹터에 존재하는 바이러스를 잡을 때도 쓸모가 있다. 회사에서 보안이 필요한 정보가 담긴 하드디스크를 관리하기 위해서 여러 가지 방법이 있을 수 있다. 이런 하드디스크를 다른 용도로 사용하려고 할 때 단순히 파일을 지우기 만 해서는 안된다. 지운 파일을 살리는 프로그램이 있기 때문이다. 이렇게 해서 정보를 빼내지 못해도 하드 디스크를 섹터 단위로 읽게 되면 정보를 쉽게 가져 갈 수 있다. 이럴 때 위에서 말한 "cat /dev/zero >/dev/hda" 명령을 사용하면 좋다. 하드 디스크의 파일 시스템이 모두 없어질 뿐만 아니라 모든 섹터가 완전히 0으로 초기화 되기 때문이다. 시디롬 읽기 윈도우는 아직 도스의 그늘에서 자유롭지 못하다. 새로 산 하드 디스크를 연결하고 윈도우를 인스톨하기 위해서 하드 디스크를 포맷한 후에 시디롬을 인식 시키기 위해서 복잡한 방법이 필요하다. 도스 플로피를 만들고 config.sys와 autoexec.bat를 고쳐서 도스 플로피 부팅 후에 시디롬을 인식할 수 있도록 해야 한다. 도스 플로피를 만드는 작업, mscdex.exe 프로그램이 필요하고 config.sys등을 고쳐야 하며 장착된 시디롬에 맞는 디바이스 드라이버 또한 필요하다. 물론 이 디바이스 드라이버가 요구하는 적절한 옵션에 대해서도 알고 있어야 한다. 이렇게 하지 않고 하드 디스크를 윈도우가 설치된 다른 컴퓨터에 연결하여 윈도우 시디롬에서 필요한 파일만 복사해서 인스톨하는 방법을 쓸 수도 있다. 이 방법을 위해서 두 컴퓨터를 분해하고 새 하드 디스크를 다른 컴퓨터에 연결하는 작업이 필요하다. 윈도우 복사를 위해서 새 하드 디스크를 연결한 컴퓨터에서는 시디롬을 세컨더리 마스터에서 슬레이브로 바꾸어야 하고 하드 디스크를 다시 인식 시켜야 한다. 불행히 여분의 전원 케이블이 없다면 일은 더욱 복잡해진다. 이렇게 컴퓨터에 대한 작업은 기대한 작업 시간과 복잡도가 증가하는 경향이 있다. "새 하드 디스크에 윈도우 인스톨 파일 복사하기"라는 간단한 작업을 수행하기 위해서 두 컴퓨터를 뜯고 전원 케이블을 구하러 다니거나 시디롬과 하드 디스크의 매치가 이상해서 불필요한 곳에서 시간을 소비하기도 하고, 도스 플로피를 만들어서 시디롬을 인식 시키려 할 때에도 필요한 디바이스 드라이버를 구하기 위해서 시디롬 제작 회사의 홈페이지까지 방문해야 하는 경우도 있다. 퇴근 1시간 전에 금방 끝냈 수 있을 것으로 보이는 이런 간단한 작업을 시작했다가 막차를 놓치는 경우가 허다하다. 리눅스가 어떻게 이런 상황을 쉽게 해결하게 해 줄 수 있을까? 리눅스 부팅 플로피로 간단히 해결가능하다. 리눅스는 IDE 시디롬에 대해서 단일한 디바이스 드라이버를 사용한다. 모든 IDE 시디롬이 장착된 위치에 따라 /dev/hdb /dev/hdd 까지 명칭은 달라 지지만 마운트 해서 읽을 수 있다. 세컨더리 마스터는 /dev/hdc이다. 시디롬은 하드 디스크와는 달리 파티션 개념이 없기 때문에 hdc1,hdc2이런 명칭을 사용하지 않는다. 다음 작업으로 간단히 시디롬의 필요한 파일을 하드 디스크에 옮길 수 있다. # mount /dev/hda1 /mnt # mount /dev/hdc /mnt2 -o ro # mkdir -p /mnt/backup/win95 # cp -a /mnt2/win95/* /mnt/backup/win95 얼마나 간단한 작업인가. 하드 디스크가 적다면 윈도우를 인스톨 한 후에 이 파일들을 지우면 그만이다. 도스 플로피를 만드는 작업에 비해서 작업 시간이 훨씬 적고 하드 디스크를 다른 컴퓨터에 옮기는 작업을 하지 않아도 되기 때문에 드라이버를 들고 컴퓨터를 열 필요가 없다. 퇴근 시간 전까지 윈도우 인스톨 뿐만 아니라 응용 프로그램까지 모두 설치해도 시간이 남게 되지 않을까? 오래된 시디롬은 사운드 카드에 업체마다 특별한 방식으로 연결되어 있다. 이런 시디롬이 회사안에 있다면 커널 컴파일을 새로 해서 그 시디롬에 대한 지원을 추가해 놓으면 필요한 때에 당황하지 않고 작업할 수 있다. 리눅스에서 이런 시디롬에 대한 지원은 좋은 편이다. 그렇다면 시디롬이 달려 있지 않은 컴퓨터에서는 어떻게 할 것인가? 도스에서라면 한가지 방법 밖에 없다. 하드 디스크를 분리해서 시디롬 달린 컴퓨터에 연결해서 필요한 파일을 복사해 오는 것이다. 이 방법은 위에서 말한 모든 문제가 생길 가능성이 있다. 네트웍이 가능하다면 다른 컴퓨터의 시디롬을 리모트로 사용할 수 있다. 윈도우가 정상적으로 동작한다면 문제가 없지만 문제는 언제나 가장 복잡한 상황에서 생기는 법, 지금과 같이 윈도우를 인스톨하는 등 자원 사용이 불가능 할 때에는 많은 시간을 소모 해야 한다. 굳이 도스를 사용하고자 한다면 다시 부팅 플로피를 만들고 도스용 네트웍 디바이스 드라이버를 구해야 하고 필요한 설정값을 알기 위해서 문서를 들여다 보아야 한다. 제 시간에 퇴근하기는 이미 글러 버리는 것이다. 이 것도 리눅스 부팅 디스켓으로 간단히 해결할 수 있다. 이 상황에서 리모트의 시디롬을 리눅스 플로피 만으로 읽어 들이는 방법에 대해서 설명한다. 우선 리눅스 플로피로 부팅한 후에 다음과 같은 명령을 내린다. # cat /proc/net/dev Inter-| Receive | Transmit face |packets errs drop fifo frame|packets errs drop fifo colls carrier lo: 18 0 0 0 0 18 0 0 0 0 0 eth0: 0 0 0 0 0 0 0 0 0 0 0 여기에 보면 eth0 항목이 있다. 커널이 이더넷 카드를 제대로 인식한 것이다. 박스 기사에 리눅스 부팅 플로피가 지원하는 네트웍 카드 목록이 있으니 참고 하기 바란다. 만일 회사에서 사용하는 네트웍 카드가 이 목록에 없다면 커널 컴파일을 통해서 지원 하게 하면 된다. 회사원 중에서 리눅스를 사용하는 사람에게 부탁해서 시간이 있을 때 회사에서 사용하는 네트웍 카드에 대한 지원을 추가하기 바란다. 여분의 피시가 있다면 이 기회에 리눅스 박스를 하나 만들어 두면 더욱 좋다. 커널이 네트웍 카드를 인식 했다면 그 다음은 일사천리로 진행할 수 있다. 다음 명령을 사용할 것. # ifconfig eth0 192.168.1.20 # route add -net 192.168.1.0 192.168.1.20은 임의로 만든 IP번호이다. 이 번호는 회사의 네트웍 중에서 여유가 있는 번호로 바꾸어야 한다. ifconfig는 네트웍 카드 eth0에 IP를 할당하는 명령이다. route명령으로 이 컴퓨터가 할당받은 IP가 속한 네트웍을 라우팅하도록 한다. 물론 이 번호도 회사에서 사용하는 실제 번호로 바꾸어야 한다. 네트웍 카드가 활성화되어 있고 시디롬을 사용할 윈도우 컴퓨터와 연결 가능한지 다음 명령을 사용해 본다. # ping 192.168.1.20 PING 192.168.1.20 (192.168.1.20): 56 data bytes 64 bytes from 192.168.1.20: icmp_seq=0 ttl=64 time=0.4 ms
# ping 192.168.1.30 PING 192.168.1.30 (192.168.1.30): 56 data bytes 64 bytes from 192.168.1.30: icmp_seq=0 ttl=64 time=0.8 ms 192.168.1.30은 시디롬을 사용할 윈도우 컴퓨터의 IP번호이므로 실제 번호로 바꾸어야 한다. 문제가 없다면 패킷 전송 속도가 나올 것이다. 이제 윈도우 머신을 마운트하자. # smbmount //win95com/d /mnt -I 192.168.1.30 -U someuser -P passwd win95com은 랜메니저 위에서 사용하는 윈도우 박스의 이름이다. 윈도우 네트웍 설정에서 "컴퓨터 이름"에 해당하는 값이다. d는 공유하도록 설정된 시디롬이 할당받은 드라이버 이름이며 리눅스 플로피로 부팅한 컴퓨터의 /mnt에 마운트 된다. 플로피로 부팅했으므로 네임서버가 설정되어 있지 않기 때문에 -I 옵션으로 IP 값을 정확히 적어 주어야 한다. 뒤에 있는 것은 물론 윈도우 박스에 로그인할 때 사용하는 사용자명과 비밀번호 값이다. nobody나 비밀번호 없는 사용자로는 윈도우 박스를 마운트 할 수 없다. 사용자명과 이에 따른 비밀번호가 반드시 필요하다. 이제 리모트 윈도우 박스가 로컬의 /mnt 디렉토리에 마운트 되었다. 마치 로컬에 있는 시디롬처럼 사용이 가능하다. 그 후에는 앞에서 설명한 로컬 시디롬 운용과 마찬가지의 작업을 진행하면 된다. 한개의 플로피로 네트웍이 가능하고 리모트의 시디롬을 마운트해서 사용할 수 있다면 회사의 컴퓨터 운용에 많은 장점이 있을 것이다. 여기서는 시디롬에서 파일 읽어 오기에 대해서만 설명했지만 리모트 윈도우 박스가 마운트 가능하다면 수많은 일을 할 수 있다. 어떤 일이 가능할 것이지는 사용하는 여러분의 용도가 무엇인지에 달렸다. 다음호 연재에 대해 리눅스에 대해서 조금만 알고 있으면 이렇게 비용을 들이지 않고 특수한 용도로 이용할 수 있는 부분이 많다. 이 외에도 스스로 리눅스를 공부한다면 필자가 알지 못한 부분에서 리눅스가 가진 특성을 이용해 자신의 문제를 해결할 쉬운 방법을 파악할 수 있다. 회사의 전산직 요원이라면 자신의 시간을 들여서라도 리눅스에 대해서 공부를 해야할 이유가 이런 가능성 때문이다. 이달에는 리눅스 플로피를 만드는 방법과 이를 이용해서 하드디스크 에라를 피해가는 방법 그리고 간단히 삼바를 사용하는 법에 대해서 설명했다. 다음 달에는 작업 플로피를 이용해서 윈도우 파티션 전체를 백업하거나 윈도우 파티션의 프로그램만 압축저장하는 것에 대해서 알아보자. 여기에 더해서 NFS를 이용해 리눅스 박스를 백업 서버로 쓰는 것과 samba를 이용해서 윈도우 박스를 이용해서 작업을 하는 방법도 알아보기로 한다. 1.2 박스기사 : 리눅스 작업 플로피 제작 작업 플로피의 구성 윈도우를 위한 작업을 위해서 또는 리눅스 복구를 위해서 꼭 필요한 프로그램만 담긴 리눅스 플로피 파일 시스템이 필요하다. 리눅스 배포본을 만드는 레드헷과 슬랙웨어에 응급복구 디스켓이 따라오고 있지만 어디까지나 배포본 인스톨 위주로 되어 있어서 원하는 작업에 맞지 않는 경우가 많다. 필요한 기능을 가진 리눅스 플로피를 만드는 방법을 알아보자. 이 방법을 알고 있는 리눅서는 자신이 원하는 기능만을 담은 간편한 리눅스 플로피를 가질 수 있을 것이다. 이달에 나가는 리눅스 플로피 파일 시스템은 한 플로피에 2개의 파일 시스템을 가지고 있다. 커널 이미지를 담고 있는 부트 파일 시스템과 작업을 위한 프로그램을 가진 램 디스크 이미지이다. 부트 파일 시스템은 다음과 같은 명령으로 마운트를 할 수 있다. # mount /dev/fd0 /mnt 플로피의 앞부분 669K 바이트가 ext2 파일 시스템으로 만들어져 있으며 커널 이미지와 lilo를 사용한 부팅 옵션을 위한 파일들 그리고 부팅할 때 나오는 메세지가 담겨 있다. 두번째 램 디스크 이미지는 work-img.gz이며 필요하다면 다음과 같은 명령을 사용해서 플로피에서 직접 읽어 올 수도 있다. # dd if=/dev/fd0 of=work-img.gz bs=1k seek=670 dd는 섹터단위로 읽어 들이는 것이고 1k단위 670개를 건너 뛰고 나서 읽어 들이라는 것이다. 이렇게 읽어온 이미지는 뒷 부분에 가비지가 붙어 있으므로 다음 명령을 사용 해서 깨끗한 상태로 만들어야 한다. # gunzip work-img.gz work-img.gz의 압축이 풀리면서 뒷부분의 가비지가 떨어져 나간다. 이 것은 4096k 바이트의 ext2 파일 시스템이다. 이 파일은 다음 명령으로 마운트해서 내용을 살펴 볼 수 있다. # mount work-img /mnt -o loop loop 옵션은 한 개의 파일을 마치 파일 시스템인 것처럼 마운트할 수 있게 해 준다. 이 옵션을 쓸 수 있게 하기 위해서는 커널 컴파일 할 때 CONFIG_BLK_DEV_LOOP 옵션을 활성화 해주고 /dev/loop[0-7] 장치 특별화일을 만들어야 한다. 9월호 마소의 부록으로 배포된 슈퍼 레드헷 리눅스 5.1을 설치 했다면 이 것이 기본으로 설정되어 있으니까 문제가 없을 것이다. 이렇게 한 플로피에 두개의 파일 시스템을 넣으면 어떤 장점이 있을까? 리눅스 배포본에 따라 오는 응급복구 플로피는 2개로 되어 있다. 리눅스용으로 쓰거나 윈도우를 위한 작업을 하기 위해서 플로피 2개를 동시에 가지고 있어야 하고 부팅할 때마다 갈아끼워야 하는 것은 불편한 일이다. 필요한 프로그램의 용량이 도저히 한개의 플로피로는 감당을 할 수 없을 때가 아니면 한개의 플로피로 만드는 것이 관리가 편하고 사용하기도 쉽다. 그래서 필자는 두 파일 시스템을 함께 넣었다. 램 디스크 이미지 만들기 램 디스크 이미지를 만들기 위해서는 우선 파일 시스템 크기를 잘 조절해야 한다. 커널 이미지가 거의 600K 이상이 되기 때문에 램 이미지가 압축한 상태에서 800K를 넘어서는 안된다. 800K 바이트 크기의 파일 시스템에 모든 것을 넣을 수 없다. 꼭 필요한 프로그램과 라이브러리만을 넣어야 한다. 시스템 자원을 마음껏 쓰고 각종 디버깅 정보까지 들어간 라이브러리 libc.so 가 1.5M에 육박하는 등 배포본의 프로그램들은 용량 문제 때문에 사용할 수 없다. 가장 적당한 것이 배포본의 복구 디스켓용 파일 시스템을 이용 하는 것이다. 이 것들은 플로피를 대상으로 했기 때문에 어느 정도 용량에 대한 고려가 되어 있다. 그러나 레드헷의 복구 디스켓은 ext2파일 시스템을 사용하고 라이브러리와 프로그램이 elf 포맷으로 되어 있어서 용량이 무척 크다. 슬랙웨어의 디스켓 용 프로그램 들은 아직도 a.out 포맷으로 되어 있고 라이브러리도 최소한의 기능 만을 넣고 있기 때문에 크기가 비교적 작다. 필자가 예전 부터 작업 플로피를 만들기 위해서 이를 이용해 본 결과 프로그램 성능에도 문제가 없었다. 그래서 이번 호에 제공하는 작업 디스켓은 슬랙웨어의 복구 디스켓을 기본으로 하고 필요한 프로그램을 추가해 만들었다. 작업용 램 디스크 이미지 파일 시스템에는 어떤 프로그램이 들어 가야 할까? 우선 용량을 줄이기 위해서 배포폰의 복구 디스켓에서 인스톨과 관련된 모든 프로그램을 지운다. 어떤 프로그램을 지워야 하는지는 경험에 의존할 수 밖에 없는데 몇가지 프로그램을 지운 후에 작업 디스켓을 만들어 테스트 해보고 지운 프로그램 때문에 에라가 난다면 이를 복구하는 작업을 반복해야 한다. 프로그램들은 크게 나누어서 파일 시스템 시작을 위해서 /etc 아래 스크립트가 사용하는 프로그램, 하드 디스크등을 변경하는데 필요한 프로그램, 네트원 관련 프로그램, ls등과 같은 가장 기본 적인 프로그램으로 나뉜다. vi 같은 에디터는 리눅스 파일 시스템의 설정을 바꾸는 등의 작업을 위한 작업 플로피라면 필요하겠지만 윈도우 파티션을 조정하는 등의 작업에는 필요 없기 때문에 지워도 문제가 없다. 최종 판단은 만들려는 사람의 목적에 맞추어서 테스트한 후에 결정하면 된다. 필자는 유틸리티 쪽을 모두 삭제하고 네트웍 관련 프로그램을 추가 했다. 프로그램을 추가 할 때 가장 주의해야 하는 것은 라이브러리와 관련된 것이다. 레드헷같이 libc6 을 기본으로 하고 프로그램도 모두 elf 포맷으로 되어 있다면 문제가 없지만 용량 문제로 a.out 시스템으로 된 상태에서 원하는 프로그램이 elf이고 최신의 라이브러리를 링크한다면 ldd로 이 프로그램이 어느 라이브러리를 필요로 하는지 확인해야 한다. 새 프로그램을 a.out으로 컴파일하면 되겠지만 현재 모든 배포본이 elf 시스템으로 되어 있어서 그 것도 쉽지 않다. 추가하려는 프로그램이 한 두개라면 라이브러리를 실행 프로그램에 합쳐 버리는 정적 컴파일을 하면 되겠지만 용량을 무시하지 못하게 된다. 20k 정도 되는 프로그램을 정적 컴파일 하게 되면 900K 이상이 된다. a.out은 /lib/ld.so를 이용해서 적재되고 elf는 /lib/ld-linux.so를 이용해서 적재된다. 그러므로 한 프로그램을 추가할 때 필요한 라이브러리의 버전과 필요한 로더가 어떤 것인지 확인하고 모두 /lib 아래에 복사해야 한다. 적은 용량을 염두에 두고 해야 하는 이런 일이 어렵고 복잡하지만 실제로 해 보면 불가능한 일은 아니라는 것을 알게 될 것이다. 파일 시스템의 크기가 압축된 상태에서 800K 보다 작아야 하기 때문에 계속 압축해 보면서 이를 조절해야 한다. 필자의 경험으로는 4M 의 파일 시스템을 만들고 60% 정도 프로그램으로 채우면 압축 했을 때 800K 정도가 되었다. 파일 시스템을 만드는 과정은 다음과 같다. # dd if=/dev/zero of=new_work bs=1k count=4096 4096+0개의 레코드를 입력하였습니다 4096+0개의 레코드를 출력하였습니다
# mke2fs new_work mke2fs 1.10, 24-Apr-97 for EXT2 FS 0.5b, 95/08/09 final.img.3 is not a block special device. Proceed anyway? (y,n) <-- y를 선택 # mount new_work /mnt -o loop # mount work-img /mnt2 -o loop # cp -a /mnt2/* /mnt 이렇게 해서 이전 파일 시스템을 복사한 다음 필요 없는 프로그램을 지우고 원하는 프로그램을 넣는다. 새로 만든 이미지를 압축해서 new_work.gz를 만들고 이 것을 플로피에 써 넣으면 된다. 다음의 명령을 사용하면 된다. dd if=new_work.gz of=/dev/fd0 bs=1k seek=670 플로피 670K 바이트 이후부터 쓰게 되기 때문에 new_work.gz가 너무 커서 다 쓰지 못하게 되지 않도록 주의해야 한다. 필요하면 670보다 적은 값을 사용할 수 있지만 그 때는 부트 파일 시스템의 크기를 줄여야 하기 때문에 커널 부트 이미지의 크기가 부트 파일 시스템에 맞는지 확인해야 한다. 커널 컴파일 작업용 커널은 일반 커널과 달리 필요한 것은 모두 포함 시키고 불필요한 것은 전부 삭제해야 한다. 우선 램디스크를 사용해야 하니까 커널 컴파일에서 CONFIG_BLK_DEV_RAM 옵션을 활성화 해야 한다. 그외 커널 옵션을 설정하면서 y아니면 n로 선택한다. 플로피에서 모듈을 구현하고 이 것을 삽입 적재하는 것은 많은 플로피를 요구하기 때문에 유용성이 없다. 2.0.35 버전의 모듈 전체의 용량은 4M 이상이다. 그러므로 앞으로 쓰게 될 가능성이 있는 디바이스 드라이버 옵션은 모두 활성화 시켜 주는 것이 좋지만 필요 없는 것은 선택하지 않아야 한다. 주의 깊게 선택해야 할 것은 scsi 컨트롤러와 네트웍 카드 부분이다. 리눅스 플로피로 하게 될 것은 주로 하드디스크와 관련된 작업이며 그 과정에서 네트웍을 이용해야 될 경우가 많기 때문이다. 그 밖에 사운드카드, 시리얼 장치, 프린터 등에 대한 옵션은 선택하지 않는 것이 좋다. 커널에 포함 시켜도 사용할 일이 없기 때문이다. 필자가 만든 플로피는 윈도우와 관련된 작업도 해야 하기 때문에 samba 프로토콜과 vfat파일 시스템에 대한 지원 옵션을 모두 활성화 시켰다. 커널을 직접 이용해 부트 플로피 만들기 리눅스는 어떻게 플로피에서 부팅이 가능한 것일까? 부트 플로피를 만드는 작업은 커널이 시스템을 장악하기 전의 불안정한 상태에서 이루어지는 일이기 때문에 리눅스 커널 부팅 과정에 대한 지식이 있어야 한다. 가장 자세한 내용이 있는 것은 lilo 사용 설명서이다. 부트 플로피 제작을 제대로 할 수 있으려면 이 물서를 읽어야 한다. 커널은 가장 앞부분의 부트로더와 압축된 이미지로 구성되어 있다. 커널의 부트로더가 주기억장치에 적재되고 제어가 옮아 오면 스스로 나머지 이미지를 읽어서 압축을 푼 다음 커널 시작 부분으로 점프를 한다. 리눅스를 부팅시키는 프로그램들이 하는 일은 커널의 앞 부분에 있는 부트로더를 읽은 후에 이 곳으로 제어를 옮겨 주는 것이다. 플로피에서 이 부팅 과정이 이루어지게 하는 방법은 여러가지가 있다. 기본적인 방법은 커널을 컴파일을 할 때 "make zdisk"를 사용하는 것이다. 커널의 가장 앞부분에 있는 부트로더를 롬바이오스가 읽어서 리눅스를 적재하게 만드는 것이다. 또는 이미 만들어진 커널 이미지 vmlinuz를 플로피에 복사하는 것이다. # cp /vmlinuz /dev/fd0 이 방법을 사용하면 rdev 명령으로 다음과 같은 설정을 해야 한다. # rdev /dev/fd0 /dev/fd0 # rdev -R /dev/fd0 0 # rdev -r /dev/fd0 17054 (16384 + 670 ramdisk start) 커널이미지의 최초 512바이트 안에 커널 설정이 있다. 이 것을 rdev 명령으로 바꾸는 것이다. 루트를 /dev/fd0로 선택하고 파일 시스템을 읽고 쓰기 가능으로 만들고(-R) 램 파일 시스템을 플로피 디스크 670K 부분에서 부터 읽어 오게 하는 것이다. -r 옵션으로 사용하는 숫자는 16비트 플래그값이다. 2^15 값은 커널을 적재한 후와 램 디스크를 읽기 전의 사이에 사용자 입력을 기다리는가 여부를 결정한다. 2^14 값은 램 디스크를 사용할 지 여부를 결정한다. 나머지 비트는 램 디스크 시작 지점을 표시한다. 위에서 2^15 * 0 (입력 기다리지 않음) + 2^14 * 1 ( 램 디스크 사용함) + 670 (램 디스크 시작점)으로 17054가 되었다. 이렇게 사용할 때는 위에서 설명한 대로 플로피 뒷 부분에 램 이미지를 써야 한다. 플래그 비트와 초기값 설정에 대해서 더 자세하게 알고 싶으면 "man rdev" 를 사용하던지 /usr/src/linux/Documentation/ramdisk.txt를 참조하기 바란다. syslinux의 사용 커널을 직접 이용해서 부트 플로피를 만들면 플로피를 읽을 수 없다는 문제가 있다. 커널 이미지가 그대로 씌어지기 때문에 도스에서 복사를 하기 위해서는 rawrite 만을 사용해야 한다. 이 문제를 해결 하기 위해서 레드헷의 배포본 부트 플로피는 도스 포맷 으로 되어 있다. 도스 포맷으로 되어 있을 때의 장점은 리눅스가 없는 상태에서도 부트 플로피의 내용을 변경할 수 있기 때문에 응급 복구등에 유리하다는 것이다. 이런 장점은 syslinux 프로그램을 사용하고 있기 때문에 가능하다. 9월호 마소에서 배포한 슈퍼 레드헷 리눅스 cd 안에 있는 syslinux 소스 파일과 설명서를 보면 자신의 플로피를 만들 수 있다. 실제 내용을 보고 싶으면 cd에 있는 boot.img를 읽어 보기 바란다. syslinux는 메뉴 방식으로 부팅 과정을 조절할 수 있어서 초보자도 쉽게 사용할 수 있는 장점이 있다. lilo의 옵션과 비슷한 방식으로 부팅 방식이나 미디어를 바꿀 수도 있다. syslinux를 사용하게 되면 initrd라는 이미지를 사용하게 된다. 이 것은 초기화 램 디스크인데 램디스크와 차이가 있다. 램 디스크는 부팅한 후에 루트 파일 시스템으로 지정되어 재부팅 할 때까지 변하지 않지만 초기화 램 디스크는 커널이 부른 후 그 안에서 임의의 작업을 하고 언마운트 시킬 수 있다. 이 것을 언마운트 시키고 대신에 일반 램 디스크를 적재하게 된다. 이런 특성 때문에 초기화 램 디스크는 특정 하드웨어에 필요한 모듈을 가지고 있다가 사용자의 요구에 따라 적재하고 사라지는 등 램 디스크의 용량 문제로 유지하고 있기 힘든 프로그램이나 부팅하면서 한 번만 사용되는 프로그램 들을 넣어서 사용할 때 주로 쓴다. 또다른 차이는 램 디스크는 커널이 적재 하면서 /etc/init(/sbin/init)를 실행하게 되지만 초기화 램 디스크는 /linuxrc 파일을 실행 한다. linuxrc는 어떤 프로그램도 될 수가 있다. 초기화 램 디스크에 대해서 더 자세히 알고 싶으면 /usr/src/linux/Documentation/initrd.txt를 참고 하기 바란다. 이렇게 리눅스 파일 시스템이나 리눅스 커널을 이용하지 않는 방법에는 grub이나 loadlin이 있다. grub는 GNU HURD를 적재하기 위해서 만들어진 프로그램이지만 리눅스도 적재할 수 있을 뿐만 아니라 범용 부트 프로그램으로 사용할 수도 있다. loadlin은 도스로 부팅한 후에 리눅스를 적재할 수 있는 프로그램이다. 도스 부트 플로피를 만든 다음에 loadlin.exe 프로그램과 커널 이미지 그리고 필요하면 initrd.img 를 플로피에 복사하고 다음과 같이 실행한다. A:\> loadlin vmlinux initrd=initrd.img [root=/dev/hda2] 이 방법은 플로피에 도스 부트 이미지와 loadlin 프로그램을 넣어야 하기 때문에 용량의 낭비가 심하지만 도스 상에서 실시간으로 옵션을 조절하여 부팅할 수 있기 때문에 여러가지 경우에 쉽게 적응이 가능하므로 응급 복구에 편하다는 장점이 있다. 하드 디스크의 도스 파티션에 이 프로그램과 이미지를 복사해 놓으면 위급할 때 편하게 작업할 수 있을 것이다. lilo의 이용 플로피에도 lilo 부트 프로그램을 사용할 수 있다. 각종 옵션을 실행 시에 변경할 수 있고 용량도 가장 적게 쓰기 때문에 플로피로 부팅하는 방법 중에 제일 좋은 방법이다. 대신 만들기가 까다롭다. 하지만 한 번 만들어 놓으면 이미지를 바꾸기도 쉽고 윈도우 작업, 리눅스 복구 작업, 플로피로 부팅하여 하드 디스크 마운트 용으로 사용하기를 모두 한 플로피로 가능하기 때문에 필자가 가장 선호하는 방법이다. 이 달에 제공되는 작업 플로피는 이 방법으로 만들었다. 작업 플로피의 앞 부분에 669K 짜리 ext2 파일 시스템을 만들고 커널 이미지와 부팅할 때 화면에 나올 메세지파일 그리고 부트 섹터 파일인 boot.b 를 복사해 넣는다. boot.b 와 message는 이달의 디스켓에 포함되어 있다. # mke2fs /dev/fd0 669 # mount /dev/fd0 /floppy # cp /vmlinuz boot.b message /floppy 커널이 적재 된 후에 디폴트로 플로피의 램 디스크를 읽도록 아래 처럼 설정을 하자. # cd /floppy # rdev vmlinuz /dev/fd0 # rdev -R vmlinuz 0 # rdev -r vmlinuz 17054 (16384 + 670 ramdisk start) 그 후에 앞에서 설명한 대로 램 디스크 이미지를 플로피 뒷 부분에 쓴다. 이제 lilo를 플로피에 인스톨 하자. 아래는 lilo.conf.floppy의 내용이다. 이 옵션 파일은 플로피를 /floppy에 마운트 시킨 상태에서 진행한다고 가정하고 작성되었다. boot=/dev/fd0 map=/floppy/map install=/floppy/boot.b prompt timeout=50 message=/floppy/message image=/floppy/vmlinuz label=work root=/dev/fd0 read-write image=/floppy/vmlinuz label=mount read-only lilo의 자세한 옵션은 설명서를 참조하기 바란다. 여기서는 작업 디스켓을 만들기 위해 필요한 옵션만 사용했다. 다음과 같은 명령으로 이 옵션 파일을 플로피에 적용 시킬 수 있다. # lilo -C lilo.conf.floppy 이 플로피를 사용해 부팅한 후 초기 화면에서 work 라고 치거나 그냥 엔터만 치거나 50초 동안 기다리면 스스로 커널을 읽어 들이고 플로피에 들어 있는 램 이미지를 적재한다. 이렇게 되면 윈도우 백업 작업을 하거나 리눅스 복구 작업을 할 수 있다. 초기 화면에서 "mount root=/dev/sda3" 이라고 치면 해당 하드 디스크 파티션을 루트 파일 시스템으로 마운트 한다. sda3에 있는 부트 프로그램이 이상해서 부팅이 되지 않거나 컴파일을 잘못해서 커널 부팅과정에서 시스템이 정지한다면 이 방법을 사용할 수 있다. 커널만 플로피에 있는 것으로 대체될 뿐 정상적으로 하드 디스크로 부팅하는 것과 같기 때문에 하드 디스크의 자원을 이용해서 작업할 수 있다. 이후에 문제를 해결 하고 하드 디스크로 부팅되게 할 수 있을 것이다. 분리된 작업 플로피 만들기 리눅스 부팅 과정에 대한 이해가 있다면 이 설명을 어렵지 않게 이해할 수 있을 것이다. 부트/루트 플로피를 한개로 만드는 것이 관리와 사용이 쉽기 때문에 이 방법에 대해 설명을 했지만 프로그램이 더 필요하다면 두개로 나누어도 상관없다. 이렇게 하면 커널의 크기와 램 이미지의 크기에 대해서 좀 더 여유를 가질 수 있을 것이다. 플로피 한개를 모두 사용한다면 램 디스크 이미지는 8192K 정도의 크기를 가질 수 있다. 원한다면 제한된 갯수지만 모듈 적재를 구현할 수도 있다. 부트/루트 플로피를 분리해서 만드는 방법은 /usr/src/linux/Documentation/ramdisk.txt를 참조하기 바란다. 2. 기업 환경을 위한 리눅스 블랙박스 만들기[2] 2.1 작업 디스크를 이용한 윈도우 백업 저렴한 리눅스 박스의 신뢰성있는 소규모 네트웍 서버 기능을 인식한 기업들에서 최근에 리눅스를 이용한 서버구현이 활성화되고 있다는 소식이 들려오고 있다. 전산직 종사자들의 적극적인 관심이 필요하다. 이 글은 리눅서들이 윈도우 환경에서 리눅스를 활용하는 방법에 대한 글이기도 하지만 NT가 대세라고 믿는 전산직 종사자들의 인식을 바꾸기 위한 목적이 더 뚜렸한 글이다. 그러나 NT에 대한 험담을 한다고 해서 이들의 생각을 바꾸지는 못한다. 리눅스의 장점을 알리고 실제 업무에서 어떻게 효과적으로 문제를 해결할 수 있는지 보여 줌으로써 리눅스의 확대가 가능한 것이다. 지혜로운 대통령이 북한을 개방시키듯이 지혜로운 리눅서들은 리눅서 확대를 위해서 어떤 방법을 사용하는 것이 효과적인가를 깨닫기 바란다.
숙제 풀이
도스에서 두 개의 하드 디스크에 각각 2개의 파티션을 나누었다면 다음과 같을 것이다.
첫 번째 하드 디스크 C: 리눅스 파티션 /dev/hda1 - 프라이머리 파티션 E: 리눅스 파티션 /dev/hda5 - 확장 파티션 (/dev/hda4)안에 있는 논리 파티션
두 번째 하드 디스크 ( EIDE 포트의 세컨더리 마스타에 붙였다고 가정) D: 리눅스 파티션 /dev/hdc1 - 프라이머리 파티션 F: 리눅스 파티션 /dev/hdc5 - 확장 파티션(/dev/hdc4)안에 있는 논리 파티션
그러므로 도스의 f: 파티션을 지우려면 fdisk /dev/hdc 명령을 내려서 /dev/hdc5를 지우거나 도스의 fdisk에서는 하드 디스크 바꾸기 옵션을 사용해서 두 번째 하드디스크를 선택해야 한다. 도스에서 여러 하드 디스크를 붙이고 파티션을 여러 개 만들어 놓으면 헷갈리기 쉬우므로 주의 해야 한다. 리눅스에서 본 하드 디스크 개인 사용자는 하드를 여러 개 붙이거나 외장 장치를 사용하는 등 복잡하게 컴퓨터를 사용하기도 하지만 일반적으로 업무용 컴퓨터에는 IDE하드 디스크가 하나, IDE CD-ROM 하나가 달려 있을 것이다. 여기에 윈도우를 사용해서 한 개의 파티션을 만들어 쓰고 있을 것이다. 하드 디스크가 대용량이라면 파티션을 하나 더 나누고 D:를 배정해서 쓸 것이다. 이 것을 리눅스에서 본다면 다음과 같다. /dev/hda : 하드 디스크 전체, 마스타 부트 섹터 포함 /dev/hda1 : 윈도우의 C: /dev/hda4 : 확장 파티션 /dev/hda5 : 윈도우의 D: 확장 파티션 안에 만들어진 도스 파티션 리눅스에서는 물리 장치인 /dev/hda를 논리적으로 구획을 정하고 있다. 사실 이 것은 시작 위치와 끝 위치에 대한 정보를 어떻게 처리할 것인가의 문제일 뿐이다. hda는 물리 장치의 실제 처음과 끝까지 접근이 가능하며 /dev/hda4는 마스타 부트 섹터에 정해준 시작 위치와 끝 위치까지만 접근하겠다는 선언을 한 것에 불과하다. 물론 윈도우에서도 같은 방식으로 하드 디스크를 처리한다. 처음 부팅할 때 하드디스크로 부팅하게 되어 있다면 hda1을 C:에 배정하고 이후부터 이렇게 논리적으로 나눈 구획에 따라 하드 디스크를 다루는 것이다. 리눅스와 가장 차이가 나는 것은 하드디스크 전체를 다룰 수 있는 /dev/hda가 있는가 여부이다. 윈도우에서는 하드 디스크 전체인 /dev/hda에 대한 일관된 처리 방식이 존재하지 않기 때문에 물리적 관점에서 하드 디스크를 다룰 수 없다. 윈도우용 fdisk는 /dev/hda의 가장 첫 부분인 마스타 부트 섹터만을 다룰 수 있다. 물론 바이오스 명령으로 물리 섹터를 읽을 수 있으나 직접 바이오스의 함수를 불러내는 일은 힘든 일이다. 도스용 노턴 유틸리티의 diskedit는 파티션 정보를 무시하고 하드 디스크의 물리 섹터를 조작할 수 있게 해 주고 최근에 인기를 끌고 있는 하드 디스크 백업 프로그램인 ghost도 윈도우 시스템에 부족한 이런 기능을 보완해 주는 유틸리티이다. 그러나 이들은 말 그대로 유틸리티이므로 안정성이 심히 의심스럽고 하드 디스크 백업 같은 일을 범용성 없는 한 프로그램 회사의 포맷에 따르는 것도 위험한 일이다. 한 순간에 모든 자료를 잃어 버릴 수 있는 이와 같은 위험한 기능은 운영체계에서 직접 지원해야 할 것이다. 하드 디스크는 블럭 디바이스로서 바이트스트림의 저장체이다. 리눅스에서는 마운트라는 방식으로 블럭 디바이스의 논리적 파일 시스템을 인식해서 사용가능하게 해 준다. 마운트 하는 행위는 물리 장치 위의 논리적 구획을 파악해 내는 행위라고 할 수 있다. 이를 바꾸어 말하면 리눅스에서 마운트되지 않은 블럭 디바이스는 바이트스트림의 저장매체에 불과하다는 뜻이다. 즉 /dev/hda1과 /dev/hda2가 그 크기가 같다면 cat /dev/hda1 >/dev/hda2 라는 명령을 사용하여 파티션 이미지를 그대로 복사할 수 있다는 뜻이다. 이 것은 윈도우에서 xcopy c: d: /s(혹은 그와 동등한 명령)등의 명령을 사용해서 파티션 C:의 내용을 D:로 복사하는 행위와 많은 차이가 있다. 윈도우의 C:와 D:는 리눅스의 관점에서 보면 이미 마운트된 논리 장치라고 할 수 있다. copy c: d: 라는 명령을 사용하면 윈도우가 C:의 파일 시스템 정보를 읽어서 D:의 파일 시스템 위에 정확하게 복사하게 된다. 두 파일 시스템 중에 한 군데라도 에라가 있다면 명령은 실행되지 못할 것이다. 리눅스 명령 cat /dev/hda1 >/dev/hda2는 이와 달리 두 파티션에 어떤 정보가 있는지 확인하지 않는다. 무슨 파일 시스템이 설치되어 있는지도 확인하지 않는다. 하드 디스크가 물리적 에라가 없다면 C:가 NTFS이고 D가 포맷되어 있지 않아도 상관이 없다. cat /dev/hda >/dev/hdb 명령을 사용하면 마스타 부트 섹터까지 동일한 두 개의 하드 디스크를 얻을 수 있다. 이 명령은 새로 도입한 컴퓨터가 수십대이고 그 기종이 같다면 한 개의 컴퓨터에 윈도우를 제대로 깔고 사용해 볼만한 명령이다. 1기가 복사하는데 20분이 걸린다고 하면 두세 시간 만에 10대의 컴퓨터에 윈도우를 모두 인스톨 할 수 있는 시간이 된다. 이와 같이 하드 디스크를 바이트스트림의 저장매체라고 보는 리눅스의 관점은 하드 디스크를 일관된 방법으로 제어할 수 있는 수많은 장점을 만들어 주고 있다. 2.2 제닉스 파일시스템을 구출하라 리눅스가 하드 디스크를 다루는 방법을 이용한 예를 보기로 하자. 필자는 최근에 아는 업체의 제닉스 하드 디스크에 생긴 문제를 해결해 주었다. 문제는 이렇다. 이 회사는 5년 전에 업무 처리를 위해서 서버를 도입했다. 운영체계는 제닉스였으며 코볼을 이용한 서버 프로그램이 데이타를 처리했고 16개의 단말기로 회사 사용자들이 정보를 조회하고 업무를 보는 시스템이었다. 유지보수를 위해서 서버를 분리해 작업하던 도중에 터미널 서버가 끊임없이 터미널이 없다는 에러 메세지를 화면에 뿌려서 작업을 할 수 없었다. 작업자는 /etc/inittab의 설정파일을 고쳐서 이를 모두 막아 버렸다. 이제 화면에 에라 메세지가 뜨지 않았다. 그러나 개발자는 콘솔을 위한 로그인 프로그램까지 막아 버렸다는 것을 알지 못하고 작업을 진행했다. 그 후에 디버깅을 위해 리부팅을 하고 나서야 서버에 로그인할 수 있는 방법이 없다는 것을 알게 되었다. 제닉스는 단종된 제품이었고 제닉스 인스톨 디스켓은 에라가 났으며 서버를 구입한 회사는 예전에 문을 닫은 곳이었다. 그들은 여러 가지 방법을 강구했지만 /etc/inittab을 고치는 간단한 일을 해결할 수 없었다. 필자는 요즘 스코(SCO,santa curz operation)에서 무료로 제공하는 스코유닉스 비상업용 판을 깔고 마운트하거나 스코의 파일 시스템을 인식하는 BSD계열의 유닉스를 깔아서 해결하려고 생각했지만 이런 시스템이 생소하고 시간이 걸리는 일이라 리눅스에서 해결할 수 없을까 고민했다. 리눅스에서 BSD의 UFS 파일 시스템을 인식하기는 하지만 업체마다 기본 블럭수가 달라서 인식하지 못하는 등 문제가 있었다. 그래서 개발자가 /etc/inittab의 콘솔 로그인 프로그램명을 getty에서 getty-new로 바꾸었다는 말을 듣고 하드 디스크 이미지를 만들어 고쳐 보기로 했다. 우선 스코 파일 시스템이 있는 하드 디스크 전체를 파일로 받았다. # cat /dev/sda >sco.hd 그리고 하드 디스크 전체에서 getty-new라는 문자열이 한 군데만 있음을 확인했다. # strings sco.hd |grep "getty-new" getty_new 문자열을 getty로 바꾸어서 하드 디스크에 썼다. # sed -e "s/getty-new/getty____/" < sco.hd >/dev/sda (_문자는 공백을 뜻함) 간단한 작업으로 제닉스는 다시 콘솔에서 로그인을 받을 수 있게 되었다. 리눅스의 일관된 처리 방식은 하드 디스크든 파일이든 아무 차이가 없다. 제닉스만 하더라도 하드 디스크를 논리장치 /dev/dsk/와 물리 장치 /dev/rdsk/로 분류하고 사용법이 복잡하다. 이런 단순함과 일관성이 리눅스의 큰 장점이 되고 있는 것이다. 하드디스크 백업 2기가의 하드 디스크를 1.5기가 500메가로 나누어 사용하고 있을 때 C: 파티션에 약 60%의 데이타가 있다면 C:를 백업할 수 있다. C:에는 실제 데이타가 900메가 정도가 된다. 일반적으로 압축효율을 50%라고 가정한다면 압축 백업에 약 450메가 바이트의 공간이 필요하다. 사용 중인 하드 디스크의 빈 영역은 가비지로 차 있다. 파일 삭제 명령은 파일이 점유하고 있던 공간을 청소하는 것이 아니라 파일할당테이블의 정보만 갱신하기 때문에 삭제된 자유 공간을 물리적으로 살펴보면 데이타가 그 대로 있음을 알 수 있다. 때문에 이미지 압축을 하면 이 것도 데이타로 해석하여 압축이 되므로 효율이 떨어진다. 자유 공간은 어떻게 청소할 수 있을까? 윈도우에서라면 문자 "0"을 가진 1바이트 파일을 만들고 다음과 같이 하면 된다. C:\> copy a b (a는 0이라는 문자를 가진 1바이트 파일) C:\> type a >> b C:\> type b >> a 이 명령을 빈 공간이 없을 때까지 반복적으로 실행하면 된다. 윈도우용 ghost 같은 프로그램으로 압축 백업을 한다면 이렇게 해서 압축률을 증가시킬 수 있다. 그러나 이 방법은 같은 파일을 반복적으로 호출하기 때문에 비효율적이고 파일이 커질 수록 한 번의 type 명령이 실행되는 시간이 증가하며 마지막 파일 쓰기가 공간 부족 에라가 나면서 자유 공간의 반 정도를 처리하지 못하기 때문에 자유공간을 완전하게 청소할 수 없다. 리눅스에서는 오버헤드 없이 간단히 처리할 수 있다. 작업 디스크로 부팅하여 C:를 마운트한다. # mount /dev/hda1 /mnt # cat /dev/zero >/mnt/null.dat # rm /mnt/null.dat # umount /dev/hda1 /dev/zero는 ASCII코드 0번(\0)를 생성하는 장치 디바이스이다. cat 명령으로 /mnt에 마운트된 윈도우 파티션에 null.dat파일을 생성한다. null.dat 파일의 크기는 윈도우 파티션의 자유공간의 크기와 같다. 이로써 파티션의 자유공간을 완전히 비우게 되었다. 이제 이미지를 만들자. 다음 명령을 사용할 것. # mount /dev/hda5 /mnt2 # cat /dev/hda1 >/mnt2/hd-c-img # gzip -9 /mnt2/hd-c-img.gz # umount /dev/hda5 C:(/dev/hda1)는 물리적 이미지를 읽어와야 하기 때문에 마운트 하면 안되고 D:(/dev/hda5)는 파일 시스템안에 정상적인 이미지 파일을 생성해야 하기 때문에 마운트 해야 한다. cat 이 보내오는 이미지를 hd-c-img 파일로 만든 후에 하드 디스크를 절약하고 싶으면 gzip으로 압축하여 hd-c-img.gz 파일로 만들어 두면 된다. 이제 윈도우 파티션을 잘못 건드려 파일 시스템이 엉망이 되더라도 윈도우를 다시 깔 필요가 없어졌다. 백업받은 파일로 C:를 다시 살리는 방법은 다음과 같다. # mount /dev/hda5 /mnt # gunzip -c /mnt/hd-c-img.gz >/dev/hda1 이 명령을 실행하기 위해 C:(/dev/hda1)를 포맷하거나 기존의 파일 시스템을 점검할 필요가 없다. 마스타 부트 섹터에 C:에 대한 정보가 있기만 하면 그대로 덮어 쓰면 된다. 도스용 백업 유틸리티도 있는데 구태여 리눅스 디스크를 이용해서 작업을 해야할 이유가 있는가? 어려운 리눅스 명령을 사용하다가 차칫 없어지면 큰일나는 파티션을 덮어 써버리는 실수를 할 수도 있지 않은가? 그 대답은 이렇다. 도스용 백업 유틸리티는 개발 회사의 독자적 방법으로 하드 디스크를 접근하기 때문에 관련 정보를 얻을 수 없고 신뢰를 가질 수 없다. 백업한 데이타가 에라가 없는지 확인하기 위해서는 원 파티션에 이 파일을 덮어 써야 하고 그 과정에서 모든 자료를 잃어 버릴 수 있다. 백업한 데이타가 에라가 없다고 믿고, 무결성을 확인하지 않고 원 파티션을 함부로 사용하다가 파일 시스템을 망가뜨린 후에 정작 백업 데이타에 에라가 있다는 것을 알게 되면 이미 늦게 된다. 쉐어웨어로 보급되는 프로그램을 이용해서 하드 디스크 백업같은 위험한 작업을 하는 것은 자살 행위이다. 유틸리티 제작사를 완전히 신뢰할 수 있다고 하더라도 그들의 백업 방법과 데이타 형식에 대해 알 수 없기 때문에 에라난 백업 파일을 스스로 고치지 못하게 된다. 리눅스에서는 gzip으로 압축된 파일을 풀어 봄으로써 데이타의 무결성을 테스트 할 수 있다. 또한 데이타 파일을 마치 블럭 디바이스처럼 마운트 할 수 있는 기능이 있으므로 백업 파일로 저장된 하드 디스크 이미지를 마운트 해서 테스트해 봄으로써 파일 시스템 내부에 대한 점검도 가능하다. 다음 명령을 사용해 볼 것. # mknod /dev/loop0 b 7 0 # mount hd-c-img /mnt2 -o loop 이제 백업된 데이타를 마치 하드 디스크의 정상 파티션을 마운트 한 것으로 생각하고 그 내부의 디렉토리 구조를 검사하고 파일들이 이상이 없는지 확인해 볼 수 있다. 원한다면 dosemu 프로그램을 사용해서 프로그램을 실행도 시켜 볼 수 있다. 물론 dosemu는 작업 플로피에 없다. 도스 프로텍디트 모드 프로그램과 window 3.1까지 실행할 수 있는 공개 도스 에물레이터인 dosemu를 사용해 보고 싶다면 리눅스 박스를 한 개 만드는 것도 좋은 방법이다. gzip 프로그램은 거의 모든 유닉스 플랫폼에 포팅된 표준 압축 프로그램으로 안정성이 증명된 프로그램이며 리눅스의 하드 디스크 처리 방법 또한 전세계의 사용자가 날마다 반복적으로 사용하고 있는 것이다. 백업같이 크리티컬한 작업에는 이처럼 안정성이 증명된 방법을 사용하는 것이 좋다. 그리고 리눅스에서 만든 하드 디스크 이미지는 다른 유닉스에서도 다룰 수 있다. 유닉스 명령어 중에서 dd라는 명령을 사용하면 FreeBSD나 솔라리스 등에서 이미지 백업 파일을 하드 디스크에 써 넣을 수 있다. 환경이 안된다면 rawrite같은 프로그램의 소스를 참고하여 도스용 프로그램을 만들어도 된다. 이처럼 공개된 형태의 포맷을 사용하면 특정 업체에 의존하지 않아도 되고 원하는 어떤 방법으로도 처리가 가능하다. 하드 디스크 파티션 이미지 전체를 백업하는 것은 앞에서 말한 바와 같이 그 파티션에 무슨 운영시스템이 있던지 아무 상관이 없다. 리눅스, 도스, vfat, fat32, ntfs, hpfs, ufs 등등 모든 파일 시스템을 처리할 수 있다. 리눅스, 도스, vfat, fat32는 읽고 쓸 수 있지만 ntfs, hpfs, ufs등은 읽기 전용으로만 마운트 할 수 있다. 물론 읽기 전용으로 마운트하더라도 파일 시스템의 무결성은 테스트 가능하다. 이밖에 특별한 파일 시스템은 마운트 할 수 없지만 리눅스의 하드 처리기법의 안정성과 gzip의 무결성을 믿는 다면 안심하고 백업을 해도 될 것이다. 윈도우 파일 시스템 백업 클라이언트 운영체계로 윈도우나 도스를 사용하고 있는 컴퓨터가 여러 대 있으며 비슷한 하드웨어를 사용하지만 하드 디스크의 크기가 서로 다르다면 이미지 백업을 사용할 수 없다. 이미지 백업을 한 하드 디스크가 물리적 에라가 생겼다면 쓸모없는 백업 파일이 되기 때문이다. 이런 경우에는 이미지 백업 보다는 윈도우 파티션을 마운트하여 파일 시스템을 인식한 상태에서 파일 단위와 디렉토리 단위의 백업을 할 필요가 있다. 그렇게 해야 각각의 하드 디스크 용량이 다르더라도 응용 프로그램 세팅까지 끝난 한 개의 윈도우 파일 시스템 백업을 사용할 수 있다. 2기가의 하드 디스크에 윈도우부터 업무용 프로그램까지 인스톨하더라도 초기 상태에서는 500메가 이상을 넘지 않기 때문에 이렇게 만든 마스타 하드 디스크를 백업해 놓으면 윈도우 파일 시스템이 잘못된 컴퓨터를 쉽게 초기 상태로 만들 수 있기 때문이다. 파일 시스템 백업을 하는 방법을 알아보자. 앞에서와 마찬가지로 2기가의 하드 디스크를 1.5기가(C:,/dev/hda1), 500메가(D:,/dev/hda5)로 나누어 사용하고 있다. 작업 디스크로 C:를 백업하는 방법은 다음과 같다. # mount /dev/hda1 /mnt (vfat,fat32일 때 mount -t vfat /dev/hda1 /mnt) # mount /dev/hda5 /mnt2 # cd /mnt # tar cvzpf /mnt2/c-backup.tgz * # cd / # umount /mnt /mnt2 C:와 D:를 각각 mnt와 mnt2에 마운트하고 C:의 모든 파일을 디렉토리 구조와 함께 백업을 한다. tar 프로그램은 /mnt2/c-backup.tgz 파일을 생성하고 전체 파일을 하나의 파일로 만들면서 z 옵션으로 gzip 프로그램을 불러 최종 출력물을 압축한다. tar의 p 옵션은 파일의 퍼미션을 유지하는 것으로 도스의 읽기 전용 파일등에 대한 정보를 유지시켜 준다. 백업한 파일을 이용하여 윈도우 파일 시스템을 초기 상태로 만들기 위해서는 다음과 같이 할 수 있다. # mount /dev/hda1 /mnt (vfat,fat32일 때 mount -t vfat /dev/hda1 /mnt) # mount /dev/hda5 /mnt2 # cd /mnt # rm -rf * # tar xvzpf /mnt2/c-backup.tgz # cd / # umount /mnt /mnt2 C:의 모든 데이타를 지우고 다시 압축을 풀면 된다. 문제는 부팅을 위한 msdos.sys같은 프로그램이 제 위치로 가지 않는 경우가 있는데 이럴 때는 도스 부팅 디스켓을 준비해 sys c: 명령을 내리면 된다. 참고로 두 개의 하드 디스크의 윈도우 파티션을 똑같이 만들기 위해서 cat /dev/hda1 > /dev/hdc1 명령을 쓸 수 있는 경우는 두 하드 디스크가 동일하고 각 파티션의 크기또한 동일한 조건이어야 한다. 만약 두 하드 디스크의 파티션 크기가 다르다면 다음과 같은 명령을 사용하면 된다. # mount /dev/hda1 /mnt (vfat,fat32일 때 mount -t vfat /dev/hda1 /mnt) # mount /dev/hdc1 /mnt2 (vfat,fat32일 때 mount -t vfat /dev/hdc1 /mnt2) # (cd /mnt ; tar cpf - )|(cd /mnt2; tar xpf -) 두 개의 프로세스가 파이프로 연결되어 작업한다. 한 개의 프로세스는 /mnt로 가서 tar 명령이 파일 시스템 구조에 따라 모든 파일과 디렉토리 정보를 보내고 다른 프로세스는 /mnt2로 가서 파이프로 날아오는 데이타를 읽어 파일 시스템에 쓴다. 이 방법이 복잡하면 아래 처럼 간단히 해도 된다. # cd /mnt # cp -a * /mnt2 간단하게 /mnt에 마운트된 파일 시스템 전체를 /mnt2로 복사한다. -a 옵션은 파일 속성 생성날짜등 모든 것을 동일하게 복사하라는 뜻이다. 작업 디스크의 리눅스 커널은 dos, fat, vfat, fat32를 인식할 수 있고 한글 파일명도 제대로 처리하기 때문에 tar나 cp 명령을 바로 사용해도 문제가 없다. 주의 사항 : 리눅스에서 한 파일의 최대 크기는 2GB이다. 요즘 8기가짜리 하드 디스크도 많이 나오고 있지만 아직은 리눅스에서 이렇게 큰 파일 시스템을 한 개의 파일로 백업할 수는 없다. 리모트 백업과 복구 저번 달에 잠깐 언급했던 작업 디스크의 네트웍 기능을 이용해서 윈도우 백업과 복구를 해 보도록 하자. 업체의 클라이언트 PC는 대부분 한 개의 하드 디스크를 갖추고 있고 하드 디스크 전체를 하나의 파티션으로 만들어 쓰고 있다. 이와 같은 상황이라면 리눅스 작업 디스크로 로컬 백업을 하는 것은 또 다른 하드 디스크를 붙이는 복잡한 작업이 필요하게 된다. 랜으로 연결된 다수의 컴퓨터가 있다면 이 중에 하나 쯤은 리눅스를 인스톨 해 놓는 것이 좋다. 파일 서버와 프린터 서버 그리고 백업 서버로 쓸 수도 있기 때문이다. 리눅스의 네트웍 파일 시스템(NFS)이나 samba를 사용하면 쉽게 이런 기능을 구현할 수 있다. 구체적인 내용은 차후에 설명하기로 하고 여기서는 리눅스의 NFS 기능을 이용한 백업서버를 만드는 것과 작업 디스크의 samba 기능을 이용해서 다른 윈도우 박스에 이미지 백업 이나 파일 시스템 백업을 하고 필요할 때 복구하는 방법을 설명하도록 하자. 리눅스의 NFS는 마소 9월호에 제공된 슈퍼 레드헷 인스톨 과정에서 이 기능을 사용하겠 다고 했으면 디폴트로 동작하고 있을 것이다. 동작하지 않는다면 시디롬을 마운트하고 다음과 같이 해주면 된다. # mount /dev/hdc /cdrom # rpm -qpl /cdrom/RedHat/RPMS/nfs-server-2.2beta29-5.i386.rpm # /etc/rc.d/init.d/nfs start nfs 서비스는 파일 시스템 공개 여부에 대한 옵션을 가진다. /etc/exports 파일이 그 기능을 수행한다. 회사내 네트웍에만 리눅스 파일 시스템을 공개하려면 /etc/exports 파일에 다음 내용을 첨가하면 된다. /win 192.168.1.10/255.255.255.0(rw,insecure,all_squash) 리눅스 박스 192.168.1.10이 속한 네트웍 모든 컴퓨터는 이제 /win 디렉토리를 마운트 해서 읽고 쓸 수 있다. 작업 디스크를 이 네트웍이 속한 컴퓨터 중에서 백업을 원하는 컴퓨터에 넣고 부팅한다. 네트웍 카드를 인식하는 과정에 대한 설명은 지난 호를 참고 하기 바란다. 이제 아래 명령으로 네트웍을 인식 시킨다. # ifconfig eth0 192.168.1.20 # route add -net 192.168.1.0 리눅스 백업 박스를 NFS 방식으로 마운트 하고 싶으면 다음 명령을 사용한다. # mount -t nfs 192.168.1.10:/win /mnt2 백업을 위해 또 다른 윈도우 박스를 사용하고 싶다면 다음 명령을 사용할 것. # smbmount //win95com/c /mnt2 -I 192.168.1.30 -U someuser -P passwd 이 두 명령은 모두 네트웍에 연결된 컴퓨터를 /mnt2에 마운트 시킨다. 상대편의 파일 시스템이 NFS와 smb 파일 시스템이라는 차이가 있을 뿐 백업과 같이 파일 한 두개를 처리하고 파일명도 간단히 사용하는 경우에는 아무런 차이가 없다. 단지 속도와 안정성에서 조금 차이가 난다. 리눅스의 NFS 파일 시스템은 신뢰성이 있지만 삼바로 연결된 윈도우 박스에서 백업 작업이 진행되는 중에 다른 작업을 동시에 한다면 문제가 생길 수 있다. 시스템이 백업 작업 도중에 멈추는 등의 사고를 당하고 싶지 않다면 물론 리눅스 박스를 한 개 장만하고 NFS 서비스를 제공하게 하는 것이 좋을 것이다. 이제 하드 디스크 백업을 하자. 다음 명령 중 하나를 사용할 것. # cat /dev/hda |gzip -c >/mnt2/hd-c-img.gz
# mount /dev/hda1 /mnt (vfat,fat32일 때 mount -t vfat /dev/hda1 /mnt) # cd /mnt # tar cvzpf * /mnt2/c-backup.tgz 첫번째 방법은 하드 디스크 전체의 이미지를 백업한 것이고 두 번째 방법은 윈도우 파일 시스템을 백업한 것이다. 백업할 컴퓨터가 몇 개 없고 하드 디스크 크기가 동일 하다면 첫번째 방법이 복구할 때 편하니까 사용할 만 하다. 회사의 컴퓨터가 각기 다른 용량의 하드 디스크를 가지고 있다면 물론 두번째 방법이 훨씬 효율적이다. 복구할 때에는 위의 명령을 반대로 하면 된다. 작업 디스크로 부팅하여 네트웍을 인식시킨 후 아래와 같이 하면 될 것이다. 이미지 백업을 했을 때 (mnt2에 윈도우 박스를 sambamount 했다고 가정) # gunzip -c /mnt2/h-c-img.gz >/dev/hda 파일 시스템 백업을 했을 때 (mnt2에 윈도우 박스를 sambamount 했다고 가정) # mount /dev/hda1 /mnt (vfat,fat32일 때 mount -t vfat /dev/hda1 /mnt) # cd /mnt # tar xvzpf /mnt2/c-backup.tgz 도스로 부팅해서 복구하는 백업 유틸리티는 네트웍 카드를 위한 디바이스 드라이버를 필요로 하고 config.sys와 autoexec.bat 파일을 설정해야 하지만 리눅스에서는 일관된 방식으로 간단히 네트웍을 인식시킬 수 있다. 컴퓨터 파일 시스템이 망가져서 부팅이 불가능한 상황에서는 평소에 쉽게 할 수 있는 작업도 어려운 경우가 많다. 도스 백업 유틸리티를 사용하는 관리자가 네트웍 디바이스를 찾아 다니고 부팅 디스켓을 구하러 다니는 시간에, 리눅스 작업 디스크를 사용하는 관리자는 모든 복구를 끝낼 수 있을 것이다. 하드웨어 안정성 검사 컴퓨터의 호환성은 윈도우 사용 가능성을 뜻하지 않는다. 하드웨어 제작사가 제품을 테스트하는 대상을 윈도우에만 맞추었을 경우에 충분한 테스트가 이루어지기 어렵다. 물론 이 정도의 검사만 있었다면 윈도우에서 조차 예기치 않은 에라가 생길 가능성이 있다. 운영체계는 윈도우만 있는 것이 아니며 다양한 환경에 대한 테스트에 합격한 제품이 윈도우에서도 더욱 안정적으로 돌 수 있는 것이다. 과거 일부 플로피가, 갖추어야 할 최소한의 사양에 미달하여 리눅스에서 사용할 수 없음이 판명된 적이 있었다. 플로피 제작사는 이에 대해 사과하고 제품을 개선해야 했다. 또한 일부 메인보드가 메인보드 규격을 바꾸면서 여러 운영체계를 사용하기에는 호환성이 결여된 제품임이 리눅서들에 의해서 밝혀 진 적도 있다. 현재 사용되는 팬티엄 메인보드 중 일부가 리눅스에서 부팅되지 않는 현상이 있다. 이 것은 리눅스의 잘못이 아니다. 리눅스 커널은 각종 하드웨어 명세에 따라 만들어지기 때문에 리눅스 안정버전이 작동되지 않는 제품은 하드웨어의 이상일 확률이 높다. 어떤 컴퓨터의 하드웨어 호환성을 알고 싶으면 리눅스 디스크를 넣고 부팅해 보면 안다. 부팅화면에서 각종 정보가 나타나며 호환성 없는 하드웨어에서는 부팅조차 되지 않을 것이다. 필자도 윈도우는 잘 동작하지만 리눅스는 부팅조차 되지 않는 메인보드를 몇개 알고 있다. 슈퍼마이크로라는 메인보드는 키보드에 관련된 에라가 있음이 밝혀 졌고 그 회사는 바이오스를 업그레이드해야 했다. 또한 오버클럭킹의 안정성을 검사하는데 리눅스를 사용할 수 있다. 사용자가 일부러 오버클럭킹을 했다면 그 것의 안정성을 시험해 볼 수 있고 구입한 CPU가 리마킹이라고 의심되면 이 것을 조사하는데 사용할 수 있다. 물론 이를 위해서는 작업 디스크만으로는 부족하고 하드디스크에 인스톨해서 엑스윈도우를 띄우고 GCC 컴파일을 해보아야 한다. 리마킹 CPU나 과도한 오버클럭킹을 한 CPU라면 시스템의 불안정으로 리눅스가 다운되는 경험을 할 수 있을 것이다. GCC의 유명한 signal 11 에라는 램의 이상이 있을 때 발생한다. 속도가 다른 모듈램을 사용하거나 안정성이 없는 램을 쓴 제품에서 signal 11에라가 발생한다고 알려져 있다. 초기 AMD K6 CPU는 리눅스 사용자들에 의해서 버그가 있음이 발견되었고 AMD사는 수정 제품을 출시해야 했다. 문제 있는 하드웨어 목록을 알고 싶으면 리눅스 하드웨어 HOWTO 페이지(http://sunsite.unc.edu/LDP/HOWTO/Hardware-HOWTO.html)를 방문해보기 바란다. 윈도우는 운영체계 자체가 안정적이지 못해서 하드웨어 자체의 에라를 발견하지 못하는 경우가 많다. 알려진 버그는 정보에 밝다면 해결할 수 있지만 회사의 특정 제품에서 발생하는 에라는 운영체계의 에라와 함께 발생하며 그 상황이 개별적이라서 그 원인을 알 수 없는 경우가 많다. 이 때 리눅스가 도움이 될 수 있을 것이다. 리눅스가 안정적으로 동작한다면 그 하드웨어는 윈도우를 사용하면서 하드웨어 문제를 걱정할 필요가 없다는 보증수표를 받은 것과 같다. 2.3 그밖의 활용 가능성 리눅스 작업 디스크로 할 수 있는 일은 한정적이지만 상상력을 발휘한다면 여러가지 일이 가능할 것이다. 여러 개의 윈도우 박스를 마운트해서 동시에 이 곳 저곳의 파일 들을 처리하는 등 회사내의 컴퓨터들의 관리를 네트웍으로 편하게 하는 일을 할 수 있을 것이다. 리눅스 프로그램은 아니지만 오픈소스 프로그램으로 fips라는 도스용 유틸리티가 있다. 이 프로그램은 도스의 마스터 파티션을 나누어 주는 일을 한다. fat32 까지 처리할 수 있는 이 프로그램을 사용하면 용량이 큰 C: 파티션을 나누어 C:와 D:로 분리할 수 있다. 같은 작업을 할 수 있는 상용 프로그램으로 파티션매직이라는 프로그램이 있다. 개인적인 용도로 잠시 사용한다면 문제가 없지만 회사에서 업무용 컴퓨터를 대상으로 작업하면서 비용을 지불하지 않고 상용 제품을 사용하는 것은 불법이며 구입해서 사용하기에는 비용부담이 크다. 이제 회사에서도 오픈소스 프로그램을 적극적으로 사용할 때가 아닐까? 물론 리눅스의 하드 디스크 백업기능과 마찬가지로 fips 프로그램도 무료로 구할 수 있다. 자세한 사용법은 마소 9월호에 배포된 슈퍼 리눅스 시디의 dosutils 디렉토리를 참고하기 바란다. IBM에서는 최근에 리눅스를 비롯한 오픈소스 프로그램에 대한 지원을 강화하고 있다. OS/2에서는 리눅스 ext2 파일시스템을 읽고 쓸 수 있고 원한다면 ext2 파일 시스템에 OS/2를 인스톨해서 사용할 수도 있다. 2.2 버전의 리눅스는 fat, vfat, fat32, NTFS(윈도우NT), HPFS(OS/2), UFS(UNIX), SYSTEM V FS, ISO9660(시디롬), QNX FS, MAC FS와 그외 각종 운영체계의 변종들에 대한 지원을 강화하고 있다. 즉 리눅스를 중심에 두면 이 모든 운영체계의 데이타 변환 버퍼로 사용할 수 있다는 뜻이 된다. 왜냐하면 거의 모든 운영체계가 dos의 fat를 지원하지만 fat는 파일명 한계등의 제약이 심하고 맥등은 fat조차 지원하지 않고 있으며 fat를 지원하는 운영체계가 전부 vfat등에 대한 지원을 하고 있지는 않고 있어서 호환성에 문제가 생기기 때문이다. dos를 사용한다고 하더라도 각 운영체계에서 도스쪽으로 데이타를 보낼 수 있지 도스에서 데이타를 가져오는 방법은 사용할 수 없기 때문에 불편하다. 또 lba 모드와 같은 바이오스에서 제공하는 방식을 따르지 않고 각자 하드 디스크를 다루는 방법이 틀려서 다른 운영체계들은 실제 데이타를 주고 받는 버퍼로 사용하기에는 무리가 있다. 파일명 길이에 대한 제한이 없고 거의 모든 운영체계의 파일 시스템을 스스로 인식하는 리눅스가 이런 데이타 변환과 전송 버퍼로 사용하기에 가장 적당하다. 앞으로 더욱 많은 운영체계의 파일 시스템 지원이 추가되면 리눅스를 이 용도로 사용하는 것이 당연한 일이 되는 때가 올 것이다. 필자는 최근에 윈도우의 SDK HELP 파일을 읽어 보아야 할 일이 있었다. HELP 파일이 항목별로 트리 탐색방식으로 되어 있어서 보기가 불편했고 모니터로 설명서를 읽는 것보다는 프린트 해서 읽는 것을 더 좋아했기 때문에 출력을 하고 싶었다. 그러나 WINDOWS HELP 파일을 한 번에 프린터 할 수 없도록 만들어 놓았다는 것을 발견하고는 잠시 실망했지만 오픈 소스 프로그램인 hlp2rtf와 rtf2tex 등을 이용해서 프린트 할 수 있었다. 유닉스(리눅스) 쪽에는 여러가지 문서 포맷 변환툴이 많다. 문서 포맷 변환에 관심이 있다면 유닉스 쪽을 살펴보는 것이 도움이 될 것이다. 리눅스는 서버로서의 역활로써 뿐만 아니라 이렇게 일상 작업에도 윈도우를 도울 수 있는 일이 많다. 구체적인 필요성은 리눅서보다는 오히려 윈도우 사용자가 더 빨리 발견할 수 있다. 윈도우에서 불가능하다고 믿고 있는 작업이 있다면 리눅스쪽을 살펴보기 바란다. 혹시 모르지 않는가? 불가능하다고 믿었던 일이 아주 기본적인 방법으로 해결가능한 일일 수도 있다. 2.4 맺으며 글도 사용하는 운영체계의 영향을 받는 것인지 다른 연재물은 화려한 그림들이 있어서 읽기도 쉽고 보기도 좋지만 리눅스에 관한 글을 쓰는 필자는 그림 하나 없이 글로만 빼곡히 채우다 보니 답답하기도 하고 쓰기도 힘들다. 물론 하드디스크 백업같은 주제로 쓰다보니 그런 면이 더욱 두드러지는 것은 어쩔 수 없지만 리눅스까지 이렇게 칙칙한 것은 아니다. 요즘 리눅스는 잘 꾸미면 윈도우보다 더 화려하게 사용할 수 있다는 것을 알아주기 바란다. 윈도우 사용자들이 많이 넘어오다 보니 화면 인터페이스에 대한 관심이 많아져서 아주 컬트한 윈도우 메니저도 많이 나오고 있고 일관된 인터페이스를 제공하려는 프로젝트도 진행 중이다. 이번 연재는 한 개짜리 리눅스 작업 디스크를 이용해서 백업등을 하는 방법에 대해서 알아보았다. 아무래도 한개의 플로피로 리눅스의 모든 기능을 사용하기에는 역부족이다. 다음 연재부터는 NT를 사용해 회사내의 컴퓨터들에게 인터넷 접속을 제공하고 있거나 그럴 예정인 소규모 회사에서 리눅스 박스를 사용하는 것을 고려해 보도록 관련 정보를 제공하려 한다. 여분의 컴퓨터에 리눅스를 인스톨하고 테스트할 수 있는 환경에 있는 사용자가 적극적으로 이 정보들을 활용한다면 효과가 매우 클 것이다. 독자들의 많은 관심을 바란다. 2.5 이달의 숙제 : 리눅스의 dd 명령어 형식은 다음과 같다. dd if=input_file of=output_file bs=byte_number count=number_of_bs 입력 파일에서 bs가 정해준 바이트 단위의 크기로 count 수 만큼을 출력 파일에 쓴다. 사무실의 컴퓨터가 20대 있고 모두 네트웍으로 연결되어 있다고 하자. 이들은 모두 윈도우를 사용하고 있는데 알다시피 윈도우는 바이러스에 취약하다. 일부 바이러스는 마스터 부트 레코드를 망가뜨려서 부팅이 불가능하게 만드기도 한다. dd 명령과 작업 디스크, 그리고 네트웍을 이용해서 모든 pc의 마스타 부트 레코드를 백업 해 두기 위해서는 어떻게 하면 될까? 2.6 박스 기사 : 리눅스를 배워 보려는 사람들을 위한 조언 한국에서는 마이크로소프트 운영체계가 소규모 회사의 전산화를 위한 최고의 선택이라고 믿고 있는 전산직 종사자들이 대부분인 반면 외국에서는 리눅스의 가능성을 확신하여 이에 대한 지원을 확대하는 경향에 가속도가 붙고 있다. 외국 회사의 한국 지사가 본사와의 네트웍 연결을 위해 윈도우NT를 사용하고자 했으나 본사의 서버가 리눅스 박스여서 지사에서도 리눅스를 사용해야 했던 경우도 있다. 바람은 늘 바깥에서 불어온다. 그 필요성에 대한 장황한 이야기는 하지 않겠다. 아직도 늦지 않았으니 전산직 종사자는 리눅스를 스스로 배워 두는 것이 필수적인 일임을 깨달아야 한다. 개발자와 관리자 그리고 사용자들 중에서 리눅스를 배워야 한다는 자각을 가지고 있는 사람들을 위해서 어떻게 효과적으로 이를 배울 수 있는 생각해 보자. 리눅스는 유닉스임을 기억할 것. 학교에서나 업무에서 다양한 유닉스 제품을 접할 수 있다. 리눅스를 익히는 과정에서 이런 경험이 무척 도움이 된다. 알고 있는 유닉스 명령을 무조건 입력해 보자. 운이 좋으면 경험있는 유닉스에서와 똑같은 반응을 볼 수 있을 것이다. 특정 유닉스에 관한 책이나 정보가 있다면 이를 폐기하지 말 것. 사용해 본 유닉스에 대한 책을 한 번 더 읽고 시작하자. 리눅스의 다른 부분은 실제로 부딪혔을 때 새롭게 파악해도 늦지 않다. 우선 한글 문서부터 읽어 볼 것. 개념이 정확히 파악되지도 않았는데 본격적인 영문 설명서를 들고 있으면 효율이 나지 않는다. 한글 통신의 리눅스 동호회와 유즈넷의 뉴스그룹 그리고 웹에서 제공하는 훌륭한 한글 문서가 많다. 시간이 되면 이들을 정리해서 프린트 해서 읽어도 좋다. 우선 개념을 파악하고 나서야 어려운 영문 메뉴얼을 쉽게 읽을 수 있을 것이다. 영문 문서를 한 개쯤 번역해 볼것. 한글 문서로 개념이 파악이 되었으면 본격적으로 영문 문서를 읽어야 한다. 뭐라고 해도 프로그램 제작자들이 쓴 설명서가 가장 자세한 정보를 제공하기 때문이다. 영문 문서를 읽었으면 후배들을 위해서 설명서등을 써 주는 것이 선배로서 할 일이다. 영문 설명서를 참고해서 한글 설명서를 쓰는 것은 쉽다. 모르는 부분은 건너뛰어도 되기 때문이다. 그러므로 리눅스 문서 프로젝트(LDP)에서 제공하는 각종 가이드, 특정 분야에 대한 HOWTO, 잘 정리된 질문과 답(FAQ)들 중에서 관심있는 것을 선택해서 직접 번역해 보자. 모르는 부분이 하나둘이 아닐 것이다. 모르는 부분을 파악하기 위해 또다른 문서를 참고하는 과정에서 리눅스에 대한 지식이 비약적으로 발전할 것이다. 물론 이렇게 번역한 글을 공개하면 사용자들이 당신의 이름을 기억해 줄 것이고 당신의 질문에 성의있는 답변을 보내올 것이다. 관심있는 부분에 집중할 것. 한글화 문제와 패키지 한글 패치, 멀티미디어 프로그램, 각종 스크립트 언어, 네트웍 설정과 관리 방법, 다양한 엑스 윈도우 메니저와 툴킷 그리고 라이브러리, 하드웨어 디바이스 드라이버, 여러 CPU에 대한 포팅과 프로그램들의 최적화, 날마다 쏟아지는 메일링 리스트의 토론들... 리눅스를 인스톨 하고 나면 엄청난 소스들과 방대한 정보에 묻혀서 헤어날 길이 없다. 차칫 잘못하면 매일 프로그램 컴파일 하다가 시간을 다 보낼 우려가 있다. 새롭게 쏟아지는 프로그램들의 유지 보수는 배포본에 맡기고 관심있는 분야를 설정해서 그 부분에만 집중하는 것이 현명한 일이다. 웹 관련 일을 한다면 공개 웹서버 그리고 perl 같은 CGI 프로그래밍에 대한 것만을 신경쓰기 바란다. 네트웍 서버등에 관심있다면 리눅스와 관련된 네트웍 장비의 디바이스 드라이버와 네트웍 설정 그리고 실제 사용하면서 경험담을 적은 웹페이지등을 조사하는 것으로 족하다. 물론 리눅스를 흥미롭게 생각하고 배우는데 시간을 다 쏟을 수 있는 학생들은 컴파일된 패키지 보다는 프로그램들의 소스를 가져와서 직접 컴파일하고 소스를 조사해 보는 것이 좋을 것이다. 오픈소스 프로젝트에 참여할 것. 통신과 유즈넷에 오늘도 모르는 것을 질문하는 많은 사람들이 있다. 리눅스를 배웠고 어느 정도 알고 있다면 답변을 올리는 것이 예의이다. 전공 분야에 리눅스를 투입할 수 있는 가능성을 보았다면 이 것을 오픈 소스 프로젝트의 한 부분으로 진행하는 것이 좋다. 곧 전세계의 실력있는 프로그래머가 당신을 도와 프로젝트의 성공을 위해 뛰어 줄 것이다. 최근에 필자는 국내 한 업체에서 임베디드 머신을 위한 리눅스 최적화 프로젝트를 진행하고 있다는 사실을 전해 들었다. 이런 유용한 프로젝트는 공개적으로 진행하는 것이 시간적으로나 효율성면에서 좋은 결과를 가져올 수 있을 것이다. 리눅스 박스를 만들 것. 필자는 10여년 전, 운영체계에 관한 책에서 "소스가 필요한 사람은 ftp 로 받아가기 바란다"는 글을 읽은 적이 있었다. 그 소스는 꼭 보고 싶었지만 ftp가 무엇인지 알 수 없었다. 그 때는 국내에서 ftp에 대해 알고 있는 사람이 거의 없을 당시였기 때문에 무려 2년 간을 ftp가 무엇인지 모르고 살았다. 가끔 그 소스를 보고 싶다는 생각을 하면서 유닉스의 ftp관련 설명을 읽고는 했다. ftp에 관한 개념이 없었기 때문에 그에 관해 경험있는 사람을 만날 수 없었기 때문에 시간만 흘러갔다. 그러던 어느날 필자는 IBM-3090에서 아무 생각없이 "ftp ftp"라고 실행해 보았다. 놀랍게도 단말기에 ftp 서버와 연결되었음을 알리는 메세지가 떳다. 여러 설명서를 읽었지만 ftp가 어떤 프로토콜이라고 생각을 하고 있었지 프로그램으로 구현되어 있을 것이라고는 생각하지 못했기 때문에 ftp라는 프로그램이 있는지 조사해보지 못하다가 갑갑한 마음에 정말 아무 생각 없이 명령을 사용해 본 것이다. 필자는 이렇게 인터넷과 첫 접촉을 시작했고 아직까지 거기서 빠져 나오지 못하고 있다. IBM-PC와 윈도우를 분리해서 생각하지 못하는 사람들이 많다. 리눅스도 윈도우와 동일한 운영체계라는 말을 들으면서도 개념적으로는 도스 부팅 후에 실행하는 응용 프로그램이라고 파악하고 있는 것이다. 왜 리눅스 인스톨 시디에 실행 파일이 없는지 물어보는 사람도 있었다. 이런 고정관념이 머리 속에서 붕괴되는 경험을 해야 리눅서가 될 수 있다. 기계 덩어리인 컴퓨터를 장악하는 운영체계는 도스만 있는 것이 아니라는 것을 이해하고 fdisk에 왜 other OS 항목이 있는지를 파악해야만 하는 것이다. 사실 이 것은 매우 어렵고 힘든 일이며 때로 고통스럽기도 하다. 필자가 "ftp ftp"를 실행한 후에 느꼈던 그 느낌, 그때까지 이해할 수 없었던 설명서의 수많은 글들이 한꺼번에, 동시에 그 의미를 전달하며 머리 속을 환하게 만들던 그 깨달음의 순간을 독자들도 느껴보기를 바란다. 리눅스를 어떻게 하면 배울 수 있는가? 그 답은 간단하다. 리눅스를 인스톨하고 직접 원하는 기능을 시험해 보라. 루트에서 "rm -rf *" 라고 쳐봐도 좋다. 프로그램 밖에 더 날아가겠는가? 아무리 많은 문서를 읽어도 실제 경험이 없으면 이해할 수 없으며 재미도 없고 발전적인 생각이 나오지도 않는다. 설명이 무슨 말인지 이해할 수 없을 때, 그 설명이 왜 나와 있는지 알 수 없을 때, 무엇을 질문하고 알아봐야 하는지 조차도 알 수 없을 때, 도대체 내가 모르고 있는 것이 무엇인지도 파악이 되지 않는 때야말로 구석에 쳐박혀 구박받고 있는 낡은 486에 리눅스를 인스톨하고 파티션 날려 가면서 직접 사용해 보는 것이 필요하다. 리눅스를 배우는 가장 쉽고 빠른 방법은 직접 리눅스를 인스톨 해서 사용하는 것이다. 그 외에 무슨 다른 방법이 있겠는가? 박스 기사 : 리눅스 작업 디스크에 대한 몇가지 질문
3. 기업 환경을 위한 리눅스 블랙박스 만들기[3] 리눅서는 어떻게 크는가? (리눅스를 쓰고자 마음 먹은 초보 리눅스에게 주는 조언) 새해가 밝았다. 마소가 리눅스를 전폭적으로 지원하기로 한 축복받은 해가 될 것이다. 업체에서, 학교에서 리눅스를 사용하기로 결정한 초보 리눅스가 어떤 자세를 가져야 하는지 생각해 보기로 하자. 어떻게 하면 리눅스를 자유자재로 사용할 수 있을까? 리눅서가 가져야할 무기는 어떤 것인가? 이런 질문에 대한 대답을 해보기로 하자. 이 글이 이제 막 리눅서로서의 첫 걸음을 시작하려는 독자들에게 도움이 되기를 바란다. 3.1 숙제 풀이 아무리 급하더라도 가장 기본적인 것부터 시작해야한다. 우선 지난달에 낸 숙제 검사 부터 하기로 하자. 숙제는 모두 다 해 왔을 것으로 믿는다. 사무실 컴퓨터 20대의 마스타 부트레코드를 작업디스켓의 dd 명령을 이용해서 백업하는 방법을 물었었다. 우선 바이오스를 백업할 컴퓨터를 정하자. 이 컴퓨터를 biosbk이라고 부르기로 한다. 백업할 컴퓨터에 작업 디스켓을 넣고 부팅한 후에 다음과 같은 명령을 내린다. # ifconfig eth0 192.168.1.20 # route add -net 192.168.1.0 # smbmount //biosbk/c /mnt -I 192.168.1.30 -U someuser -P passwd # dd if=/dev/hda of=/mnt/backup01.dat bs=1 count=512 백업할 윈도우의 랜카드를 활성화 시키고 biosbk의 c:를 /mnt에 마운트 시킨 다음에 마스타부트레코드(MBR)를 파일 형식으로 저장한다. hda는 하드 디스크 전체를 가르키며 처음 512바이트는 MBR이다. 이제 이 컴퓨터의 MBR은 biosbk에 backup01.dat로 저장되었다. 다른 컴퓨터에 한 번씩 작업디스크로 부팅한 다음 backup02.dat, 03.dat로 저장하면 된다. 3.2 작업디스크와 관련된 두가지 사건 작업디스크를 발표하고 나서 필자는 이를 실제로 사용해 볼 수 있는 사건을 만났다. 알고 있는 회사를 방문했을 때 마침 웹서버 교체 작업 중이었는데 웹서버의 용량이 부족해서 하드웨어 업그레이드를 하려고 했을 때 문제가 발생했다. 메인 하드디스크는 쓰던 것을 그대로 붙이려고 했지만 새 하드디스크가 훨씬 빠른 것임을 알고는 이 것을 이용하기로 했는데 문제는 운영체계가 NT라는 것이었다. 새 하드 디스크에 NT를 깔고 웹관련 설정을 다시하고 웹서버 프로그램을 깔고..., 교체할 시간적 여유는 3시간 밖에 없었다. 많은 사람들이 방문하는 웹사이트였으므로 장시간 서버를 정지시킬 수는 없었다. 더구나 성질급한 관리자는 이미 사용 중이던 서버를 끄고 분해를 해 놓았다. 빨리 새 하드 디스크에 NT를 인스톨하는 수 밖에 없었다. 필자는 이 것을 보고 마소 웹사이트에서 작업 디스크를 다운 받은 다음 두 하드 디스크를 연결해 놓고 "cat sda >sdb" 명령을 내렸다. 10분만에 완전히 똑같은 새 하드 디스크를 만들고 웹서비스를 재개할 수 있었다. 두 하드 디스크의 물리적 형태는 다음과 같았다. sda : Disk /dev/sda: 255 heads, 63 sectors, 527 cylinders sdb : Disk /dev/sda: 255 heads, 63 sectors, 543 cylinders 초기 MFM 하드 디스크가 나온 이후에 IDE, EIDE로 넘어 오면서 물리적 하드 디스크를 LBA 같은 논리적 접근이 가능해지면서 서로 크기가 달라도 하드 디스크 단위로 복사가 가능하고 정상적으로 사용할 수도 있게 되었다. 위에서 예를 든 SCSI 하드디스크는 물리단위의 논리접근이 IDE보다 훨씬 추상화 되어 있어서 아무런 문제가 없었다. 참고로 "cat sda >sdb" 명령은 하드 디스크의 MBR 영역을 작은 하드 디스크의 것으로 교체하기 때문인지 리눅스와 NT에서 큰 용량의 하드디스크가 작은 하드디스크의 용량과 같게 보였다. 이를 해결하려면 "cat /dev/zero >/dev/sda" 명령을 사용하면 될 것이다. 물론 데이타는 백업해 놓고 할 것, 하드 디스크가 완전히 초기화 되니까. 필자가 쓰던 노트북 하드 디스크가 수많은 에라 메세지를 뱉어 내면서 죽었다. 백업해 놓지 않은 데이타가 있었으므로 반드시 데이타를 읽어 와야 했다. 두 개 짜리 pcmcia 지원 작업 디스크를 사용해서 다른 리눅스 박스를 마운트하고 파일시스템 백업을 시작 했다. tar cpf /mnt2/linuxbk.tar * 엄청난 에라 메세지를 내면서 하드 디스크가 돌기 시작했고 리눅스박스로 넘어오는 데이타는 분당 10K도 되지 않았다. 하드디스크 리셋을 계속하는 동안 tar 프로세스가 잠깐 동안만 시간을 할당받고 돌고 있었던 것이다. 어떻게든 백업을 해야 했으므로 끝날 때 까지 그대로 두기로 했다. 나중에 AS 받으면서 안 사실이지만 하드 디스크는 물리적 에라가 있었다. 열악한 시스템 위에서 개발이 시작된 리눅스는 이런 물리적 에라에도 불구하고 읽기가 실패했을 경우에 하드 디스크 리셋을 시키고 이 것이 실패하면 다시 수십번을 반복하고 그래도 실패하면 처음부터 그 전체 과정을 다시 수십번 반복하게 되어 있었다. 될 때까지, 읽을 수 있을 때까지, 쓰레기 데이타가 넘어오더라도, 어떻게든 읽을 때까지 반복하는 것이다. 18시간 만에 에라난 부분을 지나고 tar 명령이 정상적으로 진행 되었다. 일부 /usr/bin 파일이 깨어졌기는 하지만 중요한 데이타는 살릴 수 있었다. 로우레벨 포맷 프로그램도 실행 중에 에라가 나면서 중단하는 하드 디스크를 리눅스는 끝까지 읽기를 시도해서 결국 중요 데이타를 살려 주었다. 윈도우 파일 시스템이 에라가 발생 해도 리눅스가 도우이 될 것이다. 정말 중요한 데이타가 있다면 한 번 사용해 볼 것을 권한다. 3.3 리눅서는 어떻게 크는가 이제 초보 리눅서에게 도움이 되는 이야기를 하기로 하자. 무슨 일이든 기본이 있고 원칙이 있다. 이 것을 지킨다면 빨리 그 분야에 적응할 수 있다. 리눅서가 되기 위한 원칙은 어떤 것이 있는가? 오늘도 통신과 유저넷에는 질문들이 쏟아지고 있다. 그 질문의 대부분은 정말 기본적인 내용에 관한 것이다. "fsck는 어떻게 씁니까?", "mount가 무엇입니까?"... 이미 초보를 통과한 리눅서들에게는 황당하게 보이지만, 이런 질문을 하는 사용자들을 나무랄 수는 없다. 윈도우에 익숙한 사용자들에게 아무리 mount의 개념을 설명해도 알아듣지를 못하기 때문이다. 그래서 유닉스(리눅스)의 기본적인 개념이 없는 사용자는 모든 것이 난해하고 복잡해서 조금 용기를 내 보다가 중도하차하게 된다. 리눅서들에게는 형용모순처럼 보이는 질문을 하지 않을 수 없는 윈도우 사용자의 위치를 이해하기로 하자. 필자는 최근에 두 명의 윈도우 사용자에게 리눅스에 대해서 알려 주어야 할 일이 생겼다. 한 명은 윈도우 비쥬얼 프로그래밍을 7년 이상 해 온 개발자이고 다른 한 명은 윈도우 95에서 그래픽을 조금 해 본 초보 프로그래머이다. 이 들에게 어떻게 리눅스에 대해서 설명할 것인가? 이 둘을 만족 시킬 수 있는 한가지 설명 방식을 찾을 수 있을까? RTFM의 진정한 뜻 유저넷을 검색하다 보면 RTFM이라는 문장을 자주 만나게 될 것이다. AFAIK(As Far As I Know), IMHO(In My Humble Option), IIRC(If I Remember Correctly) 처럼 축약된 용어인데 이 말의 뜻을 알고 있는 독자들이 많을 것이다. 그 뜻은 "잘 정리된 설명서를 읽어라"(Read The Fine Manual)이다. 그런데 뉴스 그룹에서 보면 조금 이상한 문장 속에서 이 말이 나온다. 즉 "hey, shit! rtfm!!" 이런 방법으로 쓰이고 있는 것이다. 그 이유를 알아보자. 박스 기사에 나온 것처럼 리눅스를 익히기 위해서 구할 수 있는 수많은 문서가 있다. 그러나 사용자의 대부분은 이런 설명서를 읽지 않는다. 영어가 모국어인 사람들도 이런 지경인데 한글을 쓰는 사용자들은 더 말할 필요가 없다. 이들은 뉴스그룹을 뒤지고 알고 싶은 것이 있으면 그냥 뉴스그룹에 포스팅한다. "이 것을 알려 주세요." 이런 뉴스 때문에 뉴스그룹의 토론이 제대로 이루어지지 않고 수많은 질문 글 사이에서 정보가치가 있는 글이 묻혀 버린다. 거의 대부분의 질문이 FAQ나 HOWTO 또는 LDP 문서에서 찾을 수 있음에도 오늘도 같은 질문이 계속되고 있다. 한 두번 이런 질문에 대해 친절히 대답을 알려 주던 리눅서들이 지치게 된다. 계속되는 질문에 응답하지 않게 되고 질문한 사람들은 왜 대답해주지 않느냐는 글을 올린다. 결국 화난 리눅서는 외칠 수 밖에 없다. rtfm!(read the FUCKING manual), rtfm의 진정한 뜻은 리눅서가 되고 싶으면 "설명서를 읽어라"라는 가장 기본적인 원칙을 무시하는 사용자들을 질타하는 목소리이다. 리눅서가 되고 싶은가? rtfm!!! 어떤 것을 읽어야 하는가? 리눅서가 되려면 메뉴얼을 읽으라는 말을 듣고 그러고 싶어서 문서들을 뒤져보아도 아직 막막할 것이다. 설명들을 하나도 이해할 수 없고 이 책에서는 저 책을 참조하라고 하고 저 책은 다른 것을 참조하라고 하고 그 책은 다시... 초보자에게 메뉴얼을 읽으라는 말은 사전을 통채로 모두 읽으라는 말과 같이 들린다. 언제 사전을 모두 다 읽는단 말인가? 사전을 모두 읽는다고 그 언어를 자유자재로 구사할 수 있는가? 초보 리눅서들에게 필요한 것은 이런 메뉴얼을 관통하는 기본 원리에 대한 설명이다. 리눅스의 기본 원리는 무엇인가? 리눅스는 유닉스다. 그러므로 리눅스의 기본 원리는 유닉스의 기본 원리와 같다. 그렇다면 유닉스의 기본원리는 무엇인가? 그 것은 멀티유저 멀티타스킹 운영체제란 사실이다. 여기서 다시 지루한 유닉스의 특징을 나열하지는 않겠다. 유닉스 개론서 앞부분에 잘 정리되어 있는 내용을 읽어 볼 것. 멀티유저 시스템이란 사용자와 관리자란 계층이 있음을 뜻한다. 멀티유저 시스템을 유지하기 위해서는 관리자가 필요하다. 사용자들의 권한을 제어하고 서비스 해야 할 프로그램들을 정리하는 관리자는 유닉스에 대한 전반적 지식을 가진 사람이 할 수 있는 일이다. 과거 대부분의 유닉스 사용자들은 단말기 앞에서 자기 계정을 가지고 허락된 작업만을 할 수 있었다. 그 때는 유닉스 프로그램 설명서 정도만 가지고 있으면 유닉스를 쉽게 이해할 수 있었다. 복잡한 관리는 할 필요도 할 권한도 주어지지 않았기 때문에 그런 부분은 생각하지 않아도 되었기 때문이다. 그러나 PC에 직접 인스톨 할 수 있는 유닉스 클론들이 나타나면서 유닉스에 전혀 문외한인 사람들에게 유닉스 프로그램 사용부터 시스템 관리까지 모든 것을 한꺼번에 하도록 요구함으로써 아무 것도 할 수 없도록 만들어 버렸다. 리눅스가 더 어려워진 것이다. 유닉스의 경험은 사용자 계정으로 로그인하여 cp,rm등의 명령을 익히는데서 부터 출발한다. 센드메일 설정등의 복잡한 일은 차후로 미루고 가장 기본적인 명령어들에 대한 이해를 먼저 시작하자. I&GSG와 LUG를 들고 ls, cp, vi 명령을 익히자. 시스템 관리는 지금 할 일이 아니다. I&GSG가 너무 단순하다면 유닉스 사용자 설명서를 한 권 구해서 읽으면서 설명되어 있는 프로그램을 직접 실행해 보는 것이 좋을 것이다. 요즘은 자신이 무슨 내용을 쓰고 있는지 확실히 알면서 쓴 책들이 많다. 유닉스 로그인, 셸에 대한 설명, 메뉴얼 페이지 사용법, 모든 명령어가 따르는 일반 형식, 네트웍 관련 사용자 프로그램들, 파이프와 필터, 파일의 처리, vi 사용법, 파일 시스템에 대한 이해, 유저넷과 뉴스그룹등등.. 유닉스 사용자 권한으로 할 수 있는 것이 많고 이 것을 제대로 익히면 시스템 관리도 어려운 것이 아니다. 시스템 관리를 위해서는 LSAG가 필요하다. 이제 /etc 디렉토리를 관리해야 한다. 또한 리눅스 파일 시스템 표준(FSSTND)에 대한 이해를 해야 할 때이다. 모든 관리자용 프로그램은 /bin, /sbin, /usr/sbin, /usr/bin에 있고, 설정 파일은 /etc에, 로그는 /var/log에, 각 개인별 설정파일은 /.xxxrc 형태로 두는 것, 비표준 패키지는 /usr/local 아래에 인스톨 된다는 것, /var, /tmp, /usr, /etc, /lib 등의 디렉토리가 왜 만들어져 있고 어떻게 이용되는지 이해하게 될 것이다. 특정 프로그램이 실행되면서 어떤 파일을 참고하는지 알고 싶으면 다음과 같이 실행해 볼 것. 프로그램이 리눅스 시스템 안에서 어떤 함수를 호출하고 어떤 파일들을 열고 읽는지 한 눈에 볼 수 있다. # strace vi 2>a # less a 파일 시스템 표준과 필터 프로그램에 대해 익히고 기본 에디터를 제대로 사용할 수 있다면 이제 설정 변경을 할 수 있다. /etc/hosts, /etc/exports 파일등을 다룰 수 있을 것이다. /etc 아래의 파일들은 메뉴얼 페이지가 있다. "man exports"라고 하면 그 파일의 형식을 자세히 보여 줄 것이다. 물론 이 파일이 어디에 쓰이는지는 파악을 해야 한다. 메뉴얼 등에서 이 파일이 쓰이는 곳을 찾아 보던지 "rpm -qf /etc/exports"라고 쳐서 이 파일이 어느 패키지에 속하는지 확인하고 그 패키지가 하는 일은 무엇인지 파악해도 된다. 많은 설정파일에 있듯이 "당신이 무슨 일을 하고 있는지 알지 못한다면 손대지 말것". 이제 본격적으로 /etc/rc.d 아래의 파일을 손보자. 이 디렉토리에는 리눅스가 기동 되면서 필요한 작업을 하도록 되어 있는 곳이다. 지금 "ps axf"라고 실행해 보면 알 수 없는 프로그램들이 떠 있을 것이다. 쓰지도 않는 nfs, autofs, gpm등의 데몬이 떠 있다면 이들은 모두 /etc/rc.d/init.d 아래에서 찾을 수 있다. 어떤 데몬인지 확인하고 필요한지 여부를 판단한 다음 필요없다면 지워도 된다. 각 데몬들은 도스의 램상주 프로그램처럼 메모리를 낭비하고 있으므로 이 데몬들을 정리하면 컴퓨터의 반응이 훨씬 빨라질 것이다. 필자가 만난 한 유닉스 관리자는 인디고를 관리하고 있었는데 사용자가 컴퓨터가 잘 작동하지 않는다고 하면 6개짜리 인스톨 CD를 모두 재설치하는 것을 본 적이 있다. 256M의 메인메모리를 쓸데 없는 데몬이 모두 점유해서 정작 사용자가 띄운 그래픽 프로그램은 쓸 수 없을 정도로 느리게 실행되었다. 사용자는 컴퓨터가 후지다고 본체를 발로 차며 사용하고 있었다. /etc/rc.d/ 디렉토리를 마음대로 고칠 수 있다면 이제 스스로 리눅서라고 생각해도 좋다. 웬만한 설정을 할 수 있고 감을 잡았다면 구체적 문제를 위해서 HOWTO 문서를 읽으면서튜닝을 하자. 백여개의 HOWTO 문서를 참고한다면 못할 일이 없다. 고정된 IP를 할당 받을 수 있다면 웹서버와 네임서버를 설치해서 사용해 보고 센드메일을 사용해서 메일을 내 컴퓨터에서 받아보기도 하자. 학생이라면 이제 프로그래밍에 눈을 돌릴 때이다. 커널부터 라이브러리 소스까지 가능하면 이들을 뒤져 볼 것. 버그를 발견했거나 성능을 향상시킬 방법을 알았다면 오픈소스 프로젝트에 참가해도 좋다. 어떻게 읽어야 하는가? 다시 처음으로 돌아가자. 유닉스 개론서를 읽고 가이드를 보고 HOWTO를 보면 리눅서가 될 수 있다. 참 좋은 말이다. 그런데 여기에도 문제가 있다. 예를 들어 ipfwadm이라는 프로그램을 이용해서 IP-Masquerade를 하고 싶다. HOWTO 문서도 있지만 모든 것을 설명하고 있지는 않다. 그래서 스스로 "man ipfwadm"으로 사용법을 익히려고 한다. 슈퍼 레드헷에는 한글로 된 메뉴얼 페이지가 나온다. 그러나 각각의 옵션에 대해서만 설명하고 있으며 이 설명도 잘 이해되지 않고 옵션들간의 연관관계에 대한 정확한 지침이 없다. IP-Masquerade mini HOWTO에는 다음과 같이 사용하라고 나와 있다. #ipfwadm -F -a m -S yyy.yyy.yyy.yyy/x -D 0.0.0.0/0 yyy..에서 출발한 패킷을 x로 마스크해서 문제가 없으면 모든 주소(-D)로 masquerade해서 보내라는 옵션이다. 그런데 메뉴얼페이지 어디에도 -a 다음에 m을 사용하는 이유를 설명해 놓지 않고 있다. 그러므로 ipfwadm을 사용해서 masquerade를 할 수 있다는 것을 알아내고 메뉴얼페이지를 아무리 읽어도 이 것을 할 수 없는 것이다. 이 문제를 어떻게 해결할 것인가? 마찬가지로 셸프로그래밍을 하면서 이 셸스크립트가 600초 후에는 스스로 끝내게 하는 기능을 넣고 싶다. 셸 스크립트 언어에는 전역변수로 SECONDS가 있다. 셸스크립트가 기동하면서 이 것을 0으로 초기화 시키면 그 때부터 1초마다 값이 증가한다. 이 값을 저장한 후에 나중에 비교해 보면 600초 후에 셸스크립트를 끝낼 수 있다. 그런데 bash 의 메뉴얼 페이지는 3960줄이다. 언제 이 설명서를 다 읽는단 말인가? 그리고 읽더라도 이 변수를 이런 용도로 사용할 수 있음을 어떻게 안단 말인가? bash 메뉴얼의 SECONDS 부분의 설명은 다음과 같다. SECONDS Each time this parameter is referenced, the number of seconds since shell invocation is returned. If a value is assigned to SECONDS, the value returned upon subsequent references is the number of seconds since the assignment plus the value assigned. If SECONDS is unset, it loses its special properties, even if it is subsequently reset. 영어를 모국어로 사용하는 사람들도 이해하기 힘든 이런 설명을 보고 어떻게 이 변수의 용도를 짐작할 수 있을까? 그러므로 아무리 설명서를 읽어도 조금도 이해되지 않고 읽을 수록 머리만 복잡해질 뿐 리눅스를 사용하거나 관리하는데 도움이 되지 않는다. 셸프로그래밍에 대한 책도 나와 있지만 간단한 작업을 하기 위해 이런 책을 사서 읽는 다는 것은 낭비일 뿐이다. 셸프로그래밍 책을 보면 셸스크립트 언어만을 설명한 것이 아니라 필터 프로그램의 조합에 대한 설명이 더 많다. 또다시 필터 프로그램의 메뉴얼페이지를 읽어야 한다. 셸프로그래밍 책에서 셸스크립트의 한계를 지적하며 궁극적으로는 perl을 사용하라고 권한다. 공식 perl사이트인 http://www.perl.com에서 제공하는 perldoc 문서는 1256페이지에 달한다. perl 문서를 읽는다고 perl에 대해서 정통해 질 수 없다. perl로 짠 암호화 같은 스크립트 파일들은 그 내부를 들여다보고 한 줄 한 줄 분석해야 무슨 일을 하는지 알 수 있다. 원하는 일을 위해 perl로 스스로 프로그램을 짜는 것은 또다른 문제이다. 이렇게 얼키고 설켜있는 문서와 문서사이에서 중심을 잡고 개념을 파악하려면 어떻게 해야 할까?
결국에는 스스로 해야 한다. 리눅서가 되기 위해서 읽어야 할 문서와 그런 문서를 읽는 방법과 자세에 대해서 설명 했다. 웬만한 일은 훑어 본 문서를 다시 참고하면 해결할 수있다. 그러나 정작 필요한 부분에서는 문서들이 크게 도움을 주지 않는다. 박스기사에 예를 든 eql에 대한 것도 유저넷에 질문만 넘쳐 날 뿐 쓸만한 답변은 없다. 혼자서 eql을 세팅할 수 있었다고 해도 크게 쓸모가 없다. 왜냐하면 결정적으로 eql 디바이스가 한 개만 제공된다는 것이다. 전용선 업체에서 여러 가입자에게 서비스 할 수 없는 일에 신경을 쓸 이유가 없기 때문에 실제로 사용해 보기는 힘들 것이다. 전용선 업체에서 이 기능을 사용하여 가입자 수를 늘이고 싶으면 커널 디바이스 드라이버를 고쳐야 한다. drivers/net/eql.c를 고치면 되지만 누가 해 주겠는가? 당신 밖에 없다. 외국에서는 이미 사장된 디바이스가 되었기 때문에 아무도 손을 대지 않을 것이다. 이 것을 고쳐서 동작하게만 한다면 경쟁업체보다 훨씬 기술적 우위를 점할 수 있으니까 한 번 도전해 보기 바란다. 리눅스는 이렇게 스스로 하는 사람들이 만들어 왔다. 커널-메일링-리스트 FAQ에 보면 아직 만들어지지 않은 디바이스 드라이버를 어떻게 만들어야 하는가에 대한 답변이 있다.
리눅서가 되자. 필자가 본 리눅서들은 거의 해커기질이 있었다. 윈도우에서 자주 사용하는 프로그램의 기능을 고쳐쓰거나 스스로 만들어 쓰는 프로그램을 가지고 있었다. 그런 프로그램의 질을 따질 필요는 없다. 컴퓨터를 만지면서 문제의식을 가지고 스스로 해결해보고자 하는 자세가 중요하다. 리눅스 박스를 만들고 도전해 보자. 문제를 자신이 해결할 수 있기까지 얼마나 걸릴까? 리눅스만 하루 종일 한다면 2년 정도면 될 것이다. 조급하게 생각하지 말 것. 여유를 가지고 도전하자. 오픈소스 공동체에 참가하여 리눅스를 즐기다보면 어느새 시간이 지나고 당신은 실력있는 리눅서가 되어 있을 것이다. 리눅서는 어떻게 크는가? 현상태에 안주하지 않고 스스로 문제의식을 가지며, 업체에서 기능을 추가해 줄 때까지 기다리지 않고 자신이 기능을 추가하며, 다른 리눅서가 만든 문서를 완전히 소화하고 스스로 또 하나의 문서를 만들어 내며, 불가능해 보이는 것을 현실로 만들어내면서 큰다. 이달의 숙제 슈퍼레드헷 리눅스에는 vi의 클론인 vim이 들어 있다. 기본 탭 설정이 8로 되어 있어서 이것을 4로 바꾸고 싶다. 어떻게 하면 될까?. 슈퍼유저라고 가정하고 /.vimrc를 쓰지 않는다고 하자. vim 안에서 설명읽는 법, tab과 관련된 문자열 찾는 법, 그리고 strace가 필요하다. 3.4 박스 기사 : 리눅스 문서들 리눅스는 한 업체에서 만들지 않기 때문에 출판되어 나오는 공식 문서는 없다. 이런 문제를 해결하기 위해서 LDP(Linux Document Project)가 시작되어 현재 발표된 문서는 초보자를 위한(I&GSG), 커널 해킹을 위한(KHG), 알파포팅을 맡은 팀이 직접 쓴 리눅스 커널 구조설명서(TLK), 네트웍 관리자를 위한(LNAG), 프로그래머를 위한(LPG), 시스템 관리자를 위한(LSAG), 컴파일러등의 사용법에 관한(LUG) 등이 있다. 이 문서들은 sgml 포맷으로 만들어져서 tex, postscript, html로 배포되고 있으므로 원한다면 프린트 해서 보면 된다. 각 문서는 개괄서적인 면이 강하고 구체적인 사항에 대해서는 자세하게 언급되어 있지 않기 때문에 전반적인 개념을 잡는데는 도움을 주지만 특정 문제를 해결하는 데는 큰 도움이 되지 않는다. 그러나 이 문서들을 보지 않고는 결코 리눅서가 될 수 없다. 반드시 숙독을 해야 한다. 유저넷에 올라오는 질문의 90% 이상은 LDP 문서에서 그 답을 찾을 수 있다. LDP 문서는 리눅스를 다루는 지도가 되기 때문에 꼭 읽어 볼 것을 권한다. 이 중에서 번역된 것은 I&GSG, LSAG, LPG, TLK, LNAG,등이 있다. 한글 번역판은 리눅스 한글 문서 프로젝트 사이트(http://kldp.linux-kr.org)에서 구할 수 있다. 이 사이트에서는 그밖에도 한글로 되어 있는 많은 문서를 구할 수 있다. 리눅서라면 여기서 제공하는 문서를 반드시 모두 읽어 봐야 한다. 특정한 문제를 해결하고 싶을 때는 어떤 문서를 참고해야 할까? LDP 프로젝트는 이와 관련해 HOWTO 문서를 제공한다. HOWTO는 NET-3-HOWTO 처럼 리눅스의 네트웍 장치의 종류와 사용법에 대한 개략적인 설명을 한 문서가 있고 DNS-HOWTO 처럼 NET-3-HOWTO에서 간단히 언급된 네임서버 구축을 위해서 어떻게 해야 하는지 구체적으로 설명한 문서가 있으며 mini/Mail-Queue 처럼 팁 성격이 강한 간단한 문제에 대한 해결책을 담은 문서가 있다. 이들의 최신 문서는 http://sunsite.unc.edu/LDP에서 구할 수 있고 비교적 최신 문서는 당신의 하드 디스크에 있다. /usr/doc/HOWTO를 뒤져보기 바란다. 물론 이들 문서 중 일부는 번역되어 있다. /usr/doc/HOWTO/translations/ko를 뒤져볼 것. 번역이 추가되었다면 klpd사이트에 올라와 있을 것이다. 여기서 도움을 받았다면 klpd 사이트 관리자에게 감사편지를 보내는 것을 잊지 말기 바란다. 이들 문서에서도 문제를 해결하지 못했다면 어떻게 해야 할까? 직접 프로그램의 메뉴얼 페이지를 조사해 보자. /usr/man 아래에 있는 수많은 설명서를 지나쳐서는 안된다. /usr/man/whatis 문서는 각 메뉴얼페이지가 어떤 용도로 쓰이는지 간단히 설명되어 있다. 여기를 조사해 보면 원하는 목적에 필요한 프로그램을 찾을 수 있다. 메뉴얼 페이지를 구동할 때는 가능한 -a 옵션을 사용할 것을 권한다. 예를 들어 chroot 라는 프로그램은 3개의 설명서가 있다. C 함수로 쓰일 때, 프로그램 명령 설명(영문,한글) 등이다. -a 옵션을 쓰고 :q 명령을 쓰면 다음 메뉴얼 페이지를 보여 준다. whatis로 충분하지 않으면 아래 명령으로 메뉴얼 페이지를 다 뒤져도 좋다. 내가 원하는 문제와 연관이 있는 단어가 들어 있다면 그 설명서 이름을 보여 줄 것이다. /usr/man# grep "my_problem" */* 메뉴얼페이지가 부족하다면 각 프로그램에서 제공하는 설명서가 있다. /usr/doc 아래를 뒤져보면 각 프로그램을 만든 제작자가 사용법이나 주의점에 대해서 쓴 파일을 찾을 수 있다. 좀 더 구체적인 설명서를 원한다면 /usr/info를 뒤져볼 것. info 라는 프로그램을 실행하면 이 디렉토리에 대한 지도를 보여 주고 방향키를 사용해서 조사해 볼 수 있도록 하고 있다. 이 문서들은 GNU/texinfo 파일 형식으로 된 것을 변환한 것이다. html 처럼 하이퍼텍스트이므로 원하는 주제를 찾아 검색할 수 있다. 프로그래머라면 컴파일러 툴과 라이브러리 레퍼런스가 필요할 것이다. GNU GCC가 사용하는 라이브러리의 함수 목록과 사용법은 어떻게 알 수 있을까? /usr/info/libc-info.gz를 읽어보면 된다. 늘 참조하는 문서이므로 프린트해서 보고 싶다면? GNU 미러 사이트(예를 들어 ftp.kreonet.re.kr:/pub/gnu)에서 gnu-libc 소스 파일을 가져와서 configure; make 하면 libc.dvi라는 파일을 만들어 준다. 이 문서는 libc reference manual로서 약 700페이지 정도 되므로 dvips와 psutil(ftp://sunsite.unc.edu/pub/Linux/apps/wp)의 psnup을 사용하여 압축양면 인쇄를 할 수 있다. GNU 프로그램 중에서 make, GCC, library, bison(yacc), flex(lex), gas(assembler), gdb(gnu debuger)등의 소스파일에는 texi 원본 파일이 있으므로 이들을 프린트하면 된다. 설명서를 이해하기 힘들거나 활용예가 부족해 문제를 해결할 수 없다면 유저넷이나 통신에서 제공하는 문서를 참고할 수 있다. ftp://rtfm.mit.edu에는 유저넷의 모든 뉴스그룹에서 제공하는 FAQ를 보관하고 있다. 리눅스 관련 뉴스그룹은 comp.os.linux. 아래에 수도 없이 많으며 각 나라마다 따로 자기 나라 언어로된 뉴스그룹을 운용하고 있다. fr.comp.os.linux 등과 같은 것들이다. c.o.l. 이하에서 현재 발생하는 문제나 해결책을 구할 수 있을 것이다. 영어를 쓸 수 있다면 질문을 해도 된다. 질문이 자세하고 공손하다면 전세계의 해커들이 답을 줄 것이다. 유저넷의 한글 그룹에는 부족하나마 한글과 한국적 상황에 대한 설명을 찾을 수 있다. han.comp.os.linux, han.comp.mail 등의 그룹을 검색해 볼 것. 한국의 리눅스 해커들을 여기서 찾아 볼 수 있다. 리눅스는 해커 문화가 뿌리 깊어서 실력으로 존경받는 경향이 강하다. 여기에서는 메뉴얼을 뒤지면 간단히 해결할 수 있는 문제나 "컴파일이 안돼요" 같은 황당한 질문이나 "센드메일을 컴파일하는 자세한 방법을 조목조목 알려 주세요" 같은 건방진 질문만 하지 않는다면 이들 해커로 부터 큰 도움이 될 대답을 들을 수 있다. 리눅스 해커들은 자신의 시간을 들여서 대답을 해 주기를 즐기고 이 과정에서 자연스럽게 실력이 드러나기 때문에 존경을 받게 된다. 뉴스그룹을 만들 만큼 주제가 크지는 않지만 활발히 활동하는 사람들은 메일링리스트를 운용하고 있다. 여기서는 현재 만들고 있는 프로그램의 버그, 패치, 구체적 사용법, 성능개선등에 대한 토론이 올라온다. 뉴스그룹에 가입하는 방법은 메일링리스트에 일정 양식의 메일을 보내면 되지만 이 것이 복잡하다면 http://oslab.snu.ac.kr/ djshin/linux/mail-list을 방문해 보기 바란다. 리눅스와 관련된 메일링리스트에 가입/탈퇴를 웹방식으로 편하게 할 수 있다. 메일링 리스트를 가입하면 그 때부터 도착하는 메일을 읽어 볼 수 밖에 없어서 이전에 어떤 문제가 토론되었는지 알 수 없다. 그래서 각 메일링 리스트는 지난 메일을 보관해 놓는 곳이 있다. 예를 들어 http://www.tux.org/hypermail/ 아래에 가면 리눅스 커널 메일링 리스트와 여러 다양한 관련 메일링 리스트가 주제별로 저장되어 있다. 여기 뿐만 아니라 웹을 검색해 보면 수많은 메일링리스트 어카이브 사이트를 찾을 수 있다. 한국의 리눅스 통신 동호회에도 많은 질문과 답이 올라와 있다. 거의 기초적인 설치에 관한 것이지만 그 중에서 쓸모있는 답변도 많다. 특별한 문제의 근원적인 해결은 볼 수 없지만 다른 정보를 찾아 갈 수 있는 정보는 얻을 수 있다. 통신에서 lt 명령을 적극 활용하기 바란다. 번역글이나 강좌등이 통신에 먼저 올라오는 경우가 많기 때문에 강좌란은 늘 검색해 볼 필요가 있다. 리눅스와 관련된 정보들은 리눅스의 성격에 영향을 받아서 거의 공개로 제공하고 있고 답변을 올려 주는 사람들도 댓가를 바라지 않는다. 인터넷의 수많은 웹사이트에서 자신이 알고 있는 팁을 올려 놓은 사이트가 엄청나게 많다. 이들은 방문 카운트가 증가되는 것을 기뻐할 뿐 여기서 어떤 이익을 얻으려고 하지는 않는다. 정보를 유용하게 사용했다면 감사 편지를 보내는 것은 기본 예의일 것이다. 개인 홈페이지로 한국에서 유명한 사이트는 프로그램 한글화의 최전방에 서 있는 최준호씨(http://jazz.snu.ac.kr/ junker), 적수라는 별명으로 더 알려진 김병찬씨(http://www.linux.sarang.net), 한글 프로그래밍의 원칙을 세우고 있는 신정식씨(http://pantheon.yale.edu/ jsin), 센드메일과 한글 메일에 대한 완벽한 해결책을 제시하는 이상로씨(http://suny.mutli.co.kr/ leesl)등이 있다. 여기서도 문제를 해결할 방법을 찾지 못했다면 인터넷 검색사이트를 이용해도 된다. 아마 검색어가 포함된 수많은 사이트를 모두 방문하지도 못할 것이다. 수많은 리눅스 관련 정보는 인터넷의 거의 대부분을 차지하고 있다. 그러나 이런 정보들은 거의 프로그램 사용법이나 활용에 대한 것들이다. 문제는 가장 기본적인 지식을 가져야 활용 정보를 사용할 수 있다는 것이다. 당면한 긴급한 문제만을 해결하기만 하면 그만이라면 이런 정보들만을 이용해도 좋다. 그러나 네트웍 프로그래밍을 하면서, 게가 그려진 책을, 센드메일 프로그램을 이용해서 대규모 메일을 관리하면서 박쥐가 그려진 책을 한 번도 읽어 보지 않았다면, 언젠가는 무너질 모래성을 쌓는 것이다. 수많은 정보가 널려 있어도 가장 원칙적인 것은 기본서를 숙독하는 것이다. 가이드, 설명서, 뉴스그룹에서 결국 마지막 레프런스로 참조하라고 하는 책을 사지 않고는 버틸 수 없다. 오늘 퇴근 후에 서점에 들러 보는 것은 어떨까? 3.5 박스 기사 : EQL을 설정하자 야간정액제, co-lan, ISDN, 호스트접속 방식랜등이 있지만 시간제한과 비용 때문에 별 소용이 없고 케이블 통신, ADSL등의 미래지향적인 서비스는 지역적 한계로 이용할 수 없는 경우가 많고 아직 활성화 되어 있지도 않다. 현재 개인 사용자가 사용할 수 있는 네트웍으로는 TT라고 불리는 전화급 전용선이 최선의 선택이다. TT의 문제는 전화국의 교환기가 음성정보만을 다루도록 필터링을 하기 때문에 서버쪽에 고가의 모뎀을 설치하지 않으면 33.6K 이상의 접속은 이루어지지 않는다. 33.6K 속도로는 원활한 네트웍 작업을 하기에는 무리가 있다. 그래서 나온 대안이 EQL이다. EQL은 ppp로 접속된 TT선을 두 개 이상 붙여서 속도를 증가시키는 목적으로 사용할 수 있다. 그러나 리눅스 커널에 이 기능이 포함되어 있음에도 관련 문서가 거의 없다. EQL에 대한 문서는 NET-3-HOWTO, /usr/src/linux/drivers/net/[README.eql,eql.c], ftp://ftp.kreonet.re.kr/.1/Linux/sunsite/system/network/eql-1.2.tar.gz 뿐이다. 뉴스그룹과 서치엔진에서 eql을 넣어 보았지만 여기서 제시하는 문서 이상의 내용이 있는 것은 보기 힘들다. 이 문서에서는 뭐라고 얘기하고 있을까? ppp,slip으로 연결된 회선을 두개 이상 붙이고 eql을 사용하면 1개 선로 보다 89% 정도의 속도 증가를 가져올 수 있다. 서버쪽에 멀티링크를 지원하는 하드웨어를 사용하거나 리눅스 박스가 있으면 된다. TT선을 사용하는 사람들에게는 아주 매력적인 것이지만 문제는 외국에서는 이미 개인 전용선들이 충분히 빨라졌는지 95년 이후로 더 이상의 정보는 나오지 않고 있다. 또한 설명서에 있는 대로 해도 로드 밸런싱이 되지 않는다는 문제가 있다. 마지막으로 서버 쪽은 리눅스가 아닌 멀티링크 지원 하드웨어를 가정하고 있다는 것이다. 이 문제를 해결해 보자. eql은 다음과 같이 구성된다. - server ppp0(slave) --tt-- client ppp0(slave) - server eql { } client eql 168.126.153.3 - server ppp1(slave) --tt-- client ppp1(slave) - 168.126.153.112 서버에서는 접속을 받아 들일 때 패킷의 경로를 재설정할 수 있도록 헤더 압축기능을 제거하고 ppp 연결을 시킨다.(novj 옵션 사용) 서버측에서는 접속을 받아 들인 후에 다음 스크립트를 crontab에 넣고 실행시켜 주도록 하면 된다.
#!/bin/sh
export PATH="/bin:/usr/bin:/sbin:/usr/sbin"
# route table에 eql이 없으면 추가한다.
if [ `cat /proc/net/route |grep "70997EA8" |grep -c "eql"` -eq 0 ]; then ifconfig eql down ifconfig eql 168.126.153.3 mtu 1500 route add -host 168.126.153.112 eql fi
# 70997ea8 IP가 없으면 ppp 가 처리되었거나 아직 ppp가 접속을 # 하지 않은 것이므로 끝낸다.
if [ `route |grep "168\.126\.153\.112" |grep -c "ppp"` -eq 0 ]; then exit fi
# 새로 ppp 접속이 만들어졌다. 이를 slave 로 바꾸고 route 테이블에서 # 제거한다.
for i in `route |grep "168\.126\.153\.112" |grep "ppp" | awk '{print $8}'` do /root/bin/eql_enslave eql $i 33600 route del 168.126.153.112 dev $i done
168.126.153.112를 할당받은 ppp[0,1] 디바이스를 eql의 슬레이브 장치로 만든 후에 라우트 테이블에서 제거하고 eql에 host ip를 할당하면 168.126.153.112로 오는 패킷은 모두 eql이 받아서 ppp0과 ppp1 에 적절히 할당한다. 지금 설명은 쉽게 보이지만 서버에서 "route add default eql" 명령을 내리는 순간 TT서버로 접속한 모든 사용자가 외부로 나갈 수 없었다. 사용자의 항의로 전화통에 불이 나는 순간이었다. 설명서에는 eql을 호스트로 만들라는 설명이 없었고 자동으로 eql을 사용하는 ppp 디바이스를 찾아 줄 방법을 연구하느라 서버 관리자와 머리를 싸매야 했다. 수 십개의 전용선이 접속되어 있는 서버의 루트권한을 쓸 수 있도록 해 준 소사벌넷의 손정현씨에게 감사할 뿐이다. 클라이언트 쪽에서는 다음과 같이 하면 된다. # ifconfig eql 168.126.153.112 mtu 1500 # route add -host 168.126.153.3 eql # eql_enslave eql ppp0 33600 # route del 168.126.153.3 ppp0 # eql_enslave eql ppp1 33600 # route del 168.126.153.3 ppp1 서버와 클라이언트 모두 eql이 두 개의 ppp 라인을 감추고 자신이 호스트인 것처럼 위장한 다음 주고 받는 모든 패킷에 대해서 경로 설정을 새로해서 로드 밸런싱이 제대로 되었다. 다음 명령으로 양쪽 모두 패킷을 분리해서 주고 받는 것을 확인할 수 있다. # cat /proc/net/dev Inter-| Receive | Transmit face |packets errs drop fifo frame|packets errs drop fifo colls carrier eql: 0 0 0 0 0 11744 0 292 0 0 0 ppp0: 2042 0 0 0 0 2277 0 0 0 0 0 ppp1: 1519 0 0 0 0 2822 0 0 0 0 0 메뉴얼에도 없고 유저넷에도 사용해 본 사람들의 경험담이나 설명서가 없는 상황에서는 된다는 가능성을 믿고 스스로 해야 한다. 위에서 /proc/net/dev, /proc/net/route,를 이용하는 방법, eql을 게이트웨이가 아닌 호스트로 만들어 보는 시도, crontab의 사용, 셸스크립트 만들기등은 모두 조각난 지식이다. 이들을 엮어 내는 방법을 생각해 낼 수 있는 것은 당장 필요하지 않더라도 평소에 이들 프로그램의 설명서를 한 번 쯤 읽어 본 적이있고 가능성이 있다면 어떻게든 되게 해야 한다는 필요성이 있었기 때문이다. 이래도 안된다면 어떻게 하겠는가? 뭐가 문제란 말인가? 로드밸런싱에 대한 개념이 존재하고 TCP/IP 자체에서 패킷 경로 변경을 지원하고 eql.c 소스가 있지 않은가? 바로 당신이 이 것을 뜯어 고쳐서 한국적 상황에서 가장 효율적으로 네트웍을 사용할 수 있도록 기여하면 되지 않는가? 문제는 마음자세와 실력일 뿐이다. 4. 기업 환경을 위한 리눅스 블랙박스 만들기[4] 4.1 윈도우에서 리눅스를 제어한다. 이번 달 부터 리눅스를 블랙박스로 두고 각종 설정을 윈도우에서 하면서 사용하는 방법에 대해서 설명한다. 리눅스에 대한 지식을 가지고 있으면 좋지만 그렇지 못해도 상관없다. 정전이 되어서 리눅스박스가 부팅불능으로 빠지는 등의 문제가 생기면 다르겠지만 일반적인 상황에서는 리눅스에 대한 지식이 별로 요구되지 않는다. 리눅스를 사용한다고 해서 어려운 유닉스 명령을 모두 익혀야 하는 일은 이제 별로 없을 것이다. 이 글에서는 가능한한 유닉스로 하는 작업을 배제하고 웹이나 그래픽유저 인터페이스로 문제를 해결 할 방법을 찾아 보겠다. 리눅스에 접근하는 것도 윈도우박스에서 telnet을 사용하기로 하자. 리눅스박스는 서버로 사용하게 되면 모니터와 키보드가 거의 필요가 없다. 사무실의 한쪽 공간에 본체를 두고 그 존재를 잊어도 된다. 이 번달에는 윈도우에서 리눅스 제어에 대한 기본을 익히는 과정으로 보고 리눅스를 윈도우의 파일서버로 사용하는 방법을 알아 보자. 4.2 숙제 풀이 vi의 클론 vim은 vi의 기본 기능에 충실하면서도 편리한 기능들이 많이 추가되어 있다. 프로그램을 코딩하다보면 들여쓰기가 깊어져서 소스가 보기 힘들어 질 때가 많다. 기본 탭의 크기가 8로 되어 있는데 이 것을 4로 바꾸어 보자. vim의 설정에 관한 사항과 특별히 탭에 대한 사항은 ":help<enter>/tab<enter>"로 찾을 수 있다. 여기에 보면 ":set tabstop=4"로 해결을 할 수 있음을 알 수 있다. 물론 이렇게 하면 vim을 다시 실행했을 때 그 설정이 사라진다. vim의 기본 설정파일은 어디에 있을까? 커멘드라인에서 다음과 같이 실행해보자. # strace vi 2>a (:q!)를 사용해서 vi를 끝내고 a 파일을 보면 vi가 구동되면서 open 한 파일들을 찾을 수 있다. 잘 살펴 보면 /usr/share/vim/vimrc 파일을 열고 있음을 알 수 있다. 이 파일을 보면 어떻게 탭 크기를 바꿀 수 있는지 알게 될 것이다. 4.3 리눅스로 부팅한 후에 할 최소한의 작업 왜 윈도우나 NT의 파일 공유기능이 있는데도 굳이 리눅스를 사용하여야 하는가? 윈도우박스는 여러 클라이언트가 동시에 파일을 접근하는 멀티타스킹을 수행하기에는 역부족이다. NT는 같은 파일 서버로 쓰기 위해서는 더 비싼 하드웨어가 필요하다. 더구나 모니터와 키보드, 마우스까지 늘 붙여 놓아야 한다. 또한 기본적인 설정을 바꾸기 위해서는 NT에 직접 가야 한다. 리눅스는 부팅되지 않는 치명적인 에라가 아니라면 원격으로 조작할 수 있다. 치명적인 에라란 NT의 블루 스크린을 의미하지 않는다. NT의 블루 스크린은 재부팅으로 해결되는 경우가 대부분이며 이런 에라는 리눅스를 조작불능으로 만들지 않는다. 리눅스에서의 치명적 에라란 하드디스크가 물리적 에라가 났거나 합선으로 본체가 타는 경우를 말한다. 또다른 리눅스의 장점은 재부팅까지 원격에서 할 수 있다는 것이다. 즉 한 건물의 모든 리눅스 박스를 한 관리자가 한 곳에서 모두 제어할 수 있다. 물론 이런 장단점을 논하는 것이 이 글의 목적은 아니다. 적은 비용과 안정성을 원하는 기업이 있다면 리눅스에 관심을 가지는 것이 현명한 일이므로 선택은 여러분이 하는 것이다. 리눅스 박스를 만드는 일은 쉬운 일이다. 배포본을 구해서 기본 설정 그대로 인스톨하면 된다. 패키지를 모두 선택하면 1G 정도의 하드 디스크가 필요할 것이다. 사무실의 윈도우 박스가 많아서 5G 정도되는 하드 디스크를 사용하여 4G의 파일 서버를 만드는 것으로 가정한다. 배포본 인스톨 과정 중 fdisk 항목에서 파티션 하나를 /home에 할당하면 된다. /home에는 각 사용자의 홈디렉토리와 /home/samba 라는 파일 공유 디렉토리를 만들기로 한다. 리눅스는 아직도 하드웨어를 가린다. 그러므로 인스톨 과정에서 하드웨어를 인식하지 못하는 등 문제가 발생한다고 그 문제를 해결하기 위해 정보를 구하러 다니지 말 것. 필자는 친구가 말한 명언을 소개하고 싶다. "하드웨어에 맞추어 살지 말라. 하드웨어를 자신에게 맞추어라" 같은 기능을 가진 하드웨어들의 가격 차이는 당신의 시간비용보다 크지 않다. 문제가 있는 하드웨어가 있다면 빨리 다른 하드웨어를 사용하도록 하자. 그렇다고 해도 리눅스가 고가의 하드웨어를 요구하는 것은 아니다. 오히려 저가의 표준적인 하드웨어가 훨씬 안정적이다. 리눅스를 경험해 보기 위해서 인스톨하는 것이 아니라면 배포본을 인스톨하는 과정에서 하드웨어에 대한 고민을 하지 말기 바란다. 배포본을 인스톨하고 /dev/hda1을 "/"에 /dev/hda2를 swap으로 /dev/hda3를 /home에 붙였다면 이제 커멘드 라인으로 할 일은 모두 끝났다. 윈도우에 못지 않은 사용자 인터페이스를 경험해 보기로 하자. 4.4 linuxconf 의 사용 linuxconf는 공개로 나온 리눅스 설정툴이다. 레드헷을 인스톨했다면 이미 설정이 되어 있을 것이다. linuxconf는 text방식, 그래픽 방식, 웹방식을 지원한다. 그림 1에서 보듯이 윈도우 박스에서 linuxconf를 실행할 수 있다. linuxconf는 tcp/ip 포트 98을 사용하므로 http://server:98을 url창에 쓰면 된다.
그림 2와 같이 엑스윈도우에서 화려한 인터페이스를 사용할 수도 있지만 서버로 쓰기 위해서 엑스를 설정할 필요는 없다. 우리는 텍스트 모드와 웹 방식만을 사용할 것이다. 우선 리눅스박스가 네트웍에 접근할 수 있어야 하므로 기본적인 네트웍 설정을 linuxconf에서 하기로 한다. 4.5 ip의 설정 터미널에서 루트로 로그인한 후에 다음과 같이 실행하면 linuxconf 초기 화면을 볼 수있다. # linuxconf --text
여기서 Networking, Client tasks를 선택하면 리눅스 박스의 IP를 설정할 수 있다. Basic host information을 선택하자.
그림 5에서 host name을 써넣고 eth0인 Adapter 1을 Enable시키고 부팅하면서 설정한 대로 IP가 잡히도록 Config mode는 Manual을 선택한다. 완전한 호스트네임과 별명인 알리아스를 써넣는다. 이제 정확한 IP값을 적고 Netmask 값을 적는다. 배포본을 인스톨 했다면 Net device에는 eth0가, 커널 모듈은 해당 하드웨어에 맞는 것이 자동으로 적혀 있을 것이다. 네트웍 카드가 여러개 있다면 Adapter 2,3을 이에 맞게 설정하면 된다. Accept를 선택하고 빠져 나오면 된다.
그림 6에서는 /etc/resolv.conf를 설정하는 내용이다. 서버에서 인터넷을 접근할 수 있도록 하는 설정이다. DNS usage를 선택하고 linux.a.b.c라고 치지 않고 linux라고 치면 linux.a.b.c를 찾도록 만드는 default domain을 적는다. name server는 필요한 만큼 여러개를 적어도 된다. search domain은 linux 라고 적었을 때 linux.a.b.c가 없다면 그 다음으로 시도해 볼 도메인을 말한다. linux.a.b.c가 없다면 linux.kppinc.com, linux.softwareplaza.com을 차례로 시도할 것이다. 그림 7은 default gateway를 설정하는 모습이다. 윈도우에서와 별로 다르지 않으므로 설정에 어려움은 없을 것이다.
그림 8은 서버가 호스트를 찾는 방법에 대한 설정이다. 한 호스트가 접근해 오면 서버는 이 호스트의 이름을 알기 위해서 /etc/hosts 파일을 찾고 NIS(network information service)서버가 있으면 이를 이용하려고 시도한다. 대부분은 NIS서버가 없을 것이다. 그 다음으로 DNS 서버에 정보를 요청한다. 필자는 이 모든 방법을 사용하게 했지만 hosts,dns만을 사용하도록 해도 된다.
그림 9,10은 /etc/hosts 설정에 대한 것이다. /etc/hosts에 빈번하게 접근하는 호스트명을 적어 주면 좋다. 서버가 호스트를 찾을 때마다 DNS를 접근하는 것은 바람직하지 않다. 회사의 컴퓨터들이 인터넷에 연결되어 있다면 그 때마다 외부 네트웍을 접근해야하며 네임서버가 내부에 있다고 하더라도 내부 네트웍에 대한 접근은 로컬 하드 디스크보다 시간적으로 빠르지 않다. 또한 네임서버가 문제가 있으면 클라이언트들이 서버를 사용할 수 없는 경우도 있다. 물론 /etc/hosts에 클라이언트에 대한 정보를 기록하여 쓰는 방법도 문제는 있다. 클라이언트에 대한 정보가 바뀔 때마다 이를 변경해야 한다. 어떤 방법을 사용하더라도 서버에 빈번하게 접근하는 호스트에 대한 정보는 /etc/hosts에 적어 주는 것이 효율적이다.
linuxconf를 윈도우박스에서 웹방식으로 접근하기 위해서는 그림 11과 같이 Enable network access를 활성화 시키고 해당 호스트명을 적거나 특정 네트웍을 적어 주면 된다. 예를 들어 192.168.1.1을 적었다면 그 IP를 가진 컴퓨터에서만 접근할 수 있으며 192.168.1.0을 적어 주었다면 192.168.1.1 254까지의 컴퓨터들이 접근할 수 있다. 물론 linuxconf를 사용하기 위해서는 접근하는 컴퓨터가 여기서 적어 주는 네트웍안에 들어 있어야 할 뿐만 아니라 사용자 인증까지 거쳐야 한다. 이제 끝내면서 그림 12의 설정 변경 활성화를 선택하면 된다. 서버를 리부팅하고 윈도우 박스의 웹 검색 프로그램에서 http://server:98이라고 써 보자. linuxconf의 초기 화면을 볼 수 있을 것이다.
4.6 telnet의 사용 웬만한 일은 웹상으로 할 수 있다고 해도 리눅스에 로그인해서 할 작업은 없는 것은 아니다. 그렇다고 리눅스 박스에 붙어 있는 키보드와 모니터로만 이런 작업을 할 필요는 없다. 윈도우에서 telnet을 사용해서 작업을 하면 된다. 윈도우에는 기본으로 제공하는 telnet 프로그램이 있다. 윈도우 시작-실행창을 열고 telnet server.a.b.c라고 실행하면 리눅스에 로그인할 수 있다. 유닉스는 그 특성상 서버에 직접 붙은 터미널인 콘솔과, 텔렛으로 로그인한 단말기의 차이가 없다. 물론 시스템 경고 메세지등은 콘솔에만 나타나지만 /var/log/message를 검색해 보면 콘솔에 뿌려졌던 메세지가 모두 보관되어 있다. 그러므로 telnet 창을 하나 더 열고 "tail -f /var/log/message"라고 실행해 놓으면 콘솔과 완전히 동일한 환경을 만들 수 있다. 리눅스 커널 2.2에서는 콘솔 재지정 기능이 구현되어 이렇게 할 필요도 없지만 이런 내용은 이 글의 범위를 넘어가므로 다음 기회에 적기로 한다. 아래에 적은 webmin같은 프로그램을 윈도우에서 받아서 리눅스박스로 보내는 등의 일은 아직 복잡하므로 telnet으로 서버에 들어가서 ncftp등을 사용해서 받아 오도록 하자. telnet을 사용한다는 것은 유닉스 명령행 모드를 사용한다는 것을 뜻하므로 가능하면 거론하지 않겠다. 그러나 시스템 관리상 꼭 필요한 때가 있으므로 유닉스 기본 명령어 정도는 익히는 것이 좋다. 특히 에티터인 vi를 익히면 도움이 된다. 그러나 이 것도 불편하다면 도스 에디터와 유사한 pico를 사용해도 된다. 4.7 webmin의 사용 webmin은 웹상에서 유닉스의 설정을 바꿀 수 있게 만든 툴이다. 현재 0.6x버전이 나와 있는데 1.0이 되면 상용으로 바뀌게 된다. linuxconf에 부족한 툴들이 webmin에는 구현되어 있고 samba 설정을 하는 기능이 포함되어 있으므로 여기에 소개한다. webmin은 배포본에는 들어 있지 않으므로 홈페이지(http://www.webmin.com)를 방문해 받아오기 바란다. 설정의 주요 내용은 아래와 같다. 루트로 로그인해서 압축을 푼다. 설정 파일과 로그가 분산되면 이해하기 어려우므로 webmin 디렉토리 안에서 모든 것을 처리하도록하자. /root# tar xvzpf webmin-0.65.tar.gz /root# cd webmin-0.65 /root/webmin-0.65# mkdir config 다음에 설정 프로그램을 실행한다. /root/webmin-0.65# ./setup.sh *********************************************************************** * Welcome to the Webmin setup script, version 0.65 * *********************************************************************** Webmin is a web-based interface that allows Unix-like operating systems and common Unix services to be easily administered.
Installing Webmin in /root/webmin-0.65 ...
*********************************************************************** Webmin uses separate directories for configuration files and log files. Unless you want to run multiple versions of Webmin at the same time you can just accept the defaults.
Config file directory [/etc/webmin]: /root/webmin-0.65/config <- 입력 Log file directory [/var/webmin]: /root/webmin-0.65/config <- 입력 webmin을 실행하는데 필요한 설정 파일은 config 아래에 miniserv.conf에 적히게 된다. 로그도 여기에 쌓이게 한다. *********************************************************************** Webmin is written entirely in Perl. Please enter the full path to the Perl 5 interpreter on your system.
Full path to perl (default /usr/bin/perl): <- 엔터 webmin은 perl로 만들어졌기 때문에 시스템의 perl 프로그램의 위치를 지정해 주어야 한다. 리눅스에서는 /usr/bin/perl이 디폴트 값이다. Testing Perl ... Perl seems to be installed ok
*********************************************************************** For Webmin to work properly, it needs to know what operating system type and version you are running. Please choose your system from the supported list below.
------------------------------------------------------------------------------- NAME CODE VERSION ------------------------------------------------------------------------------- 1 Sun Solaris 2.5/2.5.1 solaris 2.5 2 Sun Solaris 2.6 solaris 2.6 3 Sun Solaris 7 solaris 7 4 RedHat Linux 4.0,4.1 or 4.2 redhat-linux 4.0 5 RedHat Linux 5.0,5.1 or 5.2 redhat-linux 5.0 6 Slackware Linux 3.2,3.3,3.4 or 3.5 slackware-linux 3.2 7 Debian Linux 1.3 debian-linux 1.3 8 Debian Linux 2.0 debian-linux 2.0 9 SuSE Linux 5.1,5.2 or 5.3 suse-linux 5.1 10 Delix DLD Linux 5.2 redhat-linux 4.0 11 Delix DLD Linux 5.3 redhat-linux 5.0 12 FreeBSD 2.2.6 freebsd 2.2 13 HP-UX 10,01, 10.10, 10.20 or 10.30 hpux 10.10 14 IBM AIX 4.3 (Limited support) aix 4.3 ------------------------------------------------------------------------------- Operating system: 5 <- 입력 webmin은 리눅스 뿐만 아니라 여러 유닉스 호환 운영체계를 지원한다. 솔라리스를 사용하는 관리자라면 한 번 시도해 볼만하다. 필자는 슈퍼레드헷을 사용하므로 5번을 선택 했다. Operating system name: redhat-linux Operating system version: 5.0
*********************************************************************** Webmin uses its own password protected web server to provide access to the administration programs. The setup script needs to know : - What port to run the web server on. There must not be another web server already using this port. - The login name required to access the web server. - The password required to access the web server. - The hostname of this system that the web server should use. - If the webserver should use SSL (if your system supports it).
Web server port (default 10000): <- 엔터 Login name (default admin): <- 엔터 Login password: <- 엔터 Web server hostname (default linux): 서버 이름 입력
...(정상적일 때 설정 과정이 나타남. 생략)
Creating uninstall script /root/webmin-0.65/config/uninstall.sh .. tcp/ip 포트 번호는 디폴트로 10000을 사용한다. http://host:10000 방식으로 웹민을 기동 시킬 것이다. 로그인명과 비밀번호는 임의로 설정할 수 있다. 이 로그인명은 시스템 관리자인 root와 동일한 자격을 가지고 있으므로 보안에 주의해야 한다. 셋업 프로그램이 이상 없이 끝나면 webmin서버가 기동되어 있다. 앞으로 리눅스를 재부팅 했을 때에도 여전히 webmin을 사용하기 위해서 부팅 스크립트 파일을 변경하자. vi나 pico 에디터로 /etc/rc/rc.local 파일을 불러와서 다음과 같은 내용을 첨가한다. /root/webmin-0.65/miniserv.pl /root/webmin-0.65/config/miniserv.conf 이제 리눅스의 모니터와 키보드를 제거해도 된다. 앞으로는 모든 설정을 웹이나 telnet으로 들어와서 하게 될 것이다. 4.8 webmin의 접근 제한 설정 배포본을 인스톨 했다면 samba가 기본으로 인스톨되어 있고 윈도우에서 접속도 가능하게 되었 있다. 이제 samba의 설정을 바꾸어 사무실의 윈도우박스에서 파일서버로 사용해 보도록 하자. webmin을 실행하기 위해서는 웹검색 프로그램인 netscape이나 msie를 실행하고 url창에 http://server.a.b.c:10000이라고 적어 넣는다.
webmin이 실행되면서 사용자 인증을 받는다. 여기에는 setup 할 때에 적어준 관리자명과 비밀번호를 적어야 한다. 그림 13은 잘못된 사용자명으로 로그인을 시도했을 때 나오는 메세지를 보인 것이다. 서버에 있는 사용자명으로는 로그인 할 수가 없다. 로그인을 했다면 그림 14의 webmin 초기화면을 볼 수 있다.
여기서 여러가지 일을 할 수 있지만 이번 호에서는 그 진행과정만을 보이기로 한다. 선택한 작업이 실제로 서버의 어떤 파일을 다루는지 알지 못하는 상태에서 이것 저것 건들다가는 리눅스를 새로 인스톨해야 하는 일이 생길 수도 있으므로 주의하기 바란다. 가장 먼저 허가 받지 않은 사용자가 서버의 webmin을 실행할 수 없도록 접근 제한을 설정해야 한다.
webmin 초기 화면에서 webmin configuration을 선택하고(그림 15) IP access control을 선택한다. 특정 IP를 가진 컴퓨터만을 허가/금지하거나 특정 네트웍 전체의 컴퓨터를 접근 허가/금지 할 수 있다. 바꾼 내용은 화면 아래 쪽의 update 버튼을 누르면 서버의 설정 파일을 실제로 바꾸게 된다. 이제 보안에 대한 사항은 해결되었다. 그러나 네트웍 천체에 대해서 접근을 허가 했다면 비밀번호등에 대한 보안에 신경을 써야 할 것이다. 4.9 webmin을 이용한 삼바 설정 webmin 초기 화면에서 File share for windows networking을 선택하자. 그림 17에서 보듯이 현재 리눅스에 붙어 있는 프린터와 tmp라는 파일 공유 설정이 되어 있다. 이렇게 만들기 위해서 필요한 사항을 설정해 보자.
삼바가 어떤 네트웍에 서비스를 할 것인가를 결정한다. interface 주소와 netmask 값으로 설정할 수 있다. 여러 네트웍에 서비스를 할 것이라면 그에 따라 여러개의 interface와 netmask를 정해주면 된다. 그림 18에서는 192.168.1.0 네트웍에 있는 모든 호스트에 대해서 서비스를 하게 되어 있다.
그림 19에서 우선 필요한 설정은 workgroup설정이다. 회사의 윈도우끼리 묶을 때 사용하는 workgroup 이름을 적어 준다. 그외 사항은 크게 중요하지 않다. 물론 구체적으로 들어가면 세세한 설정을 변경하여 최적화 시킬 수 있고 복잡한 상황에 맞추어 줄 수 있지만 이번 달에는 자세하게 언급하지 않겠다. 디폴트값 만으로도 어려움 없이 사용할 수 있다. security는 share level이나 user level 중 아무 것이나 사용해도 상관없다. remote announce는 broadcast 주소를 적어 주도록 한다. 그림 20의 비밀번호 관련 내용은 유닉스 사용자와 윈도우 사용자의 매핑등에 대한 복잡한 내용이다. 디폴트 값을 그대로 사용해도 문제가 없다. 그림 21의 기타사항도 필요할 때 설명을 하기로 한다.
samba는 /etc/printcap을 읽어서 프린트 서비스를 결정한다. 서버를 프린트 서버로도 사용하기를 원한다면 webmin의 프린터 항목을 수정하면 된다. samba는 디폴트로 프린터 서비스를 열어 주므로 설정 그대로 두도록 하자. 프린트 서버 설정은 다음 기회에 설명하기로 한다.
그림 17에서 create a new print share를 선택하면 그림 23이 나온다. spool 디렉토리를 적어 주고 available을 yes로 만들면 이제 윈도우에서 프린트를 할 수 있다. 그림 24는 /home/samba 디렉토리를 tmp라는 이름의 파일 공유 서버로 사용하게 만드는 화면이다. 그림 17의 create a new file share를 선택하면 나오는 화면이다. available과 browseable을 yes로 선택하면 된다.
여기까지 오면서 각 화면에서 모두 save 버튼을 눌렀다면 이제 samba 서버를 다시 시작하는 일만 남았다. 만약 save 버튼을 빠뜨린 것이 있다면 제대로 작동을 하지 않을 것이다. 설정 내용은 그대로 남기 때문에 각 메뉴를 방문해 save를 다시 눌러 주면 된다. 참고로 여기까지 한 일은 /etc/smb.conf 파일에 저장되어 있다. 4.10 webmin을 이용한 프로세스의 관리 유닉스는 데몬이라는 프로세스가 백그라운드로 돌면서 사용자의 요청에 반응한다. 마치 도스의 램상주 프로그램과 같은 일을 한다. samba는 데몬 모드로 돌고 있기 때문에 설정이 변경되었다면 다시 실행해야 한다. webmin초기 화면에서 running process를 선택하자. 많은 프로세스가 보일 것이다. 이 중에서 smbd와 nmbd라는 프로세스를 찾아 kill signal을 보내 죽인다. 그림 25에서 두 개의 smbd 프로세스는 9088과 10252 번호를 가지고 있고 nmbd는 9091 프로세스 번호를 가지고 있다.
9088을 선택해서 들어가면 그림 26을 볼 수 있고 kill을 선택해서 send signal을 보낸다. subprocess인 10252도 선택해서 죽인다. nmbd도 마찬가지이다.
이렇게 한 후에 그림 17의 samba초기 설정 화면에 들어가면 그림 27과 같은 start samba servers 라는 버튼이 새로 생긴 것을 볼 수 있다. 이 버튼을 선택하면 새 설정으로 samba가 실행된다. 이제 그림 28과 같이 윈도우에서 리눅스가 보인다. 공유 디렉토리인 tmp를 통해서 모든 윈도우박스들은 안정적인 파일 서버를 무료로 얻게 되었다.
4.11 리눅스 블랙박스화를 위하여 리눅스는 서버이다. 리눅스가 가까운 시기에 윈도우를 밀어내는 등의 기적은 일어나지 않을 것이다. 리눅스가 지향하는 것은 서버 시장의 지배와 데스크탑 사용자의 10%를 획득하는 것이다. 영어가 모국어인 사람들은 엑스 윈도우에 대해서 큰 저항을 하지 않겠지만 한국에서는 전혀 그렇지 못하다. 그렇다고 한글화에 전념할 수는 없다. 리눅서가 집중해야 할 부분은 서버로서의 가능성이다. 내부는 사용자들이 알 필요 없도록 만드는 노력, 유닉스 명령행 방식까지 필요 없게 만드는 작업, 그래서 필요한 기능을 언제나 잘 수행하는 리눅스 블랙박스의 개발이 필요하다. 미래의 컴퓨터 환경이 마이크로소프트가 의도한 대로 끌려 가지는 않겠지만 윈도우의 편리함에서 아무 것도 배울 것이 없다고 생각해서도 안된다. 목적 중심의 리눅스 박스, 안정성, 웹방식의 제어의 편리함, 이 것이 한국적 상황에서 리눅스 개발이 나아가야할 방향이다. 4.12 이달의 숙제 webmin의 편리함에도 불구하고 보안상의 문제점이 많다. 만약 누군가가 webmin의 관리자 비밀번호를 알아냈다면 그 서버는 완전히 망가질 것이다. 웹상으로 실행 중인 프로세스를 죽일 수도 있고 http 서버의 설정을 망가뜨릴 수도 있기 때문이다. webmin을 리눅스 박스가 많이 채택한다고 하면 누군가가 포트 10000을 열어보고 비밀번호를 알아내려고 시도할 수도 있다. webmin이 tcp 포트 10000이 아닌 다른 포트를 사용하게 하려면 어떻게 하면 될까? 물론 리눅스로 로그인하지 않고 이 것을 바꾸어 보도록 하자. 5. 기업 환경을 위한 리눅스 블랙박스 만들기[5] 5.1 삼바 서버 만들기, 이보다 쉬울 순 없다. 이 달에는 지난호에서 간단히 사용법을 익힌 webmin을 이용해서 삼바 서버를 제대로 설정해 보기로 한다. 여태까지 잡지나 인터넷 문서에서 삼바 설정에 대해서 쓴 글은 많았지만 리눅서들도 이해하기 힘든 텍스트 설정파일 편집방법을 설명한 것이 대부분이었다. 설정 파일을 모두 파악한 사람은 설명을 하면서 신나겠지만 읽는 사람은 전혀 이해할 수 없다. 텍스트 설정 파일을 편집하는 것이 효율성이 있는 것은 사실이다. 열번 이하의 마우스 클릭으로 한 개의 설정을 바꿀 수 있을 때, 바꾸어야 하는 설정이 열 개 이하라면 마우스로 하는 것이 제일 편하다. 그러나 반복 작업이 10회 이상 넘어가면 마우스 클릭이 편하다고 할 수는 없다. 일이란 반복 할 수록 숙달되어야 하고 숙달 될 수록 작업 시간이 줄어들어야 하며 다시 단위 작업을 블랙박스화 시킬 수 있어야 한다. 그러나 마우스 클릭 방식은 이런 장점을 줄 수 없다. 물론 텍스트 설정 문서를 편집하는 것이 효율성만 있는 것은 아니며 분명한 단점들이 있다. 우선 이 방법은 설정간의 의존성을 잘 파악할 수 없다. 설정 문서 속에 줄마다 설명이 붙어 있고 메뉴얼 페이지가 존재하면 FAQ까지 잘 준비되어 있어도 초보자들에게는 전혀 알 수 없는 비밀문서에 불과하다. 또한 설정 변경은 왠만큼 시스템에 대해서 자신이 없으면 함부로 만질 수 없다. 설정 파일의 옵션이 의미하는 것을 제대로 파악하지 않은 상태에서는 한 개라도 함부로 고쳤다가 전체 시스템을 망칠 수도 있다. 더구나 계속 서비스 중인 시스템을 잘못 건드려 문제가 발생했지만 고치기 전 파일을 백업해 놓지 않아 원위치도 할 수 없을 때는 어떻한단 말인가? 리눅스의 설정 파일에 대한 자세한 설명이 아무리 많아도 그 것은 또하나의 비밀문서이며 윈도우 사용자들에게 전혀 도움이 되지 않는다. 그러므로 이런 설명은 일단 뒤로 미루고 마우스 클릭과, 쓸 수 있는 부분만 열려 있는 폼 형태의 웹문서를 이용해서만 리눅스를 제어하도록 하자. 언젠가 웹문서가 의미하는 것을 이해하고 텍스트로 된 설정 문서를 읽어도 이해가 될 때 본격적으로 vi를 기동해도 늦지 않다. 초보딱지를 뗀 리눅서들이 잊어 먹는 것이 바로 초보 때 어려워 했던 기억이다. 일단 리눅스를 파악하고 나면 윈도우 사용자를 무시하기만 할 뿐 이들을 이해하려 하지 않는다. 그러나 리눅스가 전파되기를 원한다면 리눅서가 내려가야 한다. 내려가는 것은 쉬워도 올라오기는 어렵다. 마호멧이 말하기를 "산이 내게 올 필요는 없다. 내가 다가가면 그만 아닌가?". (글쓴이 주: 이 마지막 패러그래프 쓰려고 삼십분을 소모했음. 다시 읽다 보니까 짤릴 위험이 많은 부분임. 그러나 가능하면 살려 주기 바람. 그래야 글이 폼 나니깐 ) 5.2 숙제 풀이 webmin의 편리함에도 불구하고 보안상의 문제점이 많다. 만약 누군가가 webmin의 관리자 비밀번호를 알아냈다면 그 서버는 완전히 망가질 것이다. webmin은 상당히 쓸만한 관리툴이므로 앞으로 많이 전파될 것이다. TCP/IP는 포트를 사용하기 때문에 리눅스 박스에 webmin이 많이 쓰이면 아무 IP로나 포트 10000을 열어보고 비밀번호를 알아내려는 시도를 하게 될 수 있다. 일단 비밀번호를 알아 내면 그 시스템은 크래거의 손안에 들어가는 것이다. 편리함은 위험을 동반한다. 그러므로 webmin이 tcp 포트 10000이 아닌 다른 포트를 사용하게 하게 만들자.
화면 1은 webmin을 기동하고 "Webmin Configuration", "Port and Address"를 선택한 것이다. 화면에서 "Listen on Port"에 원하는 값을 적어 주고 아래의 "Update" 버튼을 클릭하면 된다. 이제부터 외부인이 이 리눅스 박스의 webmin에 접근할 수 있는 확률이 현저히 줄어 들었다. 참고로 포트를 변경하면 사용자 인증을 다시 거쳐야 한다. 5.3 패키지 버전 따라잡기 삼바 2.0.x(현재 2.0.2)가 나왔다. 여러분이 사용하고 있는 리눅스 배포본에는 아직 1.9.x 버전에 머물러 있다. 2.0 버전에는 전용 그래픽 설정툴인 swat도 있지만 인스톨만 하면 쓸 수 있는 상태로 나온 배포본이 아직 없으며 윈도우 사용자가 삼바를 가져와서 컴파일 하는 것도 어려운 일이다. 물론 실행파일을 묶어 배포하고 있는 것도 있다. 이 것도 현재 사용하고 있는 배포본(요즘은 거의 redhat을 주로 쓰고 있음)과 맞아야 하고 그 상황에서 이전의 파일을 지우거나 백업하는등의 조치를 정상적으로 끝마쳐서 문제가 없어야 한다. 왠만한 리눅서들도 스스로 패키지 업그레이드를 따라가기 힘들다. 패키지간 의존성 뿐만 아니라 인스톨 과정에서 프로그램이 /usr/bin과 /usr/sbin 그리고 /usr/local/bin에 중복되거나 설정파일이 섞이면 아주 골치 아파진다. 필자가 한달 전에 글을 쓸 때와 지금의 패키지 변경 상황은 다음과 같다. samba-2.0.2, apache-1.3.4, php3-3.0.6, kernel-2.2.1, sendmail-8.9.2에서 다시 8.9.3, mysql-3.22.16a, glibc-2.1, KDE-1.1, mod_ssl-2.2.2, XFree86-3.3.3.1 주로 큰 패키지만 나열한 것이며 kernel-2.0을 사용하기 위해서 필요한 업그레이드 패키지는 적지도 않았다. 각각의 패키지는 성능의 향상이나 버그 패치 또는 보안 문제로 업그레이드 할 필요가 있는 것들이다. 리눅스는 집중된 개발 관리 단체가 없기 때문에 각 패키지는 수시로 독자적으로 버전업이 된다. 이 모든 것을 따라 가다가는 ftp와 컴파일하다가 세월을 다 보내게 된다. 이 문제를 어떻게 해결해야 하는가? 정답은 다음과 같다. 현재 쓰고 있는 프로그램에 문제가 없다면 신경쓰지 말 것. 심각한 보안문제가 있다면 어쩔 수 없이 업그레이드에 관심을 가져야 하지만 그렇치 않다면 버전에 연연해 하지 말기 바란다. 배포본이 바뀌면 자연스럽게 각 패키지가 최신으로 업그레이드되고 서로의 의존성도 해결되니까 다음 배포본을 기다리자. 그렇다고 배포본이 나올 때마다 업그레이드 할 필요는 없다. 현재 쓰는 기능이 문제가 없다면 이 마저도 무시하기 바란다. 5.4 삼바 주식회사 회사에 15대의 컴퓨터가 있다. 거의 win95이며 일부는 win98을 사용하고 있고 NE2000 호환 랜카드를 장착하고 있는 컴퓨터가 8대, 8포트 허브가 한 개 있으며, 몇 대의 컴퓨터에 있는 모뎀으로 필요할 때 인터넷에 접속한다. 랜으로 연결한 컴퓨터끼리는 윈도우의 공유 기능을 이용해서 파일을 주고 받고 있다. 프린터는 2대가 있는데 하나는 레이저 프린터이며 경리를 보는 a직원의 컴퓨터에 연결되어 있고 다른 하나는 잉크젯 칼라 프린터인데 이것은 b대리의 PC에 연결되어 있다. c직원이 30페이지 짜리 문서를 프린트하려면 시간이 많이 걸리는 것뿐만 아니라, 회사의 거의 모든 문서를 처리하는 경리직원 a가 전혀 컴퓨터를 쓸 수 없어서 원성이 자자하다. 물론 b대리의 잉크젯에 프린터 할 때도 마찬가지이다. 랜으로 연결되지 않은 직원들은 작성한 문서를 디스켓에 복사해서 a직원의 PC에 가져와 프린트를 해야 한다. 삼바 주식회사에서는 전체 PC를 네트웍으로 연결하기 위해서 허브를 하나더 사고 나머지 컴퓨터를 위해서 랜카드를 구입했다. 파일을 공유하기 위해서 아무도 사용하지 않는 윈도우 PC 한 대를 정해서 파일을 주고 받았다. 여기에 프린터를 2대 모두 연결하여 경리 직원 a의 불평이 없도록 했다. 그러나 프린터를 하는 동안에 윈도우 박스는 거의 파일을 보내 주지 못했고 하루에 몇 번씩 죽는 바람에 데이타를 잃어 버리기도 했으며 결정적으로 회사 기밀로 유지해야할 파일을 전 직원들이 아무 문제 없이 볼 수 있었다. 더구나 인터넷을 사용하게 하기 위해서 56K 전용선을 하나 끌어왔는데 윈도우 박스에는 붙일 수가 없어서 NT가 필요했다. NT는 윈도우와 거의 비슷하므로 부담이 없을 것 같았다. 회사에서 가장 빠른 컴퓨터에 인스톨하고 파일서버와 프린터 서버로 사용하면서 전용선도 연결하여 메일도 주고 받게 할 생각이었다. 가능하면 회사 홈페이지도 만들고... 드디어 회사가 최첨단 인터넷 시대에 부응하는 모습을 갖추는 것이다. 5.5 리눅스가 설 자리 국내 중소기업의 대부분이 이런 모습일 것이다. 아니 이 정도만 되어도 아주 양호한 회사라고 할 수 있다. 거의 다 통신회사의 ID를 사용하여 필요할 때 전화 걸어서 메일을 주고 받으며 내부 PC끼리 네트웍으로 연결되지도 않았고 프린터는 직원 A에게만 연결되어 있으며 나머지 사람들은 프린트를 아예 하지도 않으며 파일은 디스켓으로 주고 받고 있을 것이다. 나는 지금 전사적으로 네트웍이 구성되어 있고 홈페이지 제작에 수천만원씩 들이는 기업체를 말하고 있는 것이 아니다. 인터넷이 중요하다는 말을 듣고 막연히 우리 회사에도 이것을 도입하면 좋겠다고 생각하는 중소 기업체들, 네트웍 설치에 대해 문의해보니 수천만원씩 불러서 엄두도 못내는 업체들, 이 글을 읽을 확률이 거의 제로에 가까운 바로 그 사람들에 대해서 이야기하고 싶은 것이다. 어쨋든 PC는 충분할 만큼 보급되어 있다. 이들은 한개 이만원 정도 밖에 하지 않는 랜카드와 네트웍선 그리고 가장 저렴한 허브로 내부 네트웍을 구성할 수 있다. 5-60만원이면 충분하다. 조금 형편이 된다면 56K 전용선을 회사에 도입하는 것도 큰 부담이 아니다. 이 것으로 충분하다. 천만원에 육박하는 NT 서버를 구입하지 않아도 되며 회사에서 놀고 있는 586 컴퓨터 한대와 조금 큰 하드 디스크만 있으면 완벽한 내부 네트웍과 각 직원이 마음대로 인터넷에 접근할 수 있는 환경을 구축할 수 있고, 회사의 홈페이지를 가질 수 있으며 모든 직원들이 이메일 주소를 사용할 수 있다. 바로 이 것이 최근 Linuxcare에서 주최한 "리눅스 이야기"의 대상을 차지한 "비밀에 쌓인 허버트"라는 글의 내용이다. 심상현씨의 홈페이지(http://eeserver.korea.ac.kr/ artsilly)를 방문해 보기 바란다. 네트웍 구성에 큰 돈을 들일 수 없는 회사에서, 네트웍에 대해서 전혀 알지 못하는 직원들을 위해서 한 명의 리눅서가 해 줄 수 있는 것의 최대치가 무엇인지 감동적으로 느낄 수 있을 것이다. 필자가 몇 달에 걸쳐서 진행해오고 있는 "리눅스 블랙박스 만들기"라는 주제는 바로 허버트 만들기에 다름 아닌 것이다. 한국의 중소기업에 몸담고 있는 사람들이 이 글을 읽고 리눅스를 구하고 싶은 마음이 생기기를 바란다. 필자가 이렇게 떠들고 있는 이유가 바로 여러분에게 또하나의 허버트를 선물하고 싶기 때문이다. 5.6 윈도우 설정 삼바로 파일 서버를 만들어 보자. 구체적인 형태는 모든 사람들을 위한 공용 디렉토리와 몇 사람의 관계자들만을 위한 그룹 디렉토리, 그리고 각각의 사용자를 위한 개인 디렉토리를 만들어 주는 것이다. 제일 먼저 윈도우의 TCP/IP 설정을 해야 한다. 윈도우끼리만 내부적으로 사용할 때는 다른 프로토콜(NETBEUI)을 사용하지만 리눅스와 연결하거나 인터넷을 접속하기 위해서는 TCP/IP가 활성화 되어 있어야 한다. 전용선이 들어와 있고 IP를 128혹은 256개를 받았다면 컴퓨터마다 인터넷에서도 통용될 수 있는 IP를 사용하면 되겠지만 IP를 한 개 밖에 못받았거나 아직 인터넷에 연결하지 못했다면 내부적으로 쓸 수 있는 192.168.1.x를 사용하면 된다. 일단 192.168.1.x를 쓰는 것으로 하겠다. 이 번호는 인터넷에 연결되었을 때는 사용할 수 없다는 것은 알고 있기 바란다. 각 윈도우 PC에서 네트웍-등록정보를 열어서 서로 겹치지 않는 IP를 할당한다. 이 과정은 길게 설명하지 않겠다. 윈도우 설명서를 보거나 회사에 널려 있는 윈도우 관련 안내서를 뒤져보기 바란다. 주의할 것은 윈도우가 처음 시작될 때 적는 사용자명을 한글로 하지 말고 영어로 하라는 것이다. 그래야 리눅스를 사용할 때 문제가 생기지 않는다. 5.7 리눅스 사용자 등록 윈도우 TCP/IP를 설치했다면 도메인명을 만들었을 것이다. 예를 들어 192.168.1.x를 사용한다면 a.b.c 도메인 안에 win1.a.b.c, win2.a.b.c 와 같이 호스트명을 주었을 것이다. 같은 도메인 명 안에 리눅스 박스도 들어가게 만들자. 즉 리눅스 박스의 IP는 192.168.1.250을 주고 호스트명은 linux.a.b.c을 사용하게 하는 것이다. 다 끝났으면 각 윈도우 PC의 사용자명(부팅후에 로그인할 때 넣는 사용자명)과 같은 리눅스 사용자를 만들자. Netscpae(혹은 MSIE)를 기동하여 http://linux.a.b.c:10000 이라고 친다(앞에서 포트 번호를 바꾸었다면 10000 대신에 그 값을 사용할 것.) webmin이 기동되면 "Users, Groups and Passwords"를 선택한다.(화면 2)
여기서 이미 만들어진 사용자와 그룹은 시스템에 필요한 것들이다. 윈도우 사용자들을 위해서 화면 아랫쪽의 "Create a new Group"을 선택하면 화면 3이 나온다.
화면에서 "Group name"에는 "company"를 "Password"는 "None"을 선택한다. "Group ID"는 webmin이 자동으로 빈 번호를 선택하며 "Members"는 필요가 없으므로 그대로 두면 된다. 다 되었다면 아랫쪽의 "Create" 버튼을 눌러서 이 그룹이 실제로 만들어지게하다. 같은 식으로 "agroup", "bgroup"를 만든다. 이 것은 나중에 삼바에서 사용할 그룹들이다. 다음 화면 2에서 중간 부분에 있는 "Create a new user"를 선택한다(화면 4).
여기에서 "Username"을 "auser"로, "Real name"필드에 "직원 A"를, "Primary group"에는 "company"를 넣고, "Home directory"는 "/home/auser"를, "Password"는 "Clear text password"를 체크하고 그 아래 비밀번호를 적는다. 나머지 "User ID", "Shell", "Secondary groups"는 그대로 두고 "Create home directory"와 "Copy files to home directory"는 모두 "Yes"에 체크하고 아래 있는 "Create" 버튼을 클릭한다. 잠시 후에 이상이 없으면 사용자가 만들어 진다. 이런 식으로 모든 사용자를 만든다. 물론 실제로 사요하려면 각 직원이 선택한 사용자명을 만들어야 할 것이다. buser:직원B:company:/home/buser cuser:직원C:company:/home/cuser duser:직원D:company:/home/duser euser:직원E:company:/home/euser fuser:직원F:company:/home/fuser guser:직원G:bgroup:/home/guser huser:직원H:bgroup:/home/huser iuser:직원I:agroup:/home/iuser juser:직원J:agroup:/home/juser kuser:직원K:agroup:/home/kuser a fuser는 company 그룹으로 공유 디렉토리를 사용하게 되며, guser, huser는 bgroup으로 묶여 보안이 필요한 디렉토리를 공유하고 i kuser는 agroup의 데이타를 공유한다. 삼바에서 손님 사용자로 받아 들이는 경우는 사용자 만들기가 필요 없지만 윈도우에서 리눅스가 잘 보이지 않는등의 문제가 생길 수 있으므로 일단은 다 만들어 두는 것이 좋다. 호스트 등록 ----------- 지난 달에 설명한 내용을 리눅스에 적용했다면 "http://linux.a.b.c:98"을 Netscape에 쓰면 linuxconf 초기 화면을 볼 수 있을 것이다. 만약 문제가 있다면 지난호를 참고해서 linuxconf를 설정하기 바란다. linuxconf의 초기화면에서 "Networking", "Information about other hosts"를 선택하고 "ADD" 버튼을 누르면 화면 5가 나온다.
"Primary name + doman"에는 "auser.a.b.c"를, "Aliases"에는 "auser", "IP number"에는 "192.168.1.1"를 넣고 "Accept"버튼을 눌러서 추가한다. 같은 방법으로 "kuser.a.b.c-kuser-192.168.1.11"까지 넣고 완성한 모습이 화면 6에 있다.
5.8 삼바 기본 설정 삼바를 사용하기 위해서는 기본설정과 각각의 서비스에 대한 설정을 해야 한다. 기본 설정은 전체 서비스를 위한 설정이며 한 번만 제대로 해 놓으면 그 다음에는 거의 변경할 필요가 없다. webmin을 이용하면 잘못 설정하게 되는 일이 거의 일어나지 않으며 많은 옵션은 디폴트 값을 그냥 사용해도 된다. 기본 설정에서 해야 할 일은 서비스할 TCP/IP 주소 영역과 사용자 인증, 그리고 삼바가 동작하면서 필요한 항목에 관한 것이다. 삼바가 컴파일 되면서 기본설정에 스스로 디폴트 값을 채워넣기 때문에 특별한 경우를 제외하고는 기본설정 역시 고칠 필요가 없다. smb.conf 메뉴얼 페이지를 보면 백여개 이상의 옵션이 있는데 이 것들을 조정하면 특별한 목적에 사용가능하지만 우리가 목표로 하는 것은 간단한 파일서버를 만드는 것이므로 꼭 들여다 볼 필요는 없다. 앞에서 말했듯이 smb.conf에서 설명한 옵션들은 모두 컴파일 시점에 디폴트 값이 들어 있으므로 걱정할 것이 없다. 여러분의 사이트를 위해서 바꾸어야 하는 것은 몇개 되지 않으며 이 글에서 설명한 것만 제대로 조정하면 문제 없이 사용할 수가 있다. 우선 webmin 초기화면에서 "File Shares for Windows Networking"으로 들어가 "Unix Networking"을 선택한다(화면 7).
모든 옵션은 기본값을 사용해도 상관없다. 고칠 필요가 있는 것은 "Network interaces"에서 "Use list"를 체크하고 그 아래 그림과 같이 적으면 된다. interface에는 리눅스 박스의 IP를 적고 Netmask에는 "255.255.255.0"을 적으면 된다. 이 의미는 삼바가 192.168.1.0 192.168.1.255 값 사이에 있는 호스트에게만 자신을 보여 주도록 하는 것이다. 만약 회사의 네트웍이 192.168.1.x와 192.168.2.x로 되어 있다면 netmask 값에 "255.255.0.0"을 사용하거나 각각의 "192.168.1.1/255.255.255.0", "192.168.2.1/255.255.255.0"을 적어 주면 된다. 이렇게 해야 외부 컴퓨터가 내부 네트웍을 들여다 볼 수 없다. "127.0.0.1" 부분은 안 적어도 상관없다. 그리고 "Socket options"에서 "TCP_NODELAY"를 체크하도록 한다. 삼바 서버 사용자들이 이 옵션을 체크하면 속도의 증가가 있다고 보고하고 있다. 다되었으면 저장한다. 화면에는 나오지 않았지만 웹브라우저로 보면 아랫 쪽에 "save"버튼이 있을 것이다. 삼바 설정 화면에서 "Windows Networking"을 선택하면 화면 8이 나온다. 화면 8에서도 거의 대부분은 그대로 두어도 좋다.
Workgroup은 회사에서 쓰는 값을 적는다. "Server description"에는 마음에 드는 이름을 적는다. "Server name"에 쓰는 값은 netbios를 사용할 때 보이는 이름이다. hostname과 같은 값을 적으면 혼란이 없다. Security에는 "Share level"과 "User level"중 아무거나 상관이 없지만 "Share level"이 디폴드값이다. "Share level"은 리눅스 박스에 윈도우쪽 사용자의 계정이 없어도 그 윈도우에 서비스를 허용할 수 있다. "Remote Announce to"는 "From list"를 체크하고 "IP Address" 항목에 Network 값을 적는다. Network 값은 윈도우에서 사용하는 broadcast 값과 같다. 나머지는 화면과 같이 그대로 두어도 상관없다. 참고로 설명하자면 "WINS mode", "Master browser priority"는 회사에 NT가 있을 때 필요한 값이다. 삼바 설정 화면의 "Authentication"을 선택한 것이 화면 9에 나와 있다.
"Use encrypted passwords"는 주의할 필요가 있다. win98/NT등에서 비밀번호를 암호화 시켜서 전송할 경우에는 이 옵션을 Yes로 해야 하며 win95 등에서 암호화되지 않은 비밀번호를 사용할 때에는 NO로 해야 한다. 회사의 컴퓨터가 모두 win98이거나 win95 osr2 이상일 경우에는 Yes로 사용하면 된다. 이렇게 설정했는데 일부 컴퓨터만 로그인을 못하고 비밀번호가 잘못되어다고 나온다면 옵션은 NO로 주고 나서(물론 삼바를 죽였다가 다시 살려야 한다) 그 컴퓨터가 로그인이 되는지 확인해 보기 바란다. 로그인이 안되던 컴퓨터가 로그인이 된다면 아마 이전에 로그인이 되던 컴퓨터는 로그인이 안될 것이다. 즉 서로 다른 방법 중에서 한 방법만을 사용할 수 있다. 작은 회사의 윈도우 비밀번호는 보안성이 전혀 없으므로 "Use encrypted passwords"를 NO로 두고 win98 컴퓨터의 레지스트리를 다음과 같이 조작하면 회사의 win95와 공존시킬 수 있다. Win95_PlainPassword.reg의 내용
REGEDIT4
[HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\VxD\VNETSUP] "EnablePlainTextPassword"=dword:00000001
이 방법을 사용하고 싶지 않다면 win95를 모두 업그레이드 하면 된다. 어느 쪽이 편한지는 여러분이 판단하기 바란다. "Allow null passwords"를 Yes로 하면 윈도우 부팅하면서 엔터키만 치고 들어오는 사용자도 리눅스 박스를 쓸 수 있지만 보안이 문제가 될 수 있으므로 No로 설정하는 것이 좋다. 나머지는 전혀 손 댈 필요가 없다. Save 버튼을 누르고 나오는 것을 잊지 말 것. 삼바 설정의 "Miscellaneous Options"를 선택한 화면 10을 보자.
특별한 것은 없으며 화면에 보이는 그대로 설정하면 된다. "chroot() directory"는 절대로 고치지 말고 None에 체크해 둘 것. 삼바의 설정화면에서 선택할 수 있는 나머지 "Windows to Unix Priniting", "Printer Share Defaults", "File Share Default"는 화면 11, 12, 13에 있는 대로 설정하면 된다.
5.9 삼바 home 설정 각 사용자는 자기만의 디렉토리를 가진다. 이 디렉토리는 윈도우 로그인할 때 사용하는 사용자 명과 같은 디렉토리가 서버의 /home 아래에 생성되어 있는 것이다. 윈도우에서 삼바 서버에 접속하면(윈도우의 네트웍 환경 아이콘을 눌렀을 때 삼바 서버가 보이는 경우 그 아이콘을 다시 누르는 행위) 윈도우 로그인 할 때의 사용자명과 비밀번호가 서버에 전송되어 자동으로 체크되며 서버의 비밀번호와 일치하면 이 디렉토리를 보여 준다. 배포본에 따라 home 설정이 기본으로 되어 있을 수도 있다. 이 때에는 삼바 설정의 윗쪽에 "Share Name"에 "homes"가 보인다. "homes"를 클릭하면 화면 14가 나온다. 그렇지 않으면 "Create a new file share"를 선택하면 화면 14의 윗부분만이 보일 것이다. 그림 14와 같이 적은 다음 "Create"를 클릭하고 나와서 "Share Name"에 생긴 "homes"를 다시 클릭하면 화면 14가 나온다. 이 것은 각 사용자의 홈디렉토리에 대한 접근 권한을 설정하는 것이다.
화면에서와같이 "Share name"을 "Home Directories Share"에 체크하고 Available는 Yes로 Browseable는 No로 한다. 그 아래 "Security and Access Control"(화면 15)에서는 Writable을 Yes로 "Guest Access"를 None으로 "Hosts to allow"는 "Only allow"를 체크한 후에 "192.168.1."(마지막 마침표는 반드시 찍어야 함)을 적는다. "File Permissions"(화면 16)에서는 디폴트 값 그대로 사용하고 "Miscellaneous Options"(화면 17)또한 디폴트 값을 사용하면 된다.
"File naming"(화면 18)에서는 주의할 것이 있다. 비록 삼바가 8비트 처리를 해 준다고 해도 한글 문제가 있을 수 있으므로 "Mangle Case"를 No로 설정하고 "Preserve Case"는 Yes, "Short Preserve Case"도 Yes로 설정해야 한다. 그외는 디폴트 값을 그대로 사용해도 상관없다. home 디렉토리 뿐만 아니라 나중에 설정할 agroup, bgroup, tmp 디렉토리까지 모두 이렇게 해야 한다.
모두 설정하고 저장하고 나오면 이제 각 사용자는 자신만의 디렉토리를 가지게 된다. 5.10 삼바 tmp 설정 누구나 사용할 수 있는 공유 디렉토리를 만들어 보자. 삼바 설정 화면에서 "Create a new file share"를 선택하면 화면 19의 윗부분과 같이 나오며 여기에 화면과 같이 설정한다.
"Share name"은 "tmp"로 "Directory to share"는 "/home/samba", Available은 Yes, Browseable은 "Yes"로 만들고 "Create"버튼을 누른다. 삼바 설정의 "Share Name"에 "tmp"가 나타났을 것이다. 이 것을 클릭하면 화면 19가 나오며 아랫쪽의 "Security and Access Control"을 선택하며 home 설정 때의 화면(화면 15)가 나온다. 바꾸어야 할 설정은 "Guest Access"를 Yes로, "Guest Unix user"는 "nobody"로 바꾼다. "File permission" 설정 화면(화면 16)에서는 "Force Unix user"를 "nobody"로 "Force Unix Group"을 "nobody"로 만든다. 이렇게 하면 이 디렉토리에 쓰는 모든 파일은 소유주와 그룹이 nobody로 설정되므로 누구나 파일을 올리거나 받고 또 지울 수도 있게 된다. 즉 공용 디렉토리가 되는 것이다. 그외 "File Naming"(화면 18), "Miscellaneous Options"(화면 17)은 home 때와 같이 만들면 된다. 저장하고 나오면 회사의 모든 직원을 위한 파일 공유 서버가 만들어 졌다. 참고로 이런 공유 디렉토리에는 누구나 파일을 올릴 수 있어서 제대로 지우지 않으면 금방 하드디스크가 꽉차게 된다. 그러므로 주기적으로 이 디렉토리를 살펴서 하드 정리를 해 주기 바란다. 5.11 삼바 agroup 설정 마지막으로 삼바에서 몇 명의 사용자만을 위한 폐쇄된 디렉토리를 만들어 보기로 하자. agroup에는 직원 i,j,k가 사용하는 iuser,juser,kuser컴퓨터가 있다. Webmin 초기 화면에서 "File Manager"를 선택하여 /home/(필자는 /job/home/이다)디렉토리를 보게 한 다음 화면 20의 윗 쪽에서 디렉토리 아이콘의 New를 선택하고 /home/agroup을 써 넣는다.
이제 이 디렉토리를 선택한 다음 위쪽의 Info 아이콘을 클릭하면 디렉토리에 대한 자세한 정보가 나온다(화면 20). 여기서 Permissions에 대해서 User는 "Read, Write, List"를 체크해 주고 그룹에 대해서도 "Read, Write, List"를 체크해 준다음 Others에 대해서는 세가지 모두를 체크하지 않는다. Ownership에서 User는 "iuser"를 Group은 "agroup"을 적어 준다. "Apply Changes to"는 "All subdirecties and the files"를 선택한다. 이제 Apply 버튼을 체크하면 agroup을 제외하고는 이 디렉토리를 볼 수 없다. 삼바 설정 화면에서 "Create a new file share"를 선택하여 "Share name"에 agroup이라고 적고 "Directory to share"에는 "/home/samba/agroup"을, Available을 Yes로 Browseable을 Yes로 한 후에 "Creat"를 선택하면 삼바 설정화면으로 돌아온다. "Share Name"에 agroup이 만들어져 있는 것을 볼 수 있을 것이다. 이 것을 클릭하면 화면 21이 나온다.
그룹 공유 설정은 home 설정과 거의 비슷하다. "Security and Access Control"에서 화면 15와 같이 하고 단지 "Valid users"와 "Possible groups", "read/write groups" 필드에 agroup을 적어 준다. "File Permissions"(화면 16)에서 "New Unix file mode"를 770으로 "New Unix directory mode"를 770으로 만든다. 이 모드를 사용하면 그룹 사용자들만 읽거나 쓸 수 있고 외부인은 읽을 수도 없다. "Force Unix group"은 agroup적거나 그냥 두어도 된다. 나머지는 고칠 필요가 없다. 저장하고 나온 후에 "File Naming"과 " Miscellaneous Options"은 앞에서 설명한 부분(화면 17,18)과 같이 만들면 된다. agroup과 bgroup이 있으므로 각각에 대해서 만들어야 하지만 지면 관계상 agroup만을 만들었다. agroup만들기를 참고하면 bgroup도 문제없이 만들 수 있을 것이다. 5.12 삼바의 재시작 설정을 바꾸었으므로 삼바를 죽였다가 다시 시작하기로 하자. 리눅스를 리부팅할 필요는 없다. 지난호에 말했던 프로세스 관리 부분에서 할 수 있다. webmin 초기화면에서 "Running process"를 선택하고 smbd,nmbd를 찾은 다음 "send signal" 항목에서 "KILL"을 선택하고 "Send signal" 버튼을 클릭하면 된다. 프로세스 목록에서 smbd, nmbd가 하나도 보이지 않을 때까지 반복한다. 그 후에 삼바 설정화면에 들어와서 새로 생긴 "Start samba servers" 버튼을 클릭하면 삼바가 재기동된다. 화면 22는 윈도우에서 본 삼바서버의 모습이다.
필자의 컴퓨터는 kkyc이며 Linux 폴더를 열었을 때 agroup, kkyc, tmp가 보인다. tmp는 공용 디렉토리로 모든 파일을 볼 수 있으며 kkyc 폴더는 개인 폴더이므로 kkyc 이외에는 볼 수 없으며 agroup 폴더를 열었을 때는 비밀번호를 요구하는 것을 볼 수 있다. 그 이유는 kkyc가 agroup이 아니기 때문이다. 물론 kkyc는 agroup이 아니므로 어떤 비밀번호를 치더라도 이 디렉토리를 볼 수가 없다. 처음으로 리눅스 설정을 한다면 아마 이 글대로 해도 되지 않을 확률이 많다. 윈도우 사용자들은 화면에 나타나는 메세지에 신경을 쓰지 않는 경향이 있다. 물론 윈도우의 메세지는 대부분 의미없는 내용이기 때문인데 그렇다고 리눅스를 설정하면서 윈도우 다루듯이 하면 안된다. 리눅스의 메세지는 정확히 어떤 일이 발생했고 내용이 어떤 것인지 알려 주기 때문에 설정에 실패한다면 화면에 있는 내용을 자세히 바라보고 차분히 진행하기 바란다. 이 글의 내용은 필자의 컴퓨터에서 실제로 테스트한 것이므로 그대로만 따라 한다면 실패하지 않을 것이다. 5.13 쉬운 리눅스를 향하여 이번 달에 설명한 삼바는 현업에서 정말 유용한 것이어서 여분의 PC가 있다면 리눅스를 인스톨하고 꼭 테스트 해 보기 바란다. 여기까지만 제대로 올 수 있다면 앞으로는 일사천리로 리눅스 서버 설정이 가능할 것이다. 앞으로 메일서버, 웹서버, 네임서버, ftp 서버, DHCP 서버까지 구성해 보겠다. 물론 최소한의 리눅스 지식과 웹 방식의 제어로 할 것이다. 가능하다면 사용 중에 문제를 해결할 수 있도록 기본 지식도 제공할 생각이다. 여러분의 적극적인 관심을 바란다. 이제 리눅스는 윈도우 사용자들에게 엄청나게 가까이 왔다. 마음만 먹으면 하루 만에 안정적이고 빠른 파일 서버를 만들 수 있다. 꼭 도전해 보기 바란다. 리눅스에 대해서 알 필요도 없다. 웹 방식의 제어가 윈도우 제어판과 다른 점이 하나도 없다. 필자는 여러분에게 말하고 싶다. 리눅스 서버 만들기, 이 보다 더 쉬울 순 없다. 5.14 이달의 숙제 삼바는 프린트 서버로 사용할 수도 있다. 이 글에서 의도적으로 프린터 서버에 대한 이야기를 뺀 이유는 여러분이 직접 해 볼 수 있도록 하고 다음 연재에서 지루한 삼바 이야기를 잠깐만 하고 넘어가기 위해서 였다. 레이저 프린터는 누구나 쓸 수 있도록 하고 칼라 잉크젯 프린터는 agroup만 사용할 수 있도록 구성하려면 어떻게 해야 할까? 파일 서버에 대한 내용을 자세히 읽고 또 실제로 현장에 적용해 보았다면 쉽게 할 수 있을 것이다. 가능하면 직접 랜이 연결된 상황에서 테스트하면서 해 보기 바란다. 실제로 하다 보면 옵션의 의미가 명확해지며 전체적인 구성에 대해 감이 잡히게 될 것이다. 리눅스 관리는 이렇게 전체에 대한 감을 잡는 것이 중요하기 때문이다. 6. 기업 환경을 위한 리눅스 블랙박스 만들기[6] 6.1 메일서버 세팅과 엑스윈도우 이번 연재에서는 지난달에 이어서 삼바 설정을 마무리하고 윈도우에서 엑스 윈도우를 사용하는 방법을 설명한다. 엑스 윈도우를 윈도우 박스에서 같이 사용하는 것은 리눅스 관리에 많은 잇점을 제공한다. 그리고 리눅스 서버를 여러분 회사를 위한 전용 메일서버로 만들어 보겠다. 리눅스에서 작업하는 내용이 조금씩 나오는데 너무 어려워하지 말고 도전해 보자. 이 글에서 설명하는 내용을 리눅스에서 직접 테스트해 보는 동안 여러분은 어느새 훌륭한 서버 관리자가 되어 있을 것이다. 6.2 숙제 풀이 삼바는 프린트 서버로 사용할 수도 있다. 잉크젯 프린터는 누구나 쓸 수 있도록 하고 레이저 프린터는 agroup만 사용할 수 있도록 구성하고 싶다. 웹민을 이용해서 이 작업을 해 보기로 하자. 우선 웹민 초기화면을 연다. 웹민 설치와 윈도우에서 웹민을 접근하는 방법, 로그인, 초기화면이 나오기까지의 과정은 지난 2,3월 연재를 참고하기 바란다. 초기화면에서 Printer Adminstraion을 선택하면 화면 1이 나온다.
이 것은 리눅스의 lpd(프린터 관리 데몬)이 사용할 /etc/printcap 파일을 편집하는 것이다. Add a new printer를 선택하면 화면 2가 되고 여기서 Printing Configuration의 Name에 lp라고 적는다. Description은 samba가 보게될 프린터 이름이므로 laser라고 적자. 이 포트에 레이저 프린터를 연결할 것이다. Print Destination의 Local device를 선택하고 옆의 옵션 창에서 Parallel port1을 선택한다. 나머지 Printer Driver는 선택할 필요가 없다. 프린터 드라이버는 설정하지 않아도 되는데 이 것은 리눅스에서 직접 프린터를 사용할 때 설정하는 것으로 윈도우에서 프린트하는 목적으로 쓴다면 필요가 없으며 오히려 프린트 속도를 떨어뜨릴 뿐이므로 선택하지 말아야 한다. 리눅스에 연결된 프린트 드라이버는 윈도우의 네트웍 창을 열고 리눅스의 프린터를 선택하면 윈도우에서 설정할 수 있다. 윈도우 응용 프로그램에서 이 프린터로 데이타를 보내면 윈도우가 프린트 이미지를 날려 주므로 리눅스 쪽에서는 그대로 프린트로 보내기만 하면 된다. 이제 설정을 마치고 아래쪽의 create 버튼을 누른다.
마찬가지로 잉크젯 프린터를 위한 설정을 한다. laser 설정과 똑같이 할 수 있으며 Name은 lp1, Description은 inkjet, Local device는 Parallel port2를 적어주면 된다. 이렇게 한 다음 저장한 후의 프린터 모습이 화면 3 이다.
그림과 같이 description과 Print to 항목이 되어 있으면 성공한 것이다. 이제 아래 쪽의 Stop Scheduler를 눌러 lpd를 죽인다. 잠시후에 이 버튼이 Start Scheduler로 바뀌게 된다. 이 버튼을 누르면 lpd가 다시 기동되고 리눅스는 윈도우의 프린트를 받아 들이게 되었다. 삼바에서 프린트 작업을 할 수 있도록 하자. 웹민 초기화면에서 File Share for Windows Networking을 선택하면 화면 4가 나온다.
화면 4에서 printers는 모든 프린트에 대해서 삼바가 프린터 작업이 가능하도록 되어 있음을 보여주고 있다. 삼바는 /etc/printcap을 읽어서 프린터 이름을 파악하고 윈도우 쪽에 이 프린터를 보여 주며 프린트 작업도 가능하게 해 준다. 배포본에 인스톨 되는 삼바 설정 파일은 이 것이 디폴트로 되어 있는 경우가 많다. 이 설정은 모든 프린터에 대해서 아무런 제한 없이 프린터 작업이 가능하게 해 주므로 우리가 원하는 agroup에만 laser를 열어주기 위해서는 Create a new printer share를 선택하여 새로운 프린터 공유 설정을 해 주어야 한다.
화면 5에서 Share name을 선택하고 laser라고 적는다. Unix Printer는 lp로 Spool directory는 /var/spool/samba/lp로 만든다. 나머지 옵션은 기본값을 그대로 사용해도 된다. 이제 아래쪽의 Create 버튼을 누르면 화면4로 돌아오고 laser 항목이 생긴 것을 확인할 수 있다. laser를 선택하면 화면 5로 돌아오고 아래쪽에 새로운 설정 버튼이 생겼다. 그 버튼 중 Security and Access Control을 선택한다(화면 6).
Guest Access는 No로 설정한다. 나머지 설정은 그대로 두어도 좋다. 보안이 중요하고 다른 부서에서 프린트를 할 수 없도록 하고 싶으면 Hosts to allow에서 Only allow를 선택하고 원하는 도메인을 화면과 같이 적어 주면된다. 화면에서는 192.168.1.x, 127.x.x.x, 218.134.186.55 에서만 프린트가 가능하다. 다음에 레이저 프린터는 agroup만 사용할 수 있도록 하기를 원하므로 Valid groups에 agroup를 적어 준다. Save 버튼을 누르고 나면 화면 5로 바뀌게 되고 다시 여기서 Save버튼을 눌러 준다. 화면 7은 두가지를 보여준다. 우선 위에서 말한 모든 설정이 되어 있으며 /etc/printap에 lp로 되어 있는 프린터 포트를 윈도우에서 laser로 사용할 수 있음을 보여 주며 나머지 프린터들은 printers 그룹에 들어 있고 이 것은 모든 프린터에 대한 접근을 허가 하고 있음을 보여 준다. 물론 lp는 printers항목에 속해 있지만 lp를 위한 설정이 따로 되어 있으므로 printers의 설정보다는 laser 설정이 우선한다. 그다음으로 화면 7이 보여주는 것은 웹민의 바로 이 화면을 laser로 프린트 시켰을 때 netscape가 실행되어 있는 컴퓨터의 사용자가 agroup이 아니기 때문에 비밀번호를 요구하고 있는 모습이다. 물론 agroup이 아니므로 어떤 비밀번호를 사용해도 프린트를 할 수 없다.
6.3 웹 방식 작업의 한계 웹민과 linuxconf는 다양한 서버관리 작업을 웹방식으로 할 수 있도록 해주는 프로그램이다. 사실 거의 모든 작업을 이 프로그램을 사용해 처리할 수 있다. 그러나 삼바설정에서 보듯이 반복되는 단위작업을 블랙박스화하거나 자동화하기가 힘들다. 그리고 시스템 관리 작업이 이런 프로그램에서 제공하는 인터페이스로는 가능하지 않는 것도 존재한다. 웹방식으로 제어를 하더라도 시스템 전체에 대한 지식이 없으면 내부 동작을 이해하기 힘들고 그 때문에 설명해주지 않은 작업은 하기 힘들다. 예를 들어 삼바 설정을 위해서 사용자 만들기, /etc/hosts 파일 편집하기, 삼바 재기동하기등에 대해서 설명했지만 필자는 이런 작업이 있어야 한다는 것을 먼저 알고 있기 때문에 웹민에서 그 작업이 가능한 인터페이스를 찾아서 할 수 있지만 일반 윈도우 사용자들은 삼바 설정만 만질 수 있을 뿐 /etc/hosts 파일을 편집할 필요가 있다는 것은 알기 힘들다. 다시 텍스트 방식의 삼바 설명서가 필요하고 vi가 필요하게 되는 것이다. 그러므로 필요한 기능을 구현하기 위해서 적절한 작업이 어떤 것인지 파악하기 위해서는 어느 정도 리눅스에 직접 로그인할 필요가 있다. 리눅스에서 직접 작업하는 것과 웹방식으로 작업하는 것의 차이는 다음과 같다. 숙제풀이에서 설명한 작업은 리눅스 로그인해서 다음과 같이 할 수 있다.
1번과 2번은 vi를 불러서 몇줄을 추가하고 3번은 커멘드 라인에서 실행하면 된다. 알고나면 간단한 이런 작업을 위해서 많은 지면을 할당해야 하는 것이다. 숙제풀이에서 말하지 않았지만 laser에 필요한 스풀파일용 디렉토리 /var/spool/samba/lp는 자동으로 만들어지지 않으며 이 디렉토리를 만들지 않으면 laser에 대한 프린트 작업이 제대로 되지 않을 것이다. 그러므로 로그인한 상태에서 다음 작업을 추가해야 한다. # mkdir /var/spool/samba/lp 물론 이 작업도 지난 달에 얘기한 웹민의 File Manager 설정을 이용해 할 수 있다. 어떤 쪽을 사용할 것이지는 여러분에게 달렸지만 로그인해서 작업하는 것이 리눅스 관리 작업을 더 빨리 이해할 수 있는 길임을 말해 둔다. 삼바가 프린트하는 과정은 다음과 같다. 윈도우에서 laser에 프린트를 하면 삼바가 일단 넘어오는 데이타를 /var/spool/samba/lp/에 임의의 이름(raw-data라고 하자)으로 저장한다. 그 후에 lpr -Plp /var/spool/samba/lp/raw-data가 실행되어 로컬 프린팅을 시도한다. 즉 삼바의 프린트 작업은 리눅스에서 직접 프린트하는 것과 같고 한 번의 프린트 작업을 위해서는 그 프린트 이미지의 2배에 해당하는 공간이 필요하다. 왜냐하면 삼바가 임시로 저장하는 영역과, lpr또한 프린트 이미지를 일단 저장하므로 이 때 사용할 영역이 있어야 하기 때문이다. 웹민을 이용한 제어를 삼바설정에 이용할 때 수많은 삼바의 설정을 모두 처리할 수가 없고 단위 반복 작업이 줄어들지 않는다. 필자는 가능하면 리눅스에 로그인해서 작업할 수 있을 실력을 여러분이 기르기를 바란다. 그 때까지는 웹민과 같은 웹방식 제어를 쓸 수 있지만 어디까지나 임시방편이라는 점을 기억하도록 하자. 6.4 윈도우에서 엑스윈도우를 사용한다 웹방식의 제한을 뛰어 넘어 시스템 전체에 대한 이해를 하기 위한 방법은 여러가지가 있다. 윈도우에서 telnet을 사용할 수 있다. 터미널 방식에 익숙한 사용자들은 별 문제 없겠지만 윈도우 사용자들이 겪는 리눅스에 대한 어려움이 여전히 남는다. 또한 윈도우용 telnet 클라이언트들은 80x25 크기의 vt100(혹은 vt220)모드를 사용해야 하는데 어떤 프로그램은 이 방식도 제대로 지원해 주지 못한다. vi를 사용했을 때 화면이 밀리거나 첫줄이 보이지 않는 등의 문제가 발생하는 경우는 이 때문이다(화면 8). 화면에서 보듯이 커서가 있는 가장 아랫 줄이 겹쳐져서 나타난다. 이 문제는 텔렛으로 들어간 후에 export TERM="vt100" 설정을 해 주면 되지만 매번 하기에는 귀찮은 일이다.
또한 최근의 경향은 각종 프로그램들이 각자의 설정을 위한 프로그램을 그래픽 방식으로 제공하고 있는데 이들은 거의 엑스 윈도우 프로그램이다. 서버용 리눅스 박스에 모니터와 키보드를 붙여 놓으면 공간을 많이 차지할 뿐 아니라 로그인 해 놓고 자리를 비운 사이에 다른 사람이 건들 수도 있다. 이런 문제가 없다고 해도 가끔 발생하는 설정 작업을 위해서 리눅스 박스로 가야한다. 물론 엑스 윈도우를 띄우기 위한 설정 작업도 쉬운 일이 아니다. 필자는 여러달 윈도우 사용자들에게 쉬운 리눅스 접근을 고민해 왔는데 그 과정에서 아주 쓸만한 프로그램을 찾을 수 있었다. 바로 윈도우용 엑스 윈도우 서버 프로그램이다. 윈도우용 엑스 윈도우 서버는 종류가 많지만 거의 외국 제품이라 한글 문제가 자유롭지 못하다. 외국 제품을 국내에 들여와 한글이 되도록 작업한 것들이 대부분인데 한글 문제를 완전히 해결한 것은 찾기 힘들다. 리눅스를 쉽게 사용하기 위해서 쓰려는 엑스 윈도우 서버를 제대로 동작시키기 위해서 먼저 리눅스를 공부해야 하는 앞뒤가 바뀌는 문제 때문에 필자도 거의 엑스 서버에 대해서 관심을 두지 않았다. 그러나 최근에 윈도우용 엑스 윈도우 서버 중에서 국내 개발품이 있으며 이 것이 엑스 서버의 기능에 충실할 뿐만 아니라 완벽하게 한글을 지원하고 있다는 사실을 알게 되었다. 이 제품은 유닉스 웍스테이션에서 작업하는 개발자들이 유닉스 환경과 윈도우 환경을 동시에 한 PC에서 사용하기 위해서 필요한 것이지만 리눅스 서버의 설정 작업을 위해서도 쓸모가 있다. 상용 제품이지만 한달 동안 테스트해 할 수 있도록 기능 제한 없는 데모 버전을 제공하고 있다. 흥미 있는 독자는 http://www.netsarang.co.kr을 방문해 보기 바란다(화면 9).
### 글쓴이 주 : netsarang 홈페이지 화면은 꼭 실어 주세요. 국내 제품 키워 줍시다. 필자는 노트북에서도 리눅스를 사용하고 있었는데 이 Xmanager를 테스트 해보고 노트북에 윈도우를 인스톨해서 사용하고 싶어졌다. 엑스 윈도우 환경을 완벽하게 지원하고 리눅스에서 부족한 멀티미디어 유틸리티 프로그램을 자유롭게 쓸 수 있다는 것은 대단한 매력이 아닐 수 없다. 비록 필자는 리눅스의 이멕스로 글을 쓰지만 워드 프로세스에 익숙한 사람이 리눅스에 대한 글을 쓰면서 리눅스의 동작 화면을 갈무리하는데 사용한다면 엄청난 효율이 있을 것으로 생각된다. 이 글도 Xmanager위에서 리눅스 이멕스를 불러와서 쓰고 있으며 리눅스에서 직접 작업하는 것과 전혀 차이가 없음을 말하고 싶다(화면 10). 화면에서 보듯이 리눅스용 넷스케입과 윈도우용 넷스케입이 각각 떠있고 이멕스 화면과 한텀 화면을 볼 수 있다. 또한 화면 오른쪽은 리눅스용 window maker 엑스윈도우 메니저의 버튼이 있다. 윈도우에서 리눅스 엑스 윈도우용 프로그램을 마치 윈도우용 프로그램처럼 사용할 수 있는 환경을 독자들도 경험해 보기 바란다. 이 제품은 유닉스를 전문적으로 사용하는 곳을 대상으로 하여 리눅스 사용자들에게는 가격이 비싼 편이다. 필자가 개발사에 이 부분에 대해서 문의했는데 최근에 리눅스 사용자들이 급증해 리눅스를 위한 제품을 따로 개발하는등의 작업이 진행되고 있다고 한다. 앞으로 리눅스를 서버로 사용하는 사람들을 위한 배려가 있을 것이라는 답변을 들었다. 독자들이 이 글을 보게 될 시점에는 홈페이지에 이에 대한 언급이 있을 것으로 기대한다. 6.5 Xmanager를 리눅스 서버에 붙이기 Xmanager는 윈도우에서 간단히 인스톨 할 수 있으며 설정도 쉽다. 문제는 리눅스 쪽에서 윈도우용 엑스 서버가 접속할 수 있도록 해 주는 일이다. 리눅스가 부팅하면서 Xmanager 접속을 허용하도록 하기 위해서는 /etc/rc.d/rc.local에 다음을 추가해 주면 된다. /usr/X11/bin/xdm 물론 리눅스 서버에 엑스 윈도우에 관련된 프로그램은 인스톨되어 있어야 한다. 배포본을 그대로 인스톨했다면 모두 제대로 되어 있을 것이다. 리눅스 박스에 마우스를 붙이지 않았다면 xdm이 기동하면서 엄청난 로그파일을 뿌릴 것이고 이 것이 /var/log가 있는 디렉토리를 꽉채울 것이다. 그러므로 다음 설정이 필요하다. /etc/X11/xdm/Xservers 파일의 원래 모습 :0 local /usr/X11R6/bin/X 이 것을 아래와 같이 바꾼다. :0 local /usr/X11R6/bin/X -allowMouseOpenFail 제대로 바꾸었다면 커멘드 라인에서 xdm을 실행한다. 이제 윈도우의 Xmanager를 실행하고 리눅스 서버의 IP 주소등을 제대로 설정하면 그래픽 방식의 로그인 화면을 볼 수 있다. 로그인을 정상적으로 했다면 화면 10과 같이 윈도우에 실행된 엑스 윈도우를 볼 수 있을 것이다. 엑스 윈도우를 사용할 수 있으면 가장 먼저 xterm 터미널을 제대로 지원하는 한텀을 실행할 수 있다. 한텀은 크기를 마음대로 조절할 수 있고 vi같은 프로그램들도 바뀐 크기를 인식하기 때문에 아주 편한 터미널이라는 것을 깨닫게 될 것이다. 한텀을 쓸 수 있다는 것 만으로도 Xmanager를 사용할 가치가 있다. 이제 freshmeat.net을 방문했을 때 엑스윈도우용 시스템 관리 유틸리티가 있으면 적극적으로 다운 받기 바란다. 웹민이나 linuxconf가 해결해 주지 못하는 세세한 부분을 위한 이런 프로그램들을 적극 활용할 수 있으므로 리눅스 관리가 엄청 편해 질 것이다. 필자는 연재를 진행하면서 엑스 윈도우에서 사용할 수 있는 다양한 설정 프로그램들을 소개할 예정이며 필요하다면 터미널 작업에 대한 내용도 보일 것인데 기본적으로 웹민이나 linuxconf 그리고 윈도우용 엑스 서버가 설치되어 있다고 가정을 하겠다. 6.6 박스 기사 : 엑스 서버에 대한 기초 지식 엑스 윈도우는 서버/클라이언트 개념을 구현한 그래픽 환경이다. 윈도우 사용자들이나 클라이언트/서버 시스템에서 작업하던 사람들이 혼란스러워하는 경우가 있는데 그 이유는 일반적인 C/S 개념의 반대로 엑스 윈도우가 동작하기 때문이다. 엑스 윈도우는 최소한의 그래픽 환경을 위해서 필요한 작업, 즉 화면을 관리하는 일, 사용자들의 입출력을 처리하는 일, 그리고 글꼴을 관리하는 작업만을 서버가 처리한다. 그 나머지는 클라이언트의 몫이다. 그러므로 리눅스에 XDM이 떠 있고 윈도우에 Xmanager가 떠있다면 서버는 윈도우 쪽의 Xmanager이다. 왜냐 하면 Xmanager가 여러분의 키 입력을 처리하기 때문이다. 그리고 리눅스 서버에 있는 리눅스용 netscape을 실행했을 때 이 것은 윈도우 쪽의 Xmanager에게 화면을 그려줄 것을 부탁한다. 윈도우의 Xmanager 서버는 그 요청에 따라 윈도우가 떠있는 컴퓨터의 모니터에 화면을 표시한다. 그러므로 리눅스 서버의 프로그램들이 클라이언트가 되고 XDM은 이들을 연결하는데 필요한 프로토콜을 제공할 뿐이며 서버는 윈도우에 실행 중인 Xmanager이다. 이와같이 Xmanager라는 윈도우용 엑스 윈도우 프로그램은 서버로 동작하며 리눅스에서 실행한 엑스 윈도우와 플랫폼만 다를 뿐 완전히 동일한 것이다. 넷스케입 프로그램은 실행 파일이 윈도우 쪽으로 넘어오는 것이 아니고 리눅스 박스에서 실행된 후에 그 결과 화면만 넘어 오는 것이다. 때문에 리눅스용 실행 파일을 윈도우에서 실행할 수 있으며 넷스케입의 수행 속도는 윈도우 박스가 아닌 리눅스 박스의 성능에 영향을 받는다. 이 것은 윈도우의 공유 개념과 완전히 다른 것으로 윈도우에서는 다른 컴퓨터에 있는 프로그램을 실행하면 그 실행 이미지가 넘어와서 실행 시킨 사용자가 있는 컴퓨터에서 실행되므로 윈도우의 공유 개념은 파일 저장 매체의 공유에 불과한 것이다. 더구나 엑스 윈도우는 화면을 제어하는 메니저 프로그램도 클라이언트로 분리되어 있다. 그 때문에 윈도우나 맥과 달리 엑스 윈도우에는 여러가지 윈도우 메니저 프로그램이 있다. 또한 엑스 서버는 이들 클라이언트 프로그램과 완전히 독립적으로 구성되어 있어서 윈도우 메니저나 응용 프로그램과 X프로토콜을 통해서 통신을 하는 방식으로 동작하며 같은 컴퓨터에서 실행했다고 해서 이들 프로그램과 더 빠른 방식을 사용하지는 않는다. 극단적으로 말해서 엑스 서버는 입출력 기능만 제공하는 하얀 바탕화면만을 가진 프로그램이라고 생각할 수 있다. 필자가 유닉스에 관심을 가지게 된 이유가 바로 엑스 윈도우를 사용하고 싶어서였다. 윈도우도 없던 10년전에 이미 엑스 윈도우는 클라이언트/서버 개념을 구현했고 현장에서 사용되고 있었다. 빛을 잃던 유닉스가 인터넷의 활성화 때문에 재조명 되고 있듯이 실패한 접근법으로 평가받고 있는 엑스 터미널이 NC와 달리 사라지지 않고 리눅스의 등장으로 새롭게 관심을 끌고 있다. 윈도우를 보조해 줄 수 있고 윈도우보다 기술적으로 매력있는 엑스 윈도우를 여러분의 컴퓨터에서도 사용해 보기를 바란다. 6.7 메일 서버의 설정 삼바가 잘 돌고 있다면 이제 여러분의 회사를 위한 전용 메일 서버를 만들어 보기로 하자. 공개메일 서버가 많지만 거의다 웹방식으로 되어 있어서 메일이 도착하는 즉시 알기 힘들 뿐 아니라 메일 읽는 시간도 많이 걸린다. 그리고 여러분의 회사 도메인을 사용할 수 없어서 거래 상대방에게 신뢰를 주기 힘들며 최근에 이메일 이름으로 많이 사용하는 방식인 이름첫자+성(홍길동일때 kdhong 처럼 쓰는 것) 방식을 쓸려고 해도 다른 사람과 겹치는 경우가 많아서 원하는 사용자명을 쓰기도 힘들다. NT에서 동작하는 메일 서버는 가격이 만만찮고 메일서버를 위한 전용 서버를 따로 사용할 것을 권하고 있으므로 신뢰성을 위해 들여야 하는 비용이 만만찮다. 그러나 인터넷 메일 전송을 위한 프로그램으로 가장 높은 점유율을 가지고 있는 sendmail을 리눅스에서도 사용할 수 있다. 삼바 서버에 sendmail을 설치하여 여러분만의 도메인에 여러분이 원하는 사용자명을 가져 보도록 하자. 6.8 메일 서버의 인스톨 배포본을 인스톨 했다면 이미 sendmail이 동작하고 있을 것이다. 웹민의 Running Processes를 선택해 보거나 한텀을 열고 "ps axf"라고 치면 동작 중인 sendmail을 볼 수 있다. 만약 동작하고 있지 않다면 배포본에서 sendmail-xx.rpm으로 된 것을 인스톨하면 된다(rpm을 사용해서). 하지만 sendmail이 인스톨되어 있지 않거나 동작하고 있지 않는 경우는 일부러 삭제하지 않는 한 있을 수 없는 일이다. sendmail은 기동하면서 IP주소를 인식하기 때문에 리눅스 서버에 IP가 할당되어 있고 그 IP가 인터넷에 유효한 것이라면 거의 모든 경우 인스톨 되어 있는 그대로 사용해도 인터넷에서 메일을 주고 받을 수 있다. 이 글의 목적은 하루에 수만통의 메일을 주고 받고 있는 대규모 사이트에 대한 설명을 하려고 하는 것이 아니므로 복잡한 사항에 대해서는 언급하지 않겠다. 설명 대상은 하루에 100여통 정도의 메일을 주고 받고 사용자들은 윈도우에서 메일을 읽는다고 가정하겠다. 6.9 메일 서버 세팅 메일 서버는 컴퓨터가 부팅하면서 /etc/rc.d/init.d/sendmail에 의해서 기동된다. 여러분의 파일은 아마 다음과 같을 것이다. .... sendmail /usr/sbin/sendmail -bd -q1h .... 또는 .... daemon /usr/sbin/sendmail -bd /usr/sbin/sendmail -q10m /usr/sbin/sendmail -OQueueDirectory=/var/spool/mqueue2 -q65m /usr/sbin/sendmail -OQueueDirectory=/var/spool/mqueue3 -q4h .... 어느 쪽이던 상관없다. 양쪽다 소규모 메일 서버에 적당한 모습니다. 참고로 말하자면 첫번째 방법은 한 개의 sendmail이 메일 받기(-bd)와 아직 보내지 못한 메일 전송하기(-q1h)를 모두 담당한다. 두번째는 이 것을 분리하여 한 개의 sendmail은 받기 만을 전담하고 나머지 세개의 sendmail이 각각 10분(-q10m), 65분, 4시간 단위로 전송에 실패해서 큐에 들어 있는 메일을 다시 보내려고 시도하게 된다. 효율은 두번째가 조금 좋은 편이지만 첫번째 설정을 구태여 아래처럼 바꿀 필요는 없다. 그리고 mqueue2같은 큐 분리에 관한 것은 복잡한 문제이며 소규모 사이트에는 필요가 없으므로 언급하지 않겠다. 주소가 잘못되었거나 상대편 컴퓨터가 잠시 꺼져 있는 상태라면 메일 보내기에 실패하게 되고 이 메일이 /var/spool/mqueue에 저장된다. sendmail은 1시간 단위로 이 디렉토리를 검색해서 전송에 실패한 메일이 있으면 재전송 작업을 하므로 가끔 이 디렉토리를 조사해 보는 것이 좋을 것이다. 왜냐하면 중요한 메일을 보내면서 주소를 잘못 써 전송이 되지 못하고 남아 있을 수 있는데 상대편이 답답하다면 따로 연락이 오겠지만 이쪽이 아쉬운 상태에서 메일을 제대로 보내지 못했다면 낭패를 당하기 때문이다. 6.10 메일 사용자 만들기 회사의 직원들이 원하는 사용자명을 받아서 리눅스 서버에 등록해 주어야 한다. 웹방식으로 하는 것은 지난 달에 설명을 했다. 간단히 설명하자면 웹민 화면에서 Users, Groups and Passwords를 선택하고 다시 Create a new User를 선택하면 된다. 사용자명과 비밀번호만 제대로 설정할 수 있다면 쉽게 설정할 수 있을 것이다. 텍스트 방식으로 하는 것은 엑스윈도우를 기동하여 한텀을 열거나 telnet으로 리눅스에 로그인한 다음과 아래와 같이 하면 된다. # adduser newuser # passwd newuser 이제 리눅스에서 메일 보내기에 대한 기본 작업은 이루어 졌다. root 사용자로 newuser에게 메일을 보내보기 바란다. 커멘드 라인에서 보낼 수도 있지만 쓸만한 메일 클라이언트인 mutt나 elm또는 pine이 있다. 이 중에 하나는 인스톨되어 있을 것이므로 그 것을 사용하면 된다. 보낸 메일이 제대로 갔다면 /var/spool/mail/newuser 파일이 만들어져 있을 것이고 그 내용은 방금 보낸 메일이다. 메일이 제대로 갔음을 확인하고 나서 차례로 나머지 사용자를 만들자. 6.11 박스 기사 : 메일 전송에 대해서 인터넷에서 주고 받는 이메일은 여러 경로를 거쳐서 전송이 된다. 우선 메일을 작성하는 프로그램은 MUA(Mail User Agent)라고 부른다. 넷스케입 메일 작성 프로그램이 이에 해당된다. MUA는 사용자의 입력을 받아서 형식에 맞는 메일을 만들어 낸다. 그 후에 이 메일을 sendmail 같은 MTA(Mail Transfer Agent)에게 보내기 위한 프로그램 즉 MDA(Mail Delivery Agent)가 메일을 처리한다. MDA는 같은 컴퓨터 내에 있는 사용자들 끼리의 메일을 처리하는 작업이나 MTA에 메일을 전달하는 일을 한다. 윈도우에서는 넷스케입이 이 기능도 맡고 있다. MTA는 메일을 받아들여 메일전송 프로토콜(SMTP)에 따라 메일을 다른 MTA에 전송하는 역활을 한다. 윈도우에는 이 프로그램이 없으며 NT나 유닉스 서버에 있다. 그래서 윈도우 메일 관련 프로그램 설정을 하면서 Outgoing 메일 서버를 지정하는 것이다. 리눅스는 그 내부에 mutt등의 MUA와 procmail같은 MDA 그리고 MTA인 senadmail 서버가 같이 동작하므로 스스로 메일을 만들고 다른 서버의 도움없이 메일을 주고 받을 수 있다. 그러나 윈도우 사용자들은 반드시 메일서버를 지정해야 메일을 보낼 수 있으며 인터넷 메일을 직접 받을 수도 없고 사용자명을 등록해 놓은 서버에서 메일을 "긁어"와야 한다. 넷스케입의 메일 받기 버튼을 누르면 넷스케입은 서버에 pop3, imap등의 프로토콜을 사용해서 접속한 다음 도착해 있는 메일을 가져오는 것이다. 리눅스 사용자들은 메일서버가 없는 컴퓨터를 이상하게 생각하는 반면 윈도우 사용자들은 메일서버 지정이 필요없는 리눅스를 이상하게 생각한다. 웹메일은 서버에 웹인터페이스를 가진 MUA를 제공하고 같은 서버에 메일을 저장했다가 웹방식으로 메일을 볼 수 있게 해 준다. 웹메일은 사용자들이 계속 방문하게 할 수 있으므로 광고를 할 목적으로 메일을 주고 받게 해 주는 것이므로 pop같이 사용자가 웹으로 접속하지 않고도 메일을 가져갈 수 있도록 해주지는 않기 때문에 메일을 주고 받는 본래의 용도로 사용하기에는 무리가 있다. 최근에는 광고성 메일인 스팸(spam) 메일이 급증하고 있어서 메일을 전송해 주는 MTA가 동작 중인 컴퓨터들이 몸살을 앓고 있다. 이런 스팸 메일은 수만통의 메일을 한 메일 서버에게 전송을 요청하기 때문에 이들을 전송하느라고 정작 처리해야할 메일은 보내지 못하는 경우가 많아졌다. 이 때문에 최근에는 허가된 IP 이외에서 보내오는 메일은 전송을 해주지 않는다. 그래서 스팸 메일을 보내는 사람들은 전송을 허락하는 메일서버를 찾아 다니고 있다. 리눅스 배포본의 sendmail은 누구라도 메일 전송을 요청할 수 있었지만 최근에는 따로 설정하지 않으면 메일 중계를 해 주지 않도록 바뀌었다. 버전이 낮은 배포본을 사용하고 있다면 스팸메일 전송을 하지 않도록 조심해야 한다. 한 번 스팸메일을 전송해 준 서버는 블랙리스트에 올라서 그 후에는 다른 메일 서버가 이 서버에서 보내오는 메일은 스팸메일로 분류하여 정상적인 메일도 받아들이지 않기 때문이다. 리눅스 서버를 구성하면 MTA, MDA와 pop3(혹은 imap)을 사내에 구성할 수 있고 사용자들이 편하게 메일을 보낼 수 있으며 몇분 단위로 메일이 왔는지 확인할 수 있으므로 적극 사용을 권장할 만하다. 삼바가 같이 구동되고 있는 서버에 설치하더라도 거의 성능에 영향을 미치지 않는다. sendmail은 100만명을 수용하는 메일 서버에서도 사용하고 있는 프로그램이며 리눅스용 sendmail도 동일한 프로그램이니까 성능에 의심을 하지 않아도 좋다. 6.12 한글 메일의 처리 한글 메일 처리 방식은 sendmail을 패치하는 방법이 있었지만 최근에는 sendmail이 8비트 처리를 해주므로 이 방법을 거의 사용하지 않는다. 대신에 잘못 인코딩되어 오는 메일을 로컬의 procmail을 이용해서 처리하는 방법이 주로 사용된다. 신정식씨와 이상로씨가 제안한 방법이며 http://pantheon.yale.edu/ jshin/faq에 가면 필요한 파일을 구할 수 있다. 현재 한글 리눅스로 유명한 알짜에서는 sendmail-8.9.2버전에 procmail을 처리하는 기능을 추가했다. 알짜 5.2이상이면 이 기능이 포함되어 있다. /etc/procmailrc 파일에 EUC-KR이라는 문자열을 볼 수 있다면 그 처리가 되어 있는 것이다. 그렇치 않다면 ftp사이트에서 sendmail-8.9.2-kr버전을 찾아 보기 바란다. 사실 90%이상이 윈도우에서 메일을 작성하고 받는 사람도 90%이상이 윈도우를 사용하기 때문에 전송과정의 메일 서버가 이상하지 않다면 이런 처리가 없어도 한글 메일이 잘못되는 경우는 거의 없을 것이다. 6.13 윈도우에서 메일 보내기 윈도우에서 메일을 보내기 위해서 리눅스 서버를 사용한다면 Outgoing 메일서버 설정에서 리눅스 서버의 IP를 적어 준다. 리눅스에서 해야 할 것은 메일 중계를 허용하도록 하는 것이다. 웹민의 초기화면에서 Sendmail Configuration을 선택한다(화면 11).
sendmail은 수많은 설정을 가지고 있고 다양한 옵션을 사용할 수 있지만 하루 100 통 정도의 메일을 주고 받는 사이트에서는 배포본의 설정을 거의 고치지 않아도 좋다. 사이트가 커지면 그 때 따로 연구하기로 하고 지금은 최소한의 설정만 고치기로 하자. 우선 회사의 도메인 안에 있는 PC에서 메일을 전송할 수 있도록 설정을 한다. 한 회사의 컴퓨터는 대부분 같은 도메인을 가지고 있으므로 이 것도 고칠 필요가 없지만 다른 도메인이나 한 개의 IP를 사용하고 masquerade 방식으로 운영한다면 고칠 필요가 있다. Relay Domains를 선택하고(화면 12) 여기에 회사의 모든 도메인을 적어 준다(호스트명이 아니다). 필자는 한 개의 IP를 가지고 있고 내부 랜은 masquerade를 사용하고 있으므로 내부적으로 쓰는 a.b.c와 인터넷에서 부여받은 도메인 명을 적었다. 여러분의 회사가 mycompany.co.kr 도메인을 가지고 있다면 그 도메인을 적어 주면 된다. 이제 a.mycompany.co.kr에서 보내는 메일을 리눅스가 전송해 줄 수 있게 되었다.
윈도우에서 메일을 보낼 때 From: 필드에 user@mycompany.co.kr이라고 적고 메일을 보낼 수 있다. 필요하다면 Reply-To: 필드에도 같은 내용을 적어 주기 바란다. 드디어 여러분 회사를 위한 전용 메일서버가 만들어 졌다. 참고로 엑스에서 같은 작업은 /etc/mail/relay-domains 파일을 만들고 아래와 같이 적어 주면 된다. a.b.c kppinc.com 6.14 윈도우에서 메일 받기 여러분에게 오는 메일은 리눅스 서버에 도착하게 된다. 이 메일은 윈도우에서 직접 가져 올 수 있으며 이를 위해서 popd 프로그램 설정이 필요하다. 웹민의 Internet Service and Protocols을 선택하면 백개 이상의 서비스 종류가 나타나며 internet Services에서 잘 살펴 보면 pop-3를 찾을 수 있다(화면 13).
pop-3를 선택하면 화면 14를 볼 수 있다. 여기서 가장 중요한 것은 Server Program에서 Program enabled가 선택되어 있고 TCP-Wrapper가 선택되어 있으며 인자값으로 ipop3d가 설정되어 있어야 하는 것이다. 나머지는 그대로 두면 된다. 이제 저장하고 나오면 화면 13으로 돌아온다. 한 화면에 너무 많은 서비스가 있어서 화면에 안보이는데 설정을 고치고 나서 화면 13의 가장 아래쪽에 있는 Apply Changes 버튼을 찾아서 눌러 주어야 한다. 참고로 엑스에서 같은 작업은 한텀을 열고 /etc/inetd.conf 을 아래와 같은 줄을 찾아 가장 첫칸의 #를 제거하면 된다. #pop-3 stream tcp nowait root /usr/sbin/tcpd ipop3d #imap stream tcp nowait root /usr/sbin/tcpd imapd 이 파일을 저장하고 나서 커멘드 라인에서 다음과 같이 실행하면 새 설정이 인식된다. # killall -HUP inetd 넷스케입에서 Edit-> Preferences-> Mail & Newsgroups-> Mail Servers-> Incoming Servers 항목에 리눅스 IP를 적어주고 다시 넷스케입에서 Communicator-> Messenger를 선택하여 도착한 메일을 가져올 수 있다. 이 부분은 필자보다 여러분이 더 잘할 것이다. 필자는 메일을 리눅스에서 주고 받기 때문에 윈도우쪽의 구체적인 설정은 잘 알지 못한다. 어디에 있는지는 모르지만 넷스케입을 사용하면서 몇 분 단위로 메일이 왔는지 확인하는 옵션이 있으므로 이 옵션을 켜 놓는다면 도착한 메일을 금방 읽을 수 있을 것이다. 6.15 sendmail의 보안 문제 sendmail은 뛰어난 성능과 다양한 옵션과 함께 수많은 보안 문제도 가지고 있다. 실력이 된다면 보안관련 사이트를 자주 검색하면서 리눅스 박스를 안전하게 만들 수 있지만 아직 리눅스에 익숙하지 않은 사람은 크게 신경쓰지 않아도 된다. 배포본은 어느 정도 안정성을 기울이고 있으며 너무 오래된 배포본이 아니라면 큰 문제는 없다. 현재 sendmail-8.9.1a이하는 몇가지 문제를 가지고 있으며 이를 해결한 8.9.2가 배포본에 포함되어 있다. sendmail의 버그에 대해서 너무 걱정하지 말 것. 크래커들은 알려진 유명한 사이트를 뒤지고 다니기를 좋아할 뿐 소규모 사이트에는 별 관심을 기울이지 않는다. 해킹은 사실 어려운 기술이며 크래커의 공격 대상이 될 확률은 별로 없다. 보안에 무관심해서도 안되겠지만 너무 걱정할 필요도 없다. 리눅스 서버를 운영하고 있으면 자연스럽게 리눅스 보안 문제에 대한 경고문을 접하게 될 것이고 그 즉시 패치 파일을 구할 수 있다. 그런 글을 이해할 수 있는 수준이 되면 보안 패치를 하는 방법을 알게 될 것이다. 시작 단계부터 보안을 걱정할 필요는 없다. 일단 시작하고 문제는 그 후에 해결하도록 하자. 6.16 메일 서버에 대한 나머지 얘기 이번 호로 삼바 설정에 대해서 마쳤다. apache 웹서버와 함께 리눅스 킬링 소프트웨어의 하나인 삼바와 sendmail에 대한 설명이 소규모 사이트를 대상으로 하다 보니까 자세한 내용을 실을 수는 없었지만 이 정도의 내용만 따라 하더라도 웬만한 회사의 파일서버, 프린터 서버, 메일서버로 리눅스를 사용하는데 어려움이 없을 것이다. 앞에서 보여 주었지만 배포본에 들어 있는 /etc/rc.d/init.d/sendmail을 고치지 않고도 하루에 4만통의 메일을 2년여 동안 큰문제 없이 주고 받고 있는 사이트가 있다. 삼바 서버는 이 글에서 다루는 정도의 설정을 할 수 있다면 중급 수준 이상의 관리자라는 소리를 들을 수 있다. 글을 읽으면서 전체의 맥락을 파악한다면 응용도 할 수 있을 것이다. 이 번달에는 소규모 사이트의 메일 서버에 대해서 알아 보았다. 이 글에서 설명하는 수준의 설정법에 대해서는 이미 알고 있고 좀 더 자세한 부분이 궁금하거나 특별한 설정에 대해서 알고 싶은 사람이 있다면 sendmail 관련 책을 참고 하거나 KLDP사이트 등을 조사해 보기 바란다. 여러 도메인을 처리하거나, 전송하는 메일의 헤더를 일정하게 수정하는 방법 또는 여러 사이트로 받은 메일을 전달하는 방법등 sendmail이 제공해 줄 수 있는 기능은 상당히 많으며 이 기능을 활용하고 있는 사이트도 많고 그 방법에 대해서 자세히 설명하고 있는 문서도 쉽게 구할 수 있다. 무엇보다도 웹민의 sendmail configuration 부분을 하나씩 살펴 보기 바란다. 서로 연관되지 못하고 옵션마다 한 줄씩 설명이 있는 메뉴얼 페이지나 모든 옵션에 대해서 너무 자세히 설명이 되어 있어서 오히려 어려운 책들 보다 웹민의 설정 페이지가 훨씬 전체적인 이해를 하는데 도움이 된다. 웹민의 sendmail 설정을 몇 번 해보면 웬만한 관리자보다 훨씬 더 나은 실력을 가질 수 있다. 리눅스인지 윈도우인지 헷갈리게 만드는 Xmanager 위에서 이 글을 쓰고 있는데 상당히 쓸만한 프로그램이라고 생각이 된다. 특히 유닉스 관련 프로그램이면서 국내 제품인 Xmanager가 일반 범용 패키지 제품 정도의 완성도를 가지고 있고 성능도 상당히 쓸만해서 필자가 적극적으로 소개했다. 한글에 대한 완벽한 지원이 가능한 제품은 한국 사람들이 가장 잘 만들어 낼 수 있으므로 이런 제품이 활성화되고 사용자들의 관심이 높아져야 더욱 개발이 활발하게 될 것이다. 마찬가지로 여러분의 관심을 바란다. 6.17 이달의 숙제 여러분의 사이트가 별로 메일을 보내지는 않지만 가끔 관계자들에게 공지 메일을 보내는 경우가 있다. 이 때에는 약 1500통의 메일을 윈도우에서 만들어 보내게 되는데 이 정도의 메일을 한꺼번에 서버에 중계를 요청하게 되면 즉시 메일이 가지 않고 큐에 쌓였다가 전송이 된다. 그 지연이 생각보다 길어서 어떤 경우에는 4시간이 지나서야 메일이 보내지는 경우도 있다. 메일서버는 전송할 메일이 갑자기 늘어나면 즉시 전송하지 않고 일단 큐에 저장을 하고 나중에 이 메일을 보내려고 한다. 가능하면 메일을 큐에 쌓아 두지 않고 받은 메일을 메일서버가 즉시 중계하도록 하고 싶다. 어떻게 하면 될까? sendmail 관련 책이나 인터넷에 있는 여러 설명서보다는 웹민의 sendmail 설정을 들여다 보는 것이 훨씬 빠를 것이다. 7. 기업 환경을 위한 리눅스 블랙박스 만들기[7] 7.1 20만통의 메일과 sendmail 이번달에는 webmin등을 이용한 서버 설정에서 잠시 벗어나 본격적인 서버 설정에 대해서 알아보자. 아무리 기업환경을 대상으로 한다고 해도 리눅스에 대한 개념을 갖추지 못한 사용자만이 있는 것은 아니며 유닉스에 익숙한 관리자들도 많을 것인데 이들은 유닉스에 익숙하고 리눅스를 유닉스 중의 하나로 보고 일반적인 관리방법만을 적용하고 있다. 왜냐하면 현재 인터넷등에서 리눅스에 대한 글은 초보와 중급 정도의 독자를 대상으로 하고 있으며 대부분의 글이 처음 설치와 제대로 동작하기 정도에서 멈추기 때문이다. 여기저기 흩어져 있는 설정 방법들을 모두 섭렵하기에는 관리자들이 시간이 없으며 그런 문제를 전문적으로 해결해 줄 곳도 없기 때문이다. 또한 아무리 오픈소스가 인기가 있고 리눅스 열풍이 한반도를 휘몰아쳐도 여전히 나는 남의 정보를 얻어 오지만 내 것은 줄 수 없다는 생각이 지배적이기 때문이다. 필자는 여기 저기서 특별한 개발이 진행되고 있다는 소식을 주워 듣고는 있는데 제품화가 진행되고 있다는 소리는 있지만 이 것을 공개하고 있다는 이야기는 듣지 못하고 있다. 아무리 리눅스가 바람을 타더라도 이런 상황에서는 아무도 도약할 수 없다. 리눅스 마케팅의 대상은 한국이 아니라 전세계 시장이며 이런 마케팅은 정보의 공개에 의해서 그 힘을 얻을 수 있다. 각자 알고 있는 것을 일단 공개하자. 얻은 만큼 주어야 클 수 있고 보답이 돌아온다는 것을 명심해야 하지 않을까? 이 글은 필자가 대규모 메일 중계 서버를 관리하면서 알게된 경험을 바탕으로 쓴 글이다. webmin으로 하는 서버 설정을 기대하고 이 글을 읽는 독자들에게는 다소 어려운 글이겠지만 나중에는 결국 도움을 줄 수 있는 글이 될 것이다. 한 개의 서비스가 대규모화 되고 소위 엔터프라이즈급의 처리가 가능하기 위해서는 소규모일 때에는 전혀 문제가 되지 않던 것들이 엄청난 문제를 일으키게 된다. 리눅스가 대규모 서버로서 제대로 설 수 있기 위해서는 어떤 것들을 고려해야 하는지에 대해 알아보자. 이 글에서는 메일서버에 대해서만 언급하고 있지만 꼭 그 것에만 국한 된 것은 아니며 웹서버나 삼바등에서도 활용가능하다. 7.2 숙제풀이 지난 달에 sendmail이 가능하면 처리할 메일을 즉시 보내기를 하도록 하는 방법에 대해 물었다. 그 방법은 다양한데 가장 빠른 방법은 실제로 과중한 부담을 받는 메일서버를 관리하면서 고쳐 나가보는 것이다. 숙제의 답은 본문 속에서 찾아 볼 수 있다. 리눅스에서 하루에 20만통의 메일을 전송, 수신, 중계를 해야할 때 생길 수 있는 문제에 대해서 생각하다보면 이 정도의 문제는 쉽게 답을 낼 수 있을 것이다. 7.3 이글의 범위 이 글은 sendmail을 인스톨하고 설정하는 법에 대한 설명이 아니다. 기본적인 설정에 대해서는 언급하지 않는다. 네임서버 설정과 MX 레코드등에 대해서도 언급하지 않는다. 사용자명 재지정을 위한 alias, 수신 메일의 도메인을 처리할 것인가 여부를 결정하는 sendmail.cw, 수신 메일의 도메인과 사용자명을 바꿔치기하는 virtusertable, 변경전의 도메인을 새 도메인과 일치시키는 domaintable, 송신메일에서 사용자와 도메인명을 바꿔치기하는 genericstable, 상태편 사이트의 메일서버 문제를 처리하는 mailertable, 메일을 처리해 주는데 문제가 없는 사이트로 인정하는 sendmail.ct 등에 대해서 구체적으로 언급하지 않는다. 독자적인 sendmail.cf를 만들기 위해서 필요한 m4 프로그램 사용법도 마찬가지이다. 알고 싶으면 /usr/lib/sendmail-cf를 조사해 보기 바란다. 배포본의 설정은 /usr/lib/sendmail-cf/cf/redhat.mc에 들어 있다. m4 사용법은 이 글의 주제가 아니며 자세한 관련 문서가 같은 디렉토리에 있고 인터넷을 통하면 쉽게 한글문서도 구할 수 있다. 이 글에서 언급하는 대부분의 프로그램에 대한 사용법은 알고 있어야 한다. 모른다면 프로그램 예가 나올 때 마다 메뉴얼 페이지를 조사할 것을 권한다. sendmail 자체에 대해서 잘 모르는 사용자들이나 하루에 100개 미만의 메일을 처리하는 서버를 다룬다면 이 글을 읽지 않아도 좋다. 일반적인 sendmail의 옵션을 알고 싶으면 소스에 함께 배포되는 설명파일을 읽던지 인터넷을 뒤지던지 관련 서적을 구입할 것을 권한다. 시스템 설정 과정에 대한 사항도 자세히 설명하지 않는다. 이 글의 목적은 엔터프라이즈급 환경에서 리눅스를 운용할 때, 특히 메일서버로 사용할 때 제기될 수 있는 문제에 대해서 쓰는 글이며 메일서버 설정법에 대한 초보적이고 지루한 강의가 아니기 때문이다. 7.4 필요한 것들 리눅스를 메일서버로 사용하기 위해서는 sendmail 패키지가 필요하다. 물론 대부분의 배포본에는 기본적으로 메일서버가 인스톨되도록 만들어져 있다. 대규모 사이트가 아니라면 기본적인 설정으로 문제가 없다. 대규모 사이트에서 메일분산을 위해서는 sendmail 소스 배포본의 프로그램이 필요하므로 소스도 가져오기 바란다. 자체 네임서버도 필요하다. 배포본의 캐싱만 하는 네임서버를 인스톨해 둘 것. 그외 syslogd와 logrotate, top, killall 프로그램 사용법에 대한 지식도 필요하다. 하드웨어는 하루 전송량 1000통이하라면 팬티엄200, 메모리 64메가정도, 그 이상이라면 팬티엄II-450, 메모리 128혹은 256이상이 필요하다. 서버라면 스카시 하드 디스크를 사용하고 있을 것이다. IDE도 상관없지만 속도가 문제라면 스카시 하드 디스크가 적당할 것이다. 네트웍은 가능한한 빠른 것이 좋으며 트래픽을 감시하면서 메일서버의 처리량이 한계를 넘어가면 네트웍 속도를 업그레이드 하던지 속도에 맞게 메일서버의 처리량을 조절하면 될 것이다. 7.5 1천통의 이메일 하루에 1천통 이하의 메일을 처리하는 사이트가 있다. 사용자들은 윈도우에서 메일을 전송하고 리눅스의 계정으로 메일을 받는다. 사용자는 1-200명 정도이고 각 사용자는 10개 정도의 메일을 주고 받는다. 보내는 메일은 리눅스서버가 중계해 주고 받는 메일은 사용자들이 5분 단위로 pop3나 IMAP으로 가져 간다. 이 정도의 부담이라면 기본 배포본의 설정과 팬티엄 정도의 하드웨어 56K-128K정도의 네트웍 속도에서도 부담이 없다. 한 사람당 메일 쿼타로 5M를 준다면 1G 정도의 하드 디스크 여유가 있으면 된다. 파일서버, 프린터서버, 웹서버로 같이 사용해도 된다. 자체 네임서버를 구축할 필요도 없으며 메일 큐 디렉토리의 크기에도 신경 쓸 필요가 없다. 로그파일도 크지 않을 것이다. 90퍼센트 이상의 사이트에서 이 정도의 부담으로 리눅스를 사용하고 있는데 시스템 관리자도 거의 필요 없고 서버를 구석에 놓고 그냥 쓰면 된다. 정전이 되었거나 무심코 리셋키를 눌러서 하드디스크에 문제가 생기지 않는다면 일년이상 신경쓰지 않아도 된다. sendmail의 기동은 /etc/rc.d/init.d/sendmail에 의해서 시작된다. 중요부분은 다음과 같을 것이다. start) # Start daemons. echo -n "Starting sendmail: " daemon /usr/sbin/sendmail -bd -q1h echo touch /var/lock/subsys/sendmail sendmail은 데몬 모드(-bd)로 큐는 한 시간에 한 번씩 뒤져 보게(-q1h) 되어 있다. sendmail은 메일 접속을 받으면 자식 프로세스를 생성하여 처리하며 1시간에 한 번씩, 전송이 되지 않은 메일을 다시 보내기를 시도한다. 1천통의 메일은 이 방식으로 별 문제 없이 처리가 될 것이다. 이런 시스템 관리자는 복잡한 sendmail에 대해서 신경 쓰지 말고 다른 작업에 시간을 투자하기를 권한다. 7.6 1만통의 이메일 1만통의 메일은 사용자가 500명 정도, 1-2개의 메일링 리스트, 그리고 중계해 주어야 할 윈도우 클라이언트가 50-100대 정도 있게 된다. 한 개의 도메인 전체에 대한 메일을 담당하는 메일서버로 사용하는 경우일 것이다. 기본 설정으로 사용하기에는 몇가지의 문제가 발생한다. 500명의 사용자가 5분에 한 번씩 pop3을 사용하고 큐에는 평균 100통 이상의 메일이 저장되어 있게 된다. 가장 문제가 되는 것은 한 개의 데몬이 주고 받는 메일을 처리하기에는 힘들게 된다. 이제 데몬을 구분하도록 하자. 중계와 수신을 위해서, 그리고 큐에 쌓여 있는 메일을 처리할 두 개의 데몬으로 나눈다. daemon /usr/sbin/sendmail -bd /usr/sbin/sendmail -q30m 수신,전송을 위한 데몬은 몇가지 제한 사항에 따라 메일을 직접 전송할 것인지 큐에 쌓아 놓고 나중에 보낼 것인지 결정한다. 해당 옵션은 /etc/sendmail.cf에 있는데 다음과 같은 것이다. # load average at which we just queue messages #O QueueLA=8
# load average at which we refuse connections #O RefuseLA=12
# maximum number of children we allow at one time #O MaxDaemonChildren=12 LA란 Load Average라는 뜻인데 오렐리의 sendmail 책에 보면 복잡한 식으로 설명되어 있지만 경험적으로는 동시에 처리하고 있는 메일 프로세스의 수와 일치하는 것으로 보인다. QueueLA=8이란 현재 처리하고 있는 메일 프로세스의 수가 8개 이상이면 전송을 중단하고 일단 큐에 쌓은 다음에 나중에 처리하라는 뜻이다. 또한 RefuseLA=12란 메일 처리 프로세스 수가 12개 이상이면 접속을 거부하라는 의미가 된다. 마찬가지로 MaxDaemonChildren=12란 한개의 sendmail 데몬이 만들어 낼 수 있는 자식 프로세스의 수를 12개로 제한한다는 뜻이다. 이제 이 값을 바꾸어 준다. 큐에 메일을 쌓지 않고, 네임서버에 의뢰한 결과 보낼 주소가 유효한 것이고 상대편 메일서버가 전송을 허가해 준 메일이라면 즉시 전송을 시도하도록 한다. 그리고 가능한한 지연 없이 메일을 받아 들이고 원하는 모든 접속을 수용할 수 있도록, 접속 거부를 시작할 프로세스 수와 자식 프로세스의 최대값을 큰 값으로 유지한다. O QueueLA=128 O RefuseLA=128 O MaxDaemonChildren=64 첫칸에 #가 붙은 것은 sendmail에 설정되지 않으므로 변경하고 싶으면 #를 제거하고 값을 바꾸어 준다. 이제 sendmail은 동시에 128개(수신, 중계 sendmail 64, 큐처리 64)까지 뜰 수 있다. 수신메일은 최대 64개 까지 동시에 처리되며 중계나 수신은 64개 까지는 거부없이 받아 들인다. 물론 메일 거부는 부하가 많이 걸릴 때 발생하며 상대편 메일서버는 이 때에 메일 전송에 실패하지만 잠시 후에는 접속이 가능하게 되기 때문에 일시적 메일 서버 접속 거부는 아무런 문제가 없다. 잘못된 주소로 메일을 보내거나 이 메일 서버가 전송을 시도하는 상대편 메일서버가 다운되어 메일을 보낼 수 없을 때만 메일이 큐에 쌓인다. 큐에 쌓인 메일은 큐처리 전용의 메일서버가 계속해서 전송을 시도하게 되며 정말로 갈 수 없는 메일이 아니라면 몇 시간 안에 메일은 보내지게 될 것이다. 한 개의 메일이 계속 전송이 불가능 할 때 최대로 큐에 저장될 수 있는 값은 5일이다. 그 후에는 큐처리 메일서버가 이 메일을 강제로 삭제하게 된다. 이 값은 sendmail.cf에 있으며 바꾸기를 원하면 직접 찾아 보기 바란다. 7.7 5만통의 이메일 5만통의 메일을 주고 받게 되면 sendmail이 아닌 다른 부분에서 문제가 발생한다. 우선 수신, 중계 전용의 sendmail이 serial하다는 것이 문제가 된다. sendmail은 메일을 수신하면 이 메일이 로칼에 있는 사용자에게 오는 메일인지 중계를 해야 하는 것인지 판단해야 한다. 중계를 해야 하는 것이라면 네임서버에게 헤더에 적힌 메일 주소값을 보내 실제 숫자 IP 주소로 바꾸어 줄 것을 요청한다. 그 동안 이 프로세스는 다른 메일은 받아들이지 않는다. 또다른 메일을 받아들이기 위해서는 자식 프로세스가 fork되어야 하고 64개의 메일 프로세스는 각각 네임서버에게 주소값을 의뢰하는 시간 지연이 있다. 네임서버가 신속히 반응하지 않으면 그 프로세스는 최대 5분까지 1개의 메일 때문에 대기해야 한다. 그 동안 계속 메일이 전송되면 네임서버의 지연으로 대기하는 프로세스는 제외한 프로세스들이 처리해야 하므로 여러개의 프로세스가 네임서버 지연으로 묶이게 되면 금방 64개의 자식 프로세스가 생성되고 그 이상 생성될 수 없으므로 나머지 전송 메일은 전송 시도조차 할수 없게 된다. 즉 1분에 70개의 메일이 전송되고 그 중에서 5개의 메일이 네임서버 지연으로 묶여 있게 될 때는 그 중에서 59개만 처리되고 대기 메일이 5개, 나머지 6개는 전송 실패를 하게 된다. 상대편 메일 서버는 일정시간이 지나야 메일을 재전송하게 되기 때문에 전송지연이 생기게 된다. 물론 메일을 도착 즉시 읽어야 하는 것은 아니지만 이런 지연으로 인해 중요한 업무를 처리할 수 없게 되면 심각한 일이 아닐 수 없다. 또한 중계를 요청한 메일 주소가 잘못되어 있을 경우에는 5분의 지연이 있게 된다. 그래서 평균적으로 목적지 주소가 잘못된 중계메일이 30%정도의 메일서버 수행 성능 손실을 가져올 수 있다. 서버를 빠른 하드웨어로 대체해도 이 문제는 해결되지 않는다. 정상적으로 전송될 수 있는 메일은 1M 네트웍 환경에서, 크기가 10k 이내라면 3초 안에 네임서버 조회, 상대편 서버와 접속, 사용자 인증, 메일 본문 전송의 모든 작업이 끝나게 된다. 100개의 메일을 300초 동안에 모두 전송 할 수 있음을 뜻한다. 좀 더 빠른 하드웨어와 네트웍에서 같은 메일을 2초 만에 전송할 수 있다면 200초가 걸린다. 그러나 그 중에서 1개의 메일이 잘못되었다면 이 메일이 5분(300초)간의 전송 지연을 유발하게 되고 총 걸린 시간은 600(300+300)분과 500(200+300)분의 차이가 된다. 9개의 정상 메일과 1개의 비정상 메일에 대해서 이야기 했지만 1000개의 메일에서 20개의 메일이 이상하다면 총 걸린 시간은 거의 차이가 나지 않는다(11960초와 12940초). 이 문제를 해결하고자 단순히 빠른 서버를 구입한다고 했을 때 하드웨어 업그레이드에 비해서 전송효율이 같은 비율로 올라가는 것은 아니다. 이 것은 마치 99미터를 1초만에 달리고 나머지 1미터를 10초에 달리는 선수와, 99미터를 2초에 달리고 나머지를 같은 10초에 달리는 100M 경주와 비슷하다. 평균적으로 빠르지 않으면 결과는 차이가 거의 없는 것이다. serial 방식의 메일 전송의 병목은 시스템의 수행 성능이 아니라 잘못된 메일이 점유하는 프로세싱 타임에 있다. 5만통의 메일을 처리하기 위해서는 이런 serial 문제를 해결해야 한다. 수신, 중계 메일은 메일을 받아들이는 순간에는 네임서버에 유효한 주소인지 의뢰하는 등의 지연을 가져올 수 있는 모든 행위를 하지 않도록 하고 무조건 메일을 큐에 쌓도록 하는 것이다. 큐에 쌓인 메일은 큐 처리 전용의 메일서버가 병렬적으로 메일을 전송할 수 있도록 만든다. /usr/sbin/sendmail -bd -ODeliveryMode=defer /usr/sbin/sendmail -q1m -OMaxDaemonChildren=64 DeliveryMode는 4가지가 있다. 각각은 sendmail 책에 있으므로 관심있는 사용자는 찾아 보기 바란다. 그 중에서 defer 모드는 수신 메일을 그 즉시 직접 전송을 하지도 않을 뿐 아니라 받은 메일이 유효한 것인지 네임서버에 의뢰하는 등의 시간지연이 있을 수 있는 행위를 전혀 하지 않고 큐에 쌓기만 한다. -q1m란 큐처리 데몬은 1분 단위로 자식 프로세스를 만들고 이 프로세스가 처리할 메일이 있는지 확인하게 하는 것이다. 메일이 큐에 없을 때는 자식 프로세스가 뜬 후에 처리할 메일이 없음을 확인하고 스스로 죽게 된다. 만약 메일이 많이 수신되어 큐에 메일이 쌓이기 시작하면 1분에 한 번씩 큐 전용 메일서버가 자식 프로세스를 만들어 내고 이 들은 각자 메일 전송을 시작한다. 64개의 메일 프로세스가 뜨기까지는 64분이 걸리는데 처음 뜬 프로세스가 1분에 2개의 메일을 처리한다고 하면 평균적으로 64분 동안 64개의 프로세스가 각각 64개의 메일을 처리하는 것이다. 즉 수신 메일이 분당 32개의 메일을 큐에 쌓는 정도의 부하(하루 총 메일량 46080개)에서는 평균적으로 큐처리 메일이 32개 정도가 뜨게 된다. 수신 전용의 데몬은 평균 10개 이내로 떠있게 되는데 그 이유는 한 개의 메일을 단순히 큐에 쌓는 행위는 거의 시간이 걸리지 않기 때문에 뜨는 즉시 메일을 처리하고 죽게 되기 때문이다. 그러나 이런 수치상의 결론이 실제와는 일치하지 않는데 그 이유는 전송될 수 없는 메일이 큐에 쌓이게 되면서 전체적인 성능을 떨어뜨리기 때문이다. 64분 동안 주소가 잘못된 1개의 메일은 각각의 프로세스가 1번씩 전송을 시도하므로 총 64번 시도된다. 전송될 수 없는 메일은 한 개의 프로세스를 5분동안 잡아 놓고 있으므로 10개의 메일이 전송될 수 없도록 하는 효과가 있고 64개의 프로세스에 대해서는 640개의 메일을 보낼 수 없도록 하는 것이다. 하루 동안 계산하면 총 15000여통의 메일을 보내지 못하게 만드는 결과를 낳는다. 한 개의 메일은 5일 동안 살아 있으므로 이런 메일이 다른 방식으로 처리되지 않는다면 메일서버는 엄청난 비효율에 시달려야 한다. 나중에는 큐에는 거의 이런 악성 메일로만 가득차 있고 정작 바로 보낼 수 있는 메일이 이들 속에 묻혀 전송이 되지 못하고 그대로 쌓이는 것을 보게 될 것이다. sendmail의 소스 배포본의 contrib 디렉토리에는 이 문제를 해결하는데 도움을 주는 프로그램 re-mqueue.pl이 있다. 이 프로그램은 perl로 만들어져 있으며 어떻게 사용하는지는 그 프로그램 안에 자세한 설명이 있다. perl과 관련한 사항은 설명하지 않는다. 소스를 보고 어떻게 활용할 것인지는 스스로 판단하기 바란다. 큐에 쌓이는 메일은 방금 받은 메일과 1시간 전에 받았지만 아직 처리 되지 못한 메일, 그리고 여러 시간 혹은 며칠 전에 받았지만 전송할 수 없는 메일들이 함께 들어 있다. 우선 1-2시간 안에 모든 메일은 큐 처리 데몬이 한 번씩 전송을 시도하기 때문에 1-2시간 전에 받았지만 아직 한 번도 전송이 시도된 적이 없는 메일은 없다고 가정한다. 그러므로 cron을 돌려서 2시간(64개의 데몬이 각각의 메일 전송을 2번 시도한 시간)안에 처리되지 못한 메일은 일차 큐에서 분리하여 다른 큐에 보내고 이 이차큐에 있는 메일을 처리하는 sendmail 데몬을 돌려서 그 메일들을 전송 하도록 한다. 우선 데몬을 다른 방식으로 띄운다. /usr/sbin/sendmail -bd -ODeliveryMode=defer
/usr/sbin/sendmail -q1m -OMaxDaemonChildren=64 \ -OQueueDirectory=/var/spool/mqueue
/usr/sbin/sendmail -q10m -OMaxDaemonChildren=32 \ -OQueueDirectory=/var/spool/mqueue2 /var/spool/mqueue2를 만들고 여기에는 2시간이 지난 메일을 처리하는 데몬을 최대 32개 까지 띄울 수 있도록 한다. 전송 지연이 있는 메일은 문제가 있는 것이므로 새로운 프로세스는 10분 정도의 시간 간격으로 뜨게 하면 별로 시스템 부담이 없게 될 것이다. 이제 mqueue의 일차 큐에서 mqueue2의 이차 큐로 메일을 보내는 것은 crontab을 사용해서 처리한다. # crontab -e
1-59/10 * * * * /usr/sbin/re-mqueue.pl /var/spool/mqueue /var/spool/mqueue2 7200 10분 단위로 mqueue에서 mqueue2로 2시간(7200초)가 지난 메일을 이동시킨다. 이제 일차 큐에는 전송 중이거나 전송을 기다리는 메일들만 남게 되고 악성메일(현재 보낼 수 없는 메일)은 제거되므로 효율이 눈에 띄게 증가하게 된다. redhat-5.2 이상의 설정이 이와 유사하지만 큐디렉토리간의 파일 이동을 위한 프로그램 설정이 되지 않았다. reahat-5.2 이상을 인스톨 했다면 re-mqueue.pl을 사용해 볼 것을 권한다. 7.8 10만통의 이메일 10만통의 메일을 하루에 처리하는 서버는 거의 엔터프라이즈급이라고 볼 수 있다. 하드웨어는 펜티엄II-dual, 메모리는 256M이상이 필요하고 네트웍은 1M급이 되어야 할 것이다. 리눅스의 사용자 계정은 현재 65536명까지 가능하지만 userid를 공유하는 서로 다른 사용자명을 사용할 수 있다. 또한 쉽게 사용자를 추가하고 제거하는 방법이 고려되어야 하고 사용자 인증 자체도 한 번의 메일을 위해서 64K를 뒤지는 비효율적인 방법이 아닌 다른 방법이 사용되어야 한다. 그러나 이 것은 이 글의 주제가 아니다. 10만통의 메일을 주고 받는 서버는 B급 도메인의 메일서버가 될 것인데 이 글에서는 계정 사용자보다는 주로 하위 클라이언트의 메일 중계를 중심으로 설명한다. 10만통의 메일을 처리하는 서버는 또다른 문제에 직면하게 된다. sendmail은 메일을 전송하면서 그 결과 메세지를 syslogd를 통해서 /var/log/maillog에 저장한다. /var/log/maillog에는 pop3를 사용하여 클라이언트가 메일을 가져가는 기록과 한 개의 메일이 전송될 때마다의 기록을 남긴다. maillog는 cron 이 작동하여 한 주마다 크기를 줄이게 되어 있다(/etc/logrotate.conf참조). 그 크기를 계산해 보자. 아래는 성공적으로 메일 중계가 이루어진 한 개의 메일에 대한 로그이다.
Apr xx xx:xx:xx mail sendmail[24543]: XAA24543: from=<xxx@xxx.com>, \ size=2909, class=0, pri=32909, nrcpts=1, \ msgid=<45672:phj650:99xxxx_23:45:57>, proto=SMTP, relay=[210.108.5.10]
Apr xx xx:xx:xx mail sendmail[24543]: XAA24543: to=<xxxxx@xxxmail.net>, \ delay=00:00:00, mailer=esmtp, stat=queued
Apr xx xx:xx:xx mail sendmail[26062]: XAA24543: to=<xxxxx@xxxmail.net>, \ claddr=<xxxxxxx@xxxinc.com> (504/504), delay=00:09:27, xdelay=00:00:01,\ mailer=esmtp, relay=r-xxxxx.xxxmail.net. [xxx.xxx.152.76], \ stat=Sent (AAA06884 Message accepted for delivery)
한 개의 정상적인 메일이 전송될 때 나오는 메세지는 560여 바이트가 된다. 이 것은 정상적으로 전송된 메일의 경우에만 그렇고 여러가지 이유에 의해서 전송되지 않는 메일은 하루에 여러번 전송 시도를 하기 때문에 여기에 더해서 그 때마다 에라 메세지가 쌓인다. 그러므로 평균적으로 한 개의 메일이 1k정도의 메세지를 뿌린다고 하자. 하루에 10만개의 메일을 전송하니까 로그는 100M가 된다. 일주일 동안 로그 파일의 크기는 700M로 커진다. 메일계정이 1000명이라고 할 때 각각의 사용자가 5분마다 한 번씩 메일을 체크한다. 한 번의 메일 체크 로그는 아래와 같다.
Apr xx xx:xx:15 mail ipop3d[22650]: port 110 service init from 210.xxx.x.x Apr xx xx:xx:18 mail ipop3d[22650]: Login user=xxxxx host=[210.xxx.x.xx] nmsgs=7/7 Apr xx xx:xx:24 mail ipop3d[22650]: Logout user=xxxxx host=[210.xxx.x.xx] nmsgs=0 ndele=7
한 번에 약 0.2k의 로그가 쌓인다. 윈도우에서 pop3을 사용해 메일을 가져가고 근무 시간 이후에는 컴퓨터를 끈다고 가정하면 하루에 8시간 근무하는 사용자는 192K의 로그를 만들어 내고, 1000명은 192M를, 일주일에는 1.3G의 로그를 생성시킨다. 메일 서버에 하드 디스크가 넉넉하다면 로그 파일의 크기가 커지더라도 하드 디스크 용량 때문에 문제가 생기지는 않을 것이다. 한 사용자당 5M씩 할당하면 메일을 저장할 영역으로 5G가 필요하고 로그를 위해서 2G이상이 필요하다(logrotate값이 4라면 8G.) 문제는 여기에 있지 않다. syslogd는 한 개의 파일, maillog를 열어 놓고 계속해서 로그 메세지를 쌓게 되는데 이 때 1M이상을 넘어가면 1개의 로그 메세지를 처리하기 위해서 시스템 자원을 10 퍼센트 이상 사용하며, 10M를 넘어가면 40 퍼센트 이상, 100M 메가를 넘어가면 거의 80퍼센트 이상의 시스템 자원을 사용하게 된다. 로그 파일이 커질 수록 점점 시스템 자원이 고갈 되어서 나중에는 메일 전송 보다는 로그 쓰기 작업에 모든 프로세싱 타임을 사용해야 한다. 아래의 예는 /usr 파일을 백업하기 위해 사용한 tar에서 부르는 gzip이 시스템 자원을 79.4 퍼센트를 사용하고 있음을 보여주는 예이다.
x:xxxx up 1 day, 2:05, 2 users, load average: 0.22, 0.05, 0.02 49 processes: 46 sleeping, 3 running, 0 zombie, 0 stopped CPU states: 78.6% user, 5.7% system, 0.0% nice, 15.8% idle Mem: 192896K av, 189948K used, 2948K free, 283288K shrd, 12496K buff Swap: 104416K av, 0K used, 104416K free 133384K cached
PID USER PRI NI SIZE RSS SHARE STAT LIB %CPU %MEM TIME COMMAND 4688 root 11 0 580 580 232 S 0 79.4 0.3 0:06 gzip 4687 root 4 0 532 532 432 R 0 3.9 0.2 0:00 tar 4689 root 2 0 708 708 548 R 0 0.9 0.3 0:00 top
지금 여러분의 시스템에서 top 명령을 사용해 보기 바란다. 시스템 자원을 10퍼센트 이상 사용하고 있는 프로세스가 있다면 필시 하드 디스크를 접근하고 있는 프로그램일 것이다. 컴퓨터에서 하드 디스크를 빈번하게 사용하는 작업이 여러개 떠 있다면 성능은 급격하게 하락하게 된다. 메일서버 뿐만 아니라 웹서버와 같은 데몬들의 성능이 느려 졌다면 필시 이런 문제가 개입되어 있을 확률이 높다. 배포본에 있는 로그 파일 처리는 하루에 10만개의 메일을 처리하기에는 역부족이다. 좀 더 효율적인 처리를 생각해 보자. 우선 아래 파일을 만든다. /etc/logrotate.mail
daily size 100k rotate 2 errors root create
/var/log/maillog { postrotate /usr/bin/killall -HUP syslogd endscript }
/var/log/messages { postrotate /usr/bin/killall -HUP syslogd endscript } maillog, messages 외에 /var/log에 있는 파일 중에서 시간 별로 그 크기가 1M 이상씩 증가하는 것이 있다면 여기에 첨가한다. 로그 파일은 가능한한 작게 유지하는 것이 좋다. 위에서 로그 파일의 크기가 100k 이상이 되면 무조건 작게 만들도록 설정을 했다. 로그를 줄일 때 이전 로그는 log.1이 되고 log.1은 log.2가 된다. 여기서 rotate를 2로 만들었기 때문에 log.2는 삭제되고 log.1은 log.2가 되며 log는 log.1이 되고 새 파일 log가 만들어져 syslogd가 여기에 쓰기를 한다. cron 작업은 다음과 같이 설정한다. #crontab -e
1-59/10 * * * * /usr/sbin/logrotate /etc/logrotate.mail 10분 마다 로그를 점검하여 그 크기를 줄인다. 이렇게 10분마다 로그처리를 위해 프로세싱 타임을 소모하더라도, 로그의 크기를 줄여서 얻는 효과가 더 크기 때문에 빈번한 로그 처리 작업에 드는 프로세싱 타임을 상쇄하고 남는다. 여러분의 웹서버가 오래 켜 놓으면 시간이 지날 수록 점점 느려지는 이상한 증상은 없는가? 이런 증상 때문에 메모리를 늘이거나 대용량의 하드웨어를 구입할 계획을 세우고 있었다면 /var/log/httpd 디렉토리를 점검해 보기를 바란다. access_log가 10M 이상은 아닌가? 10만통의 메일을 처리하는 서버에는 일차큐에 시간당 5천통의 메일이 쌓인다. 이제 64개의 메일 프로세스로는 감당을 할 수 없다. 한개의 메일은 2시간 동안 큐에 대기하게 되는데 2시간 동안 1만통의 메일이 쌓이게 되므로 그 동안에 각각의 메일을 처리 할 수 있을 확률이 낮아 진다. 이렇게 64개의 큐처리 메일 서버가 동작하면서 두시간 안에 모든 메일을 한 번씩이라도 전송 시도 하기가 어려워지는 상황에서 더욱 상황을 나쁘게 만드는 것은 5퍼센트(500개)악성메일이 프로세싱 타임을 늘게 만드는 것이다. 이 문제를 해결하기 위해서 다음과 같은 방법을 사용할 수 있다. 즉 최대 자식 프로세스 숫자를 높이고 각각 다른 제한을 가진 프로세스를 띄운다. /usr/sbin/sendmail -bd -ODeliveryMode=defer
/usr/sbin/sendmail -q10s -OQueueDirectory=/var/spool/mqueue \ -OMaxDaemonChildren=96 \ -OTimeout.initial=1m -OTimeout.connect=1m \ -OTimeout.iconnect=1m -OTimeout.helo=1m \ -OTimeout.mail=1m
/usr/sbin/sendmail -q1m -OQueueDirectory=/var/spool/mqueue \ -OMaxDaemonChildren=16
/usr/sbin/sendmail -q10s -OQueueDirectory=/var/spool/mqueue2 \ -OMaxDaemonChildren=32 mqueue2에는 2시간 안에 처리되지 못한 메일이 있으므로 악성메일이라고 판단하여 프로세스 수를 늘이지 않았다. 일차큐인 mqueue에는 두개의 각기 다른 데몬이 떠 있는데 첫번째 것은 96개까지 자식 프로세스를 만들어 낼 수 있고 두 번째 것은 16개 까지 만들어 낼 수 있다. 시스템에 생길 수 있는 총 메일서버 프로세스의 갯수는 수신 중계 전용(64+1), 일차큐(96+1, 16+1), 이차큐(32+1)로 212개이다. 이 때 쯤이면 각 경우에 맞추어 /etc/sendmail.cf의 변수를 조절해야 한다는 것은 스스로 알게 될 것이다. 지금은 아래와 같이 하면 된다. O QueueLA=256 O RefuseLA=256 O MaxDaemonChildren=64 mqueue에 실행되는 두 개의 각기 다른 큐전용 메일 프로세스의 차이는 무엇일까? 우선 한 개는 네임서버 그리고 상대편 메일서버와 교신하는 시간제한을 모두 1분으로 정하고 실행하도록 했다. RFC1123에 의하면 각각의 시간제한은 5분으로 설정하도록 되어 있지만 정상적인 메일은 거의 1분이 되기 전에 상대편과 교신하고 메일 본문 전송에 들어가게 되므로 초기 교신 과정에서 1분 이상의 시간 지연이 있으면 느린 네트웍에 있는 메일서버라고 판단하거나 상대편이 전송 불능 상태라고 간주하여 메일 전송을 중단하고 신속히 다음 메일을 처리하도록 한다. 이 프로세스는 10초 마다 한 개씩 자식을 만들게 되므로 메일이 쏟아져 들어오기 시작한 지 960초(16분)이 지나면 96개의 자식 프로세스가 전송이 되든 안되든 1분 안에 1개의 메일을 처리할 수 있으므로 한 시간에 들어오는 5000개의 메일과 거의 비슷한 양의 메일을 처리 할 수 있게 된다. 즉 각각의 메일을 큐에 쌓은 후에 반드시 한 번 이상의 전송 시도를 할 수 있다는 것이다. 악성 메일이 아니지만 상대편 메일서버의 속도가 느려서 1분 이상의 지연 후에 메일이 갈 수 있음에도 전송을 중단당한 메일이 쌓일 수 있는 문제가 있다. 이런 부적절한 처리를 해결하기 위해서 정상 대기 시간을 가진 16개의 메일 프로세스가 1분 대기 프로세스가 남겨둔 메일을 다시 전송 시도 하도록 하면 된다. 그 때문에 한 개의 큐 디렉토리를 대상으로 하는 두 개의 데몬을 띄운 것이다. 두 시간 동안 모든 메일은 최소한 한 번의 전송 시도를 할 수 있게 되며 그럼에도 전송되지 못하고 남겨진 악성 메일은 2차 큐로 이동된다. 일차큐는 항상 효율적으로 사용할 수 있다. 7.9 20만통의 메일 20만통의 메일을 한 개의 큐 디렉토리에 받게 되었을 때 시간당 약 1만통의 메일이 쌓인다. 일차큐에 있는 메일은 2시간 후에 이차큐로 옮겨지기 때문에 2시간 동안 약 2만통의 메일이 쌓이게 되고 메일 전송 효율이 70 퍼센트라면 일정 시점에 큐에 쌓이는 파일의 수는 약 6000개이다. 한 개의 메일은 dfxxxxxx라는 메일 본문과 qfxxxxxx라는 헤더 부분이 각각의 파일로 존재하므로 12000개의 파일이 한 개의 디렉토리에 생성되고 전송 중임을 나타내는 xfxxxxxx라는 파일이 최대 112개가 생긴다. 한 디렉토리에 12112개의 파일이 있다면 그 중에서 한 개의 파일을 열기 위해서는 허용하기 힘든 시간을 소모해야 한다. 지금 한 디렉토리에 10000개의 파일을 만들고 ls 라고 실행해 보기 바란다. 아마 10초 이상의 시간을 기다려야 겨우 그 결과를 볼 수 있을 것이다. 이제 큐에 쌓인 메일 파일의 갯수가 병목이 된다. 한 시간에 1만통의 메일이 쌓인다면 10분에 평균 1700개의 메일 즉 3400개의 실제 파일을 한 디렉토리에 생성하는 것이다. 물론 생성되는 순간에 즉시 전송 되는 경우가 많겠지만 여전히 프로세싱 타임은 한계를 넘어 가게 된다. 이를 위해서는 6개의 큐디렉토리를 새로 만들고 매 10분 마다 각각의 디렉토리에 파일을 옮겨서 전송을 시도하는 것이 좋다. 다음과 같이 할 수 있을 것이다. /usr/sbin/sendmail -bd -ODeliveryMode=defer
# 일차큐 /usr/sbin/sendmail -q10s -OQueueDirectory=/var/spool/mqueue \ -OMaxDaemonChildren=32 \ -OTimeout.initial=1m -OTimeout.connect=1m \ -OTimeout.iconnect=1m -OTimeout.helo=1m \ -OTimeout.mail=1m
/usr/sbin/sendmail -q1m -OQueueDirectory=/var/spool/mqueue \ -OMaxDaemonChildren=4
# 이차 큐 1번 /usr/sbin/sendmail -q10s -OQueueDirectory=/var/spool/mqueue_1 \ -OMaxDaemonChildren=16 \ -OTimeout.initial=1m -OTimeout.connect=1m \ -OTimeout.iconnect=1m -OTimeout.helo=1m \ -OTimeout.mail=1m
/usr/sbin/sendmail -q1m -OQueueDirectory=/var/spool/mqueue_1 \ -OMaxDaemonChildren=4
# 이차 큐 2,3,4,5번 ....
# 이차 큐 6번 /usr/sbin/sendmail -q10s -OQueueDirectory=/var/spool/mqueue_6 \ -OMaxDaemonChildren=16 \ -OTimeout.initial=1m -OTimeout.connect=1m \ -OTimeout.iconnect=1m -OTimeout.helo=1m \ -OTimeout.mail=1m
/usr/sbin/sendmail -q1m -OQueueDirectory=/var/spool/mqueue_6 \ -OMaxDaemonChildren=4
# 3차 큐 : 2시간 지난 메일 처리 /usr/sbin/sendmail -q10s -OQueueDirectory=/var/spool/mqueue2 \ -OMaxDaemonChildren=32 cron은 다음과 같이 구성할 수 있다. # crontab -e
0 * * * * /usr/sbin/re-mqueue.pl /var/spool/mqueue /var/spool/mqueue_1 600 10 * * * * /usr/sbin/re-mqueue.pl /var/spool/mqueue /var/spool/mqueue_2 600 20 * * * * /usr/sbin/re-mqueue.pl /var/spool/mqueue /var/spool/mqueue_3 600 30 * * * * /usr/sbin/re-mqueue.pl /var/spool/mqueue /var/spool/mqueue_4 600 40 * * * * /usr/sbin/re-mqueue.pl /var/spool/mqueue /var/spool/mqueue_5 600 50 * * * * /usr/sbin/re-mqueue.pl /var/spool/mqueue /var/spool/mqueue_6 600
1-50/10 * * * * /usr/sbin/re-mqueue.pl /var/spool/mqueue_1 /var/spool/mqueue2 7200 1-50/10 * * * * /usr/sbin/re-mqueue.pl /var/spool/mqueue_2 /var/spool/mqueue2 7200 1-50/10 * * * * /usr/sbin/re-mqueue.pl /var/spool/mqueue_3 /var/spool/mqueue2 7200 1-50/10 * * * * /usr/sbin/re-mqueue.pl /var/spool/mqueue_4 /var/spool/mqueue2 7200 1-50/10 * * * * /usr/sbin/re-mqueue.pl /var/spool/mqueue_5 /var/spool/mqueue2 7200 1-50/10 * * * * /usr/sbin/re-mqueue.pl /var/spool/mqueue_6 /var/spool/mqueue2 7200 각 디렉토리는 최대한 3000개의 정도의 메일을 보유하게 된다. 일차큐에서는 한 개의 메일에 대해서 최대 10분 동안 전송을 시도한 후에 전송에 실패했거나 미처 처리하지 못하고 남은 것은 각각 10분 단위로 다른 큐로 보내진다. 옮겨진 각 큐에서 2시간을 시도해 본 후에 전송이 되지 않았으면 6개의 이차큐에 남은 메일은 모두 mqueue2로 보내진다. 여기서 2시간 지난 후의 소위 악성 메일에 대한 또다른 처리는 고려하지 않았다. 모든 큐 디렉토리의 부하를 줄이기 위해서는 re-mqueue.pl을 사용하여 2,4,8시간 1,2,3,4일 단위의 큐를 따로 생성하는 것이 좋을 것이다. 위와 같이 했을 때 최대로 뜰 수 있는 메일 서버 프로세스의 갯 수는 268개이다. 이제 시스템에서 처리할 수 있는 프로세스 갯수와 열 수 있는 오픈 파일의 갯수가 문제가 된다. 기본적으로 한 개의 sendmail 프로그램이 기동하면서 여는 파일은 다음과 같다. 0 -> /dev/null 1 -> /dev/null 2 -> /dev/null 3 -> /var/spool/mqueue/qfVAA14282 4 -> socket:[590] 5 -> /etc/mail/aliases.db 6 -> /etc/mail/access.db 7 -> /etc/mail/virtusertable.db 8 -> /etc/mail/domaintable.db 9 -> /etc/mail/genericstable.db 10 -> /etc/mail/mailertable.db 11 -> /var/spool/mqueue/xfVAA14282 12 -> /var/spool/mqueue/dfVAA14282 13 -> socket:[814754] 이 자료는 ps를 실행하고 현재 전송 중인 메일의 프로세스 번호(예를 들어 235번)에 따라 "ls -l /proc/235/fd" 라고 실행하면 볼 수 있다. 268개의 메일 프로세스가 각각 13개씩의 파일을 열면 모두 3484개의 파일이 열린다. 서버에는 메일 데몬만 떠 있는 것이 아니므로 실제로 열려 있게 되는 파일 수는 이 값을 훨씬 넘어 간다. 현재 리눅스에서 동시에 열 수 있는 파일의 디폴트값은 4096이다. 그 값은 아래의 파일에서 정의되어 있는데 이 것을 고치고 커널을 재컴파일 하면 변경 가능하다. /usr/src/linux/include/linux/fs.h
#define NR_FILE 4096 같은 헤더 파일에 한 개의 프로세스가 열 수 있는 파일의 최대값(NR_OPEN)이 1024로 정해져 있는데 이 값은 변경하지 않아도 좋다. 물론 원하면 변경해도 된다. 그 결과는 각자 테스트 해 볼 것. NR_FILE과 NR_OPEN을 크게하면 주기억장치가 크지 않은(64M이하) 시스템의 경우에는 부팅도 불가능하게 되니 주의 할 것. 커널 컴파일이 귀찮다면 동적으로 이 값을 변경해 줄 수도 있다. /proc/sys/fs/file-max가 그 것인데 아래 명령으로 현재의 최대값과 할당된 값을 볼 수 있다. # cat /proc/sys/fs/file-max 4096
# cat /proc/sys/fs/file-nr 1143 274 4096
# cat /proc/sys/fs/inode-max 12288
# cat /proc/sys/fs/inode-nr 8340 34 이들 값의 의미와 읽는 방법은 /usr/src/linux/Documentation/proc.txt를 참고할 것. 커널 컴파일 없이 시스템에서 열 수 있는 최대값을 변경하기 위해서는 다음 명령을 사용하면 된다. echo 8192 >/proc/sys/fs/file-max echo 24576 >/proc/sys/fs/inode-max inode-max값은 file-max값의 3배수 이상으로 하라고 proc.txt에서 조언하고 있다. 항상 이렇게 하고 싶으면 /etc/rc.d/rc.local에 적어 두면 될 것이다. 메일서버가 200개 이상 뜨거나 웹서버가 동시에 400개 이상 떠있어야 하는 대형 사이트에서는 최대값을 크게 하는 것이 최종적인 해결책일 수 있다. 그러나 이렇게 최대값을 크게 하여 문제를 해결하기 이전에 가능한 현 상태에서 최적화에 우선 신경을 쓰는 것이 더 좋은 방법이다. 왜냐하면 최대값 증가는 더많은 메모리를 요구하고 더 많은 자원 할당을 요구하기 때문이다. 200개 이상의 sendmail을 위해서 쓸 수 있는 최적화 방법으로는 한 개의 sendmail이 여는 파일의 갯수를 줄이는 것이다. 위에서 보듯이 virtusertable.db등은 가상 도메인을 사용하지 않으면 전혀 필요가 없다. 그러나 사용하지 않는 빈 파일인 /etc/mail/virtusertable을 그대로 둔다면 sendmail이 기동하면서 db파일을 만들게 되고 모든 프로세스가 이 파일을 열어 두게 된다. 그러므로 사용하지 않는 파일을 아예 없애버리면 sendmail이 db파일을 만들지 않고, 그에 따라 각 프로세스는 이 파일을 위해 파일 핸들을 할당하지 않으니까 열린 파일 갯수가 줄어든다. 한 개의 열린 파일의 갯수를 줄이면 268개의 파일을 닫는 효과가 있다. 사용하지 않는 domaintable, access, genericsable, mailertable 5개의 파일을 지워버리면 1340개의 열린 파일 수를 절약할 수 있으며 한 프로세스의 열린 파일 갯수가 적어지면 메일을 체크할 때 이 파일을 뒤지지 않아도 되기 때문에 그 만큼 프로세싱 타임이 줄어 들 것이다. 큐에 쌓인 메일을 처리하는 sendmail 프로세스는 메일을 보내기 위해서 네임서버와 교신해야 한다. 메일 서버가 서브네트웍 바깥에 있다면 한 개의 메일을 보내기 위해서 외부까지 교신을 해야 하기 때문에 시간이 많이 걸린다. 한 시간에 1만번의 조회를 시도하면 아마 외부 메일서버도 견디지 못하고 다운될 확률이 있다. 또한 네트웍 자원은 네임서버와의 교신에 모두 소모되고 다른 사람들이 외부로 나가거나 들어오는 것초차 힘들게 된다. 네임서버가 로컬 네트웍의 다른 서버에 있어도 마찬가지이다. 내부 네트웍은 거의 네임서버 접속에 이용되므로 회사 전산망이 마비되고 네임서비스를 하는 서버가 다운된다. 실제로 필자가 내부 네트웍의 다른 서버에 네임서버를 두고 메일서버가 네임 조회를 이 서버 쪽으로 하도록 했었는데 네임서버에 메모리가 고갈되어 named, httpd, cron등이 죽었다. 그 후에 데몬이 죽은 것을 알고 named와 httpd만 살리고 cron이 죽은 것은 알지 못하고 재실행하지 않았더니 cron으로 돌던 log파일 처리 프로그램이 동작하지 않아 로그 파일이 커지는 바람에 시스템이 움직이지 않을 정도로 부하가 걸린 적이 있었다. 필자는 외부에 의한 해킹으로 의심하고 보안관련 문서를 뒤적이느라고 시간을 소비해야 했다. 이렇게 한 개의 메일서버가 연속적으로 다른 서버들에게 영향을 미칠 수 있음을 염두에 두어야 할 것이다. 그러므로 가능하면 메일서버 자체에 메일 전송을 위한 네임서버를 띄우는 것이 좋다. 이 때의 네임서버는 단순한 캐싱만을 하는 네임서버만으로 족하다. 처음에는 네임서버 자체가 외부로 조회를 해야 하기 때문에 시간이 걸리겠지만 계속 사용한다면 중복되는 IP는 같은 메모리 안에서 처리가 가능하기 때문에 외부에 영향을 주지 않으며, 로컬 네트웍의 tcp/ip 자원도 소모시키지 않고 신속한 조회가 이루어 질 수 있다. 캐싱만 하는 네임서버는 간단히 다음과 같이 만들 수 있다.
/etc/named.conf
options { directory "/var/named"; check-names master warn; datasize 20M; }; zone "." IN { type hint; file "root.hint"; }; zone "localhost" IN { type master; file "localhost"; check-names fail; allow-update { none; }; allow-transfer { any; }; };
/var/named/root.hint
#dig >/var/named/root.hint
/var/named/localhost
@ IN SOA @ root ( 42 ; serial (d. adams) 3H ; refresh 15M ; retry 1W ; expiry 1D ) ; minimum NS @ 1 A 127.0.0.1
/etc/resolv.conf
nameserver 127.0.0.1
이렇게 최소한의 네임서버만으로 네트웍 자원의 낭비를 막을 수 있으므로 20만개의 메일을 처리하기 위해서는 회사내의 공식 네임서버가 있다고 해도 독립적으로 메일서버에 설치하는 것이 좋을 것이다. 7.10 100만통의 이메일 처리를 위하여 소규모 처리를 담당하는 서버에서 대규모 서버로 진화하기 위해서 어떤 것이 필요하고 그 과정에서 중요한 단계마다의 병목은 무었인지 그리고 이 것을 어떻게 해결할 수 있는지에 대해서 알아 보았다. 한 개의 서비스가 커지면 가능한 옵션을 모두 다시 검토하여야하고, 하드웨어 자원을 추가로 요구하며, 로그 파일 처리등의 관련 프로그램의 효율성이 증대되어야 하고, 네임서버와 같은 또다른 서비스까지 자신에게 맞추어 줄 것을 요구한다. 또한 한 개의 서버가 문제를 일으키면 주변의 다른 서버까지 문제가 파급된다는 것도 보았다. tcpdump같이 다른 컴퓨터 사이의 동작을 감시하는 프로그램에 대한 사용법도 익혀 줄것을 부탁한다. 이모두는 서로 보완적이므로 한 개의 서비스를 위해서 그 프로그램만을 들여다 보아서는 안되고 전체를 볼 줄 알아야 할 것이다. 이 글에서는 TCP/IP 포트 재지정에 의한 분산, 메일 전송 정보가 들어 있는 qf* 파일을 분석하여 각각의 전송 실패 이유에 따른 큐디렉토리 분산, 전송할 수 없는 메일에 대한 처리, sendmail.cf의 각각의 옵션에 대한 관찰등은 하지 않았다. 관심있는 독자들은 sendmail 책과 /var/spool/mqueue/qf* 파일에 대해 조사해 보기 바란다. 100만통의 메일을 하루에 처리할 수 있는 초대규모 메일서버는 한 개의 서버로는 한계가 있다. 각각 20만통의 메일을 처리하는 5대의 메일서버가 필요하게 될 것이다. 문제는 이들을 묶어서 단일한 서버로 보이게 하는 방법이 필요하게 된다. 수백대의 서버를 묶어 놓고 IP 라운드로빈 방법을 사용할 수 있다. IP 라운드 로빈은 1.2.3.4,1.2.3.5가 같은 a.b.c.d 도메인명을 가지도록 하고 네임서버 조회 때마다 한 번씩 다른 숫자 IP를 넘겨 주는 방법을 사용한다. 필자가 최종적인 해결책으로 보고 있는 것은 IP-tunneling을 사용한 리눅스 virtual-sever(vs)를 사용하는 것이다. 이 방법은 한 개의 frond-end가 각각의 접속을 받아서 실제 서비스를 하는 back-end 서버에게 접속을 넘겨 주는 것이다. 한 번 접속이 이루어 지고 나서는 client와 back-end간에 직접 접속이 이루어지게 되므로 frond-end는 바로 다음 접속을 처리할 수 있다. vs 리눅스를 개발하는 팀에 의하면 한 대의 frond-end가 1G 급의 부하를 처리할 수 있었다고 한다. 관심있는 사람은 vs홈페이지(http://proxy.iinchina.net/ wensong/ippfvs/)를 방문해 보기 바란다. 최근 외국의 개발업체에서 이 기능을 특화시킨 분산 서버를 제작해서 상업화 시켰다는 이야기도 들은 바가 있다. 이미 리눅스의 메일서버로서의 기능은 신뢰할 만하고 추가 비용이 전혀 필요 없다. 사용자 수 추가에 따라 비싼 라이센스 비용을 지불해야 하는 상용 서버가 설 자리가 없어 지고 있다. 여기에 더해서 사용자 인증, 삭제, 추가 기능을 간편하게 할 수 있는 프로그램이 개발되어 100만통의 메일을 처리할 수 있는 분산 서버와 결합하게 되면 인터넷의 거의 모든 메일서버는 리눅스가 점령하게 될 것이다. 7.11 이 달의 숙제 메일서버와 마찬가지로 웹서버도 많은 히트수를 기록하게 되면 로그 파일이 커질 것이다. /var/log/httpd에 가보았더니 access_log가 30M였다. sendmail을 위해서 설명한 logrotate.conf와 같이 설정 파일을 만들고 하는 것이 시간이 걸려서 잠시 미루고 일단 수동으로 로그 파일을 빨리 정리하고 싶다. 어떻게 하면 될까? 참고로 "rm access_log"라고 해도 로그 파일이 줄어 들지는 않는다. 이건 또 왜 그런 것일까?
8. 기업 환경을 위한 리눅스 블랙박스 만들기[8] 8.1 아파치 웹서버의 설정 지난 달의 무거운 주제를 벗어나 이 번호에는 다시 윈도우 사용자, 회사에 리눅스를 이용해서 서버를 구성하려고 하는 사람들을 대상으로 웹서버를 설정하는 법에 대해서 알아보기로 하자. 필자에게 메일로 문의를 하는 사람들이 많은데 대체적으로 질문의 내용이 전혀 예상하지 못했던 것이 많았다. 나름대로 윈도우를 사용하듯이 리눅스를 쓸 수 있도록 하자는 목적으로 쉽고 쓸려고 노력했지만 여전히 독자들은 어려움을 느끼고 있다는 생각을 했다. 윈도우 사용자에게 친숙할 것이라고 생각했던 그래픽 방식의 제어 툴인 웹민의 설명들이 영어로 되어 있고 옵션들이 각기 다른 페이지에 있어서 생각만큼 쉽지 않은 것이다. 웹민은 리눅스 관리에 어느 정도 익숙하여 무엇을 해야 할 지 아는 사용자들이 편하게 작업할 수 있는 환경이라는 판단이다. 윈도우만 쓰던 사람들은 웹민을 이용해서도 제대로 작업하지 못하는 경우가 많았다. 그러므로 가능하면 리눅스 내부적인 동작에 대해서 설명을 주로하고자 한다. 또한 글의 내용도 리눅스에 전혀 경험이 없는 윈도우 사용자들의 눈높이에 맞추기 위해서 노력하겠다. 8.2 윈도우 사용자를 위해서 웹서버를 구성하기 위해서는 NT가 필요하다. 윈도우98은 개인용 운영체계로 웹서비스를 하기에는 부적합하다. 물론 억지로 할 수는 있지만 전혀 권할만한 것이 아니다. 생각을 윈도우 사용자에 맞추어 보면 이들이 새롭게 NT를 설정하여 웹서버 세팅까지 해내는 것이 쉬운 일만은 아니라고 생각된다. 여태까지 연재한 글을 참고하여 웹민을 이용해 삼바와 메일서버를 세팅할 수 있었다면 내친 김에 리눅스에서 아파치를 설정하는 것이 편할 수도 있다. 리눅스의 킬링 소프트웨어인 아파치 웹서버를 설정, 관리하는 방법을 자세하게 알아보도록 하자. 웹서버 프로그램을 돌리기 위한 HTTP 프로토콜은 사실 매우 단순하다. 그 때문에 많은 웹서버 프로그램이 존재한다. 상용제품도 있고 무료제품도 있으며, 무료일 뿐만 아니라 소스까지 제공하는 것도 있다. 또한 perl, tcl같은 스크립트 언어를 사용한 것도 있다. 대표적으로 웹민은 perl로 만든 특별한 작업을 위한 웹서버이다. 그 중에서 인터넷에서 지배적으로 사용되고 있는 것은 아파치와 MS의 IIS이다. MS의 IIS는 NT의 쓰레드 기능 위에서 동작하므로 빠른 속도를 자랑한다. MS에서 제공하는 여러 프로그램을 이용해 쉽게 기능을 확장할 수 있고 윈도우 운영체계에 내장된 기능을 활용할 수 있다. 그리고 ISAPI를 사용한 asp 스크립트 방식은 그 어떤 웹서버보다 빠른 성능을 보인다. 그러나 NT의 쓰레드기능은 치명적인 문제를 가지고 있다. 대부분의 자원을 쓰레드끼리 공유하면서 동작하는 방식을 쓰기 때문에 여러개의 쓰레드 중에서 한개가 에라를 발생시키면 모든 쓰레드에 이 에라가 파급된다. 리눅스(유닉스)의 프로세스 모델에서 돌아가는 아파치는 자식 프로세스를 따로 두고 이들이 독립적으로 접속을 처리하며 한 개의 프로세스가 치명적인 에라를 발생시켜도 그 프로세스만 죽을 뿐 에라가 다른 접속을 처리하는 프로세스에게 전파되지 않는다. 속도와 안정성의 균형이 중요한데 필자가 일하는 회사의 개발자 의견은 웹데몬같이 무작위 접속이 가능한 소프트웨어는 쓰레드 모델이 부적당하다는 결론이었다. 실제로 잘못된 asp가 웹서버 전체를 죽일 수 있으며 심각한 경우에는 NT자체가 정지하는 경우가 많았다. 또한 이런 에라는 꼭 새벽에 관리자가 없을 때 발생해서 아침까지 서비스를 할 수 없게 만든다. 속도와 안정성 사이에서 독자들의 현명한 판단을 바란다. 삼바로 리눅스의 웹서버 루트 디렉토리를 윈도우 박스에 연결해 놓으면 리눅스에서의 작업은 전혀 필요 없다. 리눅스 박스에 있는 파일을 윈도우에서 에디팅한 후에 저장하고 바로 웹검색 프로그램으로 그 결과를 볼 수 있다. 가상호스팅등을 사용하지 않는다면 아파치 설정 자체를 고칠 필요도 없다. 오로지 웹페이지 만들기에만 집중해도 된다. 8.3 숙제 풀이 메일서버와 마찬가지로 웹서버도 많은 히트수를 기록하게 되면 로그 파일이 커질 것이다. 로그 파일이 커지면 로그를 적는데 시스템 자원을 소모해야 한다고 지난 달에 말한 바 있다. 이 파일을 줄이기 위해서 "rm access_log"라고 해도 아파치의 자원 사용량은 줄지 않는데 그 이유는 리눅스(유닉스)의 특성 때문이다. 리눅스의 파일은 inode로 관리되는데 하드디스크 디렉토리 항목에 할당된 이름(ls 했을 때 나오는 파일명)에 참조계수가 할당되듯이 파일을 열 때에도 할당된다. 즉 같은 inode에 대해서 참조계수값이 2일 때 한쪽을 없앤다고 해서 물리적인 파일이 사라지지는 않음을 뜻한다. /var/log/httpd 디렉토리의 access_log를 제거했을 때 더 이상 access_log를 검색할 수는 없지만 아파치가 떠있는 동안은 이름없는 같은 파일이 물리적으로 존재하고 있으며 아파치는 그 파일의 뒷부분에 계속 로그를 덧붙이고 있는 상태가 된다. 이를 해결하려면 아파치가 열고 있는 파일을 닫고 같은 이름의 파일을 다시 열도록 해야 하는데 그 방법은 아파치를 재시작 하거나 다음 명령을 내리면 된다. # rm access_log # killall -HUP httpd 또는 # mv access_log access_log.old # killall -HUP httpd HUP 시그널을 받은 아파치는 모든 파일을 닫은 후에 다시 열게 된다. access_log를 닫는 순간 참조계수가 0이 되고 파일 시스템에서 이 파일이 사라진 후에 아파치가 다시 access_log를 생성하게 된다. 이제 파일 크기가 0이 되면서 자원 사용량이 줄어들게 된다. 이 설명이 어려우면 이글의 뒷부분을 참조하기 바란다. 8.4 아파치 인스톨 사실 리눅스 배포본을 제대로 인스톨 했다면 아무 것도 할 것이 없다. 설치 과정에서 apache 패키지를 선택했다면 이미 웹서버가 동작중이다. 리눅스 서버의 아이피가 1.2.3.4라면 http://1.2.3.4 라고 쳐보기 바란다. 아마 "It's Worked"라는 문구와 아파치의 심볼인 가벼운 새의 깃털을 볼 수 있을 것이다. 여러분의 리눅스 서버에는 이미 웹서버가 설치되어 있고 제대로 동작하고 있다는 것을 보여주는 것이다. 만약 에라가 뜬다면 아파치를 인스톨하면 된다. 리눅스 시디롬을 마운트 한다.(시디롬이 세컨더리 마스타에 붙어 있다고 가정) # mount /dev/hdc /mnt
아파치 패키지를 인스톨 한다. # rpm -i /mnt/RedHat/RPMS/apache-1.3.4-1kr.i386.rpm
아파치를 기동시킨다 # /etc/rc.d/init.d/httpd start 이제 http://1.2.3.4 라고 치면 첫페이지를 볼 수 있을 것이다. 8.5 아파치 기본 파일 위치 아파치가 인스톨되면 실행파일은 /etc/rc.d/init.d/httpd인데 이 것은 시스템이 부팅되면서 아파치를 띄우고 시스템을 끄면 죽이는 동작을 한다. 홈페이지는 /home/httpd/html 이며 http://1.2.3.4로 보이는 파일은 /home/httpd/html/index.html이다. cgi를 실행시킬 수 있는 디렉토리는 /home/httpd/cgi-bin이며 아파치 메뉴얼은 index.html에서 찾아 들어갈 수 있고 그 디렉토리는 /home/httpd/html/manual이다. 기본적으로 제공되는 아이콘은 /home/httpd/icons에 있다. 아파치 실행파일은 /usr/sbin/httpd이다. 그외 로그 파일의 크기를 조절할 수 있는 실행파일과 설정파일등이 있는데 완전한 목록을 보고 싶으면 아래와 같이 실행해 보기 바란다. # rpm -qpl /mnt/RedHat/RPMS/apache-1.3.4-1kr.i386.rpm 앞으로 주로 고치게 될 파일은 /etc/httpd/conf/httpd.conf이다. /etc/httpd/conf 아래에는 srm.conf, access.conf도 있는데 1.3.x버전으로 오면서 httpd.conf에 통합되었고 쓰지 않는다. mime.typs, magic은 각종 파일을 처리하는데 필요한 파일 속성 정보가 담겨 있고 손댈 필요는 전혀 없다. 앞에서 말한 아파치 디폴트 디렉토리 설정은 httpd.conf에 있고 원하는 경우 이 파일을 고쳐서 재설정할 수 있다. 독자들이 파악해야 할 것은 httpd.conf와 이 파일에 적힌 디폴트 디렉토리 정보에 대한 것이다. 그외는 아파치를 재컴파일 하거나 독립적인 모듈을 추가할 것이 아니라면 전혀 신경쓸 필요가 없다. 8.6 웹페이지를 윈도우에서 편집하기 리눅스의 웹서버 홈디렉토리의 파일들을 윈도우에서 편집하고 싶으면 삼바 설정을 고쳐서 윈도우에서 이 디렉토리를 볼 수 있게 하면 된다. /etc/smb.conf 설정에 다음을 추가하자. [html] comment = webserver path = /home/httpd/ force user = kkyc force group = kkyc create mask = 0755 read only = No guest ok = Yes force user와 force group은 필자의 웹서버를 주로 작업하는 사용자명이다. 이렇게 해 놓으면 어떤 사람이 편집하더라도 파일의 소유권이 kkyc에게 있으므로 지우기, 변경이 용이하다. 여러분의 사이트에 주로 편집하는 사용자명으로 바꾸던지 아니면 아예 이 항목을 제거해도 된다. create mask 값은 웹파일에 모든 사용자들이 읽기 권한을 주도록 하기 위해서 쓴다. 삼바의 설정을 변경했다면 삼바를 다시 시작해야 적용이 된다. # /etc/rc.d/init.d/smb stop # /etc/rc.d/init.d/smb start 화면 1은 서버의 /home/httpd 디렉토리를 윈도우 드라이브 I:에 매핑시키고 그 아래 /home/httpd/html 파일을 열고 있는 모습니다. index.html은 확장자가 html이므로 넷스케입 아이콘이 나타났다. 그 위에는 엑스메니저로 한텀을 열고 같은 디렉토리를 본 모습이며, 왼쪽 위에는 윈도우의 넷스케입으로 index.html을 연 모습이다. 나모 웹에디터(책을 샀을 때 준 한정 사용판, 필자는 윈도우 프로그램을 사용하지 않기 때문에 이 화면을 위해서 잠시 인스톨 했다)에서 같은 파일을 에디팅 하기 위해서 열어 놓은 모습이다. 삼바로 리눅스 웹서버 홈 디렉토리를 디스크로 매핑시키면 윈도우에서 작업하는 것과 다를 바 없다. 이 화면은 윈도우에서 리눅스 웹페이지 작성을 하는 방법의 모든 것을 한꺼번에 보여 주고 있다. 리눅스 웹페이지 작성법에 관해서 이 화면보다 더 직관적이고 쉽게 보여줄 수 있는 방법이 없다. 이 화면을 이해할 수 있다면 여러분도 웹페이지 작성에 나설 수 있을 것이다.
주의할 점은 리눅스에서는 파일명의 대소문자를 엄격하게 구별한다는 것과 윈도우에서 파일확장자를 자체적으로 관리하는 바람에 확장자가 겹칠 수 있다는 것이다. 그래서 웹페이지에 back.jpg를 읽어 오도록 링크를 적었지만 실제 저장은 back.JPG로 되어 있거나 back.jpg.JPG로 되어 있을 수 있다. 웹페이지에 적은 대로 화면이 나타나지 않으면 이런 이유때문이므로 한텀을 열어 놓고 실제 저장된 파일명을 확인하는 것이 좋을 것이다. 그리고 덧붙여 말하자면 윈도우에서 편집하다보면 헷갈려서 편집한 파일을 리눅스에 가져다 놓지도 않고 링크가 되지 않는다고 고민하는 경우도 있다. 웹서버로 확인할 파일은 리눅스에 옭겨 놓았는지 꼭 확인하도록 하자. 사용자들이 하루에 100명 미만으로 방문하는 사이트라면 여기까지 읽고 웹페이지 제작을 쉽게 해주는 나모 웹에디터 같은 윈도우 프로그램을 구해서 작업을 하면 된다. 거의 대부분의 사이트가 여기에 해당될 것인데 리눅스 박스를 잘못 다루지만 않는 다면 여기까지 읽는 것으로 아파치 웹서버 만들기는 끝났다고 할 수 있다. 이 처럼 리눅스를 웹서버로 사용하는 것은 쉬운 일이다. 이후의 글이 도움이 되기는 하겠지만 리눅스 작업이 필요하므로 원하는 사람만 읽기 바란다. 8.7 아파치 기본 설정 아파치는 수많은 옵션이 있으며, 아파치를 지원하는 수많은 모듈이 있다. 배포본의 기본 설치로도 일반적인 사용에 전혀 문제가 없지만 히트수가 증가하거나 한개의 서버로 여러 사이트를 서비스하거나 각 부서별로 각각의 페이지를 열고자 할 때, 그리고 방명록, 게시판같은 CGI를 붙여야 하거나 여태까지 잘 돌던 서버가 이상한 동작을 보일 때, 설정파일에 관심을 가져야 한다. 건강한 사람을 보고만 있으면 병들었을 때 대책이 없게 된다. 기본원리에 대해서 파악을 해 놓고 동작방식을 이해한 후에 비정상적인 상황을 고쳐가면서 관리를 해야 웹서버가 이상동작을 할 때 빠른 시간에 문제를 해결할 수 있을 것이다. 그러므로 앞으로의 내용은 소규모로 운영하며 제대로 동작하는 동안에는 전혀 필요가 없지만 꼭 관심을 가지고 읽어 보아야 할 내용이라고 생각된다. 그래픽 설정 툴 아파치가 유명해지면서 여러 그래픽 설정 툴이 나오고 있다. 텍스트 방식의 아파치 설정 파일을 들여다 보는 것 보다는 그래픽 방식이 좀 더 직관적이고 각 옵션간의 연관관계를 쉽게 파악할 수 있으므로 필자는 가능하면 이런 툴이 많이 나오고 사용자들도 적극적으로 사용하기를 권하는 편이다. 그 중에는 오픈소스도 있고 상용 버전도 있다. 패키지 배포본에 주로 포함되는 것은 comanche(COnfiguration MANager for apaCHE)인데 재미있는 이름만큼이나 설정도 쉬운 편이다. 물론 이전 연재에서 설명했던 웹민또한 훌륭한 그래픽 설정툴이다. 코만치는 엑스윈도우 프로그램이므로 엑스메니저에서 실행해야 한다. 웹민은 물론 http://my.host.com:1000/(혹은 바꾼 웹민의 포트)로 접근할 수 있다. 그래픽 설정툴에 사용법에 대한 설명은 지난호까지 지루하게 했으므로 다시 반복하지 않는다. 앞으로 설명하는 설정 방법도 텍스트 방식의 설정법을 참고하여 웹민이나 코만치에서 찾아서 하기 바란다. 그래픽 방식의 작업 결과가 저장되는 파일을 이 글의 내용과 비교하여 차이가 없도록 하면 된다. httpd.conf의 기본 설정 아파치의 설정은 대부분 /etc/httpd/conf/httpd.conf에서 하게 된다. 우선 기본 설정에 대해서 알아보자. 각 설정은 httpd.conf 파일안에서 흩어져 있기 때문에 전체적으로 파악하기가 힘든데 대부분은 디폴트 값을 그대로 사용하면 된다. 관리자가 알아야 주요한 것은 다음과 같다. 아래 설명을 보고 원하는 값으로 바꾸기 바란다. 참고로 한국에서 유명한 리눅스 배포본인 알짜 5.2a에서는 이 파일의 설명 부분을 직접 한글로 번역해 두었으므로 참고해도 좋다. ServerName www.mycompany.com ServerAlias www.mycompan.com *.mycompany.com ServerAdmin root@mycompany.com 서버이름을 정하고 ServerAlias에서 위와 같이 써 줌으로써 http://mycompany.com, http://dev1.mycompany.com으로 접속하더라도 디폴트로 www.mycompany.com이 뜨게 된다. 이 사이트의 관리자는 위에서 적어준 사용자가 된다. Listen 192.168.1.4:80 Listen 192.168.1.4:443 http 프로토콜이 기본적으로 사용하는 TCP/IP 포트는 80번이며 아파치가 이 포트를 사용할 수 있도록 Listen 설정을 해 준다. 443는 SSL인 https 방식에서 사용하는 포트이다. 만약 여러개의 IP를 한 개의 서버에 할당하고 가상호스팅을 한다면 각각의 IP에 대해 Listen값을 적어 주어야 한다. ErrorLog /var/log/httpd/error_log CustomLog /var/log/httpd/access_log common CustomLog /var/log/httpd/agent_log agent 각종 로그 파일 설정을 해 준다. /var/log/httpd 디렉토리가 없다면 만들어야 한다. 문제가 생겼을 때 이유를 적는 error_log, 정상적인 웹검색에 대한 기록을 하는 access_log, 어떤 웹검색 프로그램으로 접속했는지 알려 주는 agent_log가 있다. 그외에 여러 로그파일을 따로 만들 수 있지만 지금은 이런 부분에 신경을 쓰지 않아도 좋다. 리눅스(유닉스) 프로그램들은 어떤 문제가 발생하면 그 원인에 대해서 항상 자세한 내용을 적도록 되어 있다. 여태까지 윈도우의 무의미한 에라 메세지에 익숙한 사용자들은 이 것을 무시하는 경향이 있는데 리눅스에서는 통용될 수 없다. "/var/log/"아래의 여러 파일(messages, secure, lastlog, dmesg)에 관심을 가져야 제대로된 관리자가 될 수 있다. 에라 메세지가 정확하기 때문에 어떤 대책을 세워야 하는지 쉽게 알 수 있다. httpd: [xxx xxx xx xx:xx:xx 1999] [error] [client xxx.xxx.xxx.27] File does not exist: /xxx/xxx/xxx/www/frame_visnote.htm 예를 들어 위와 같은 에라가 error_log에 있다면 해당 파일(frame_visnote.htm)이 있는지 확인하고 이 파일을 링크하고 있는 html 파일을 고치면 된다. 이런 단순한 작업뿐만 아니라 웹서버가 뜨지 않는 에라나 CGI가 실행되지 않을 때도 항상 error_log 파일을 조사해보는 것이 가장 빠른 문제 해결 방법이 된다. User nobody Group nobody 아파치는 보안을 위해서 root로 실행된 다음 사용자 권한을 강제로 User와 Group에 적어준 사용자로 바꾼다. 때문에 웹으로 접속해서 해킹을 하더라도 시스템 파일을 건들수 없도록 해 놓았다. 만약 서버에 nobody 사용자가 없다면 에라가 생길 것이다. 다음과 같이 사용자를 추가할 수 있다. # adduser nobody # passwd nobody 웹서버가 시스템의 일반 사용자 모드로 동작하므로 웹서버의 루트 디렉토리(DocumentRoot)부터 아래의 모든 디렉토리와 파일은 소유자, 그룹, 기타 사용자가 모두 읽을 수 있어야 한다. /home 디렉토리에서 다음과 같이 실행하면 될 것이다. /home# chmod 755 -R httpd
DocumentRoot "/home/httpd/html" <Directory "/home/httpd/html"> Options Indexes FollowSymLinks AllowOverride None Order allow,deny Allow from all </Directory> 이제 웹서버 루트 디렉토리에 대한 설정이다. 이 설정으로 http://www.mycompany.com으로 접속하는 모든 사용자는 /home/httpd/html/index.html을 가장 먼저 보게 되는 것이다. Direcotry 옵션 설정에 나오는 값은 기본값 그대로 사용하면 된다. 각각의 설정에 대한 설명은 다음 기회로 미루기로 하자. <Directory "/home/httpd/cgi-bin"> AllowOverride None Options ExecCGI Order allow,deny Allow from all </Directory> http://www.mycompany.com/cgi-bin/my.cgi 로 실행했을 때 /home/httpd/cgi-bin/my.cgi가 리눅스에서 실행되어 그 결과가 사용자로 전송된다. 즉 my.cgi는 perl같은 스크립트 파일이거나 리눅스용 실행파일이라는 뜻이다. 아파치에서는 각 디렉토리 별로 실행파일을 동작시킬 수 있는지 여부를 지정할 수 있다. "Options" 항목의 ExecCGI 설정이 이 일을 하는데 기본적으로 아파치는 모든 디렉토리에 대해서 파일 실행권을 주지 않는다. 이 설정에 의해서 /home/httpd/cgi-bin에 있는 파일들이 실행될 수 있는 것이다. 참고로 이 디렉토리에 들어 있는 파일은 실행가능모드로 되어 있어야 한다. 필요하면 다음과 같이 하면 된다. /home/httpd/cgi-bin# chmod a+rx my.cgi
Alias /icons/ "/home/httpd/icons/" <Directory "/home/httpd/icons"> Options Indexes MultiViews AllowOverride None Order allow,deny Allow from all </Directory> 웹페이지에서 그림파일을 링크할 때 http://mycompay.com/icons/button.jpg라고 하면 위의 설정에 의해서 /home/httpd/icons/button.jpg가 불려진다. 지금은 가상 디렉토리 설정과 실제 디렉토리 설정이 같으므로 별로 유용할 것같지 않지만 아이콘이 있는 디렉토리가 /usr/lib/icons에 있다면 "Alias /icons/ "/usr/lib/icons/""으로 설정하고 http://mycompayn.com/icons/button.jpg라고 치면 /usr/lib/icons/button.jpg를 불러 올 수 있다. 이 기능은 아이콘에만 해당하는 것은 아니고 모든 물리적 디렉토리를 이런 식으로 매핑하여 사용할 수 있으므로 여러 용도로 사용하기 때문에 쉽게 옮길 수 없는 디렉토리가 있다면 이 방식을 쓸 수 있다. UserDir public_html <Directory /*/public_html> AllowOverride FileInfo AuthConfig Limit Options MultiViews Indexes SymLinksIfOwnerMatch IncludesNoExec <Limit GET POST OPTIONS PROPFIND> Order allow,deny Allow from all </Limit> <Limit PUT DELETE PATCH PROPPATCH MKCOL COPY MOVE LOCK UNLOCK> Order deny,allow Deny from all </Limit> </Directory> 한개의 서버를 사용하여 한 회사의 웹서버를 구축했을 때 각부서의 홈페이지는 따로 구성할 수 있다. http://www.main.com(회사 대표 페이지), http://www.main.com/development/(개발부), http://www.main.com/support/(지원부서). 그런데 각 사원을 위한 페이지를 구성해 주고 싶으면 어떻게 해야 할까? 사용자들에게 리눅스 계정을 만들어 주면 각 사용자의 홈디렉토리가 만들어 진다. /home/a_user, home/b_user,.... 이 때 각 사용자들은 자신만의 홈페이지를 만들기 위해서 /home/a_user/public_html 디렉토리를 만드고 여기에 index.html 파일을 놓으면 http://www.main.com/ a_user 라고 쳤을 때 이 파일을 볼 수 있다. 즉 UserDir 설정으로 아파치가 a_user라는 참조 URL을 보면 이 것을 /home/a_user/public_html로 번역하게 하는 것이다. 이 디렉토리에 index.html이 있다면 이 것이 보일 것이고 그렇치 않다면 디렉토리 리스트가 될 것이다. 회사에서 각 사용자들의 전용 홈페이지를 구성해 줌으로써 애사심이 길러지지 않을까? 사용자의 홈페이지는 단순한 소개 페이지 정도로 그치는 것이 좋다. 게시판이나 파일 다운로드등 본격적인 작업을 하게 해 주면 문제가 생기므로 /*/public_html 디렉토리에 대한 여러가지 제한을 붙이고 있다. 자세한 옵션은 다음에 설명하기로 하고 이 정도로 막아두는 것이 좋다는 것만 알고 넘어가자. 설정을 원하는 대로 바꾸었다면 아파치를 재시작해야 한다. 다음 세가지 방법 중에 한 가지를 쓸 수 있다. # /etc/rc.d/init.d/httpd stop ; /etc/rc.d/init.d/httpd start # /etc/rc.d/init.d/httpd restart # killall -HUP httpd 첫번째가 가장 안전한 방법이며 두번째는 첫번째와 같은 방법이지만 재기동이 안되는 경우도 있다. 세번째 방법은 아파치가 설정파일을 다시 읽도록 하는 방법으로 웹서버를 잠시라도 세울 수 없는 곳에서 쓰는 방법인데 가능하면 첫번째 방법을 사용할 것을 권한다. 이름 기반 가상 호스팅 한 회사의 전용 페이지, 각 부서의 하위 페이지, 개인별 홈페이지만으로도 거의 대부분의 사이트는 충분하다. 이제 A 제품을 판매하는 mycompany.com과 따로 분리하여 B 제품을 판매하는 newbrand.com을 한 회사에서 서비스할 때 어떻게 해야 하는지 알아보자. http 프로토콜은 접속이 이루어진 후에 어떤 도메인에 대해서 서비스를 요청하는지 확인할 수 있도록 되어 있다. 인터넷의 호스트명(newbrand.com)은 IP 번호(1.2.3.4)로 매핑되는데 telnet, ftp등등의 대부분의 응용계층 프로토콜은 IP번호로 접속이 이루어지고 나면 호스트명에 대해서는 관심을 가지지 않는다. # telnet home.hitel.net Trying 203.245.15.78... 위에서 telnet 프로그램은 home.hitel.net 호스트명에 대한 IP 주소를 DNS에 요청한 후에 그 값(203.245.15.78)을 받고 접속이 이루어지며 그 다음에는 home.hitel.net은 전혀 참조되지 않는다. 그러나 http 프로토콜은 접속이 이루어진 후에 URI(Uniform Resouce Identifiers)에 호스트명이 명기되기 때문에(http://newbrand.com/index.html) 이름기반 가상 웹서비스가 가능하다. 웹서버는 URI 표기를 읽어서 목적 사이트를 구별한 후에 가상 호스트마다 다르게 설정된 디렉토리를 검색하여 파일을 전송한다. 가상호스트를 만드는 가장 단순한 설정은 다음과 같다. Listen 192.168.1.4:80 NameVirtualHost 192.168.1.4:80 <VirtualHost 192.168.1.4:80> ServerName www.newbrand.com ServerAlias www.newbrand.com newbrand.com DocumentRoot /home/httpd/newbrand <Directory "/home/httpd/newbrand"> Options Indexes FollowSymLinks AllowOverride None Order allow,deny Allow from all </Directory> <Directory "/home/httpd/newbrand/cgi-bin"> AllowOverride None Options ExecCGI Order allow,deny Allow from all </Directory> ErrorLog /var/log/httpd/newbrand_error_log TransferLog /var/log/httpd/newbrand_access_log </VirtualHost> NameVirtualHost 설정에 의해서 한 개의 IP에 여러 가상 호스트가 있음을 알린다. Listen은 전체 도메인에 대한 서비스(mycompang.com)를 할 때 사용했으면 없어도 된다. 그러나 한 개의 IP에 대해서 반드시 1개는 선언을 해야 한다. 192.168.1.4의 80번 포트로 접속이 이루어지면 www.newbrand.com으로 URI가 적힌 요청에 대해서 이 사이트가 반응을 하게 되고 루트 디렉토리는 /home/httpd/newbrand가 된다. http://www.newbrand.com으로 접속하면 /home/httpd/newbrand/index.html이 전송됨을 알 수 있다. 이 사이트에 대한 cgi-bin 디렉토리는 위에서 적어 준 대로이며 ExecCGI 옵션으로 파일을 실행 시킬 수 있다. 에라 로그와 전송로그는 이 사이트만을 위해서 독립적으로 사용하며 그 파일은 위에 적힌 대로이다. 이제 웹서버는 아래와 같이 동작한다. http://192.168.1.4, http://mycompany.com mycompang.com이 서비스하며 /home/httpd/html/index.html 파일이 전송된다. http://www.newbrand.com /home/httpd/newbrand/index.html이 전송되며 로그는 newbrand_access_log에 쌓인다. 이름 기반 가상 호스팅은 가장 단순한 형태의 가상 호스팅 서비스이다. 한 개의 회사에서 이 방식으로 각각의 브랜드에 따른 다른 회사명으로 웹서비스를 할 때 사용할 수 있다. 센드메일의 가상 사이트 설정을 사용하여 메일까지 가상 호스트와 연관시켜 webmaster@newbrand.com으로 쓸 수 있지만 여기서는 언급하지 않는다. 주소 기반 가상 호스팅 주소 기반 가상 호스팅은 각기 독립적인 IP 주소를 할당받아서 가상 서버를 돌리는 것을 말한다. 이름 기반 가상호스팅과 주소 기반 가상 호스팅은 웹서비스만을 한다면 사실상 별로 차이가 없다. 가장 큰 차이는 주소 기반 가상 호스팅은 각기 독립적인 ftp 서비스를 할 수 있다는 것이다. 현재 웹호스팅 서비스를 하는 업체에서 ftp를 지원하지 않는다면 이름 기반 가상 호스팅으로 모든 것을 처리할 수 있는 상태이다. ftp 프로토콜도 telnet과 마찬가지로 접속이 이루어진 후에는 호스트명을 사용하지 않는다. ftp 프로토콜에서 http와 같이 접속 후에 목적 호스트명을 알 수 있도록 하려는 새로운 RFC 규약이 제안된 상태이며 일부 ftp 데몬 프로그램이 이 기능을 지원하고 있지만 클라이언트 프로그램들이 아직은 이 규약을 따르고 있지 않아서 현재는 이름 기반의 가상 호스팅에서 독립 ftp 서버를 지원하는 것은 어려움이 있다. 주소 기반의 가상 호스팅은 각 호스트 별로 IP를 할당해야 하는 부담이 있는데 IP 주소가 부족한 요즘에는 부적합한 방식으로 생각된다. ftp 규약이 확정되고 모든 클라이언트 프로그램이 이를 지원하기를 기다리도록 하자. ftp를 제외하면 telnet 프로그램(이름 기반 가상 호스팅에서도 "telnet mycompany.com", "telnet newbrand.com" 모두 유효한 방식이다. 물론 같은 물리적 서버에 접속하는 것이다), mail(sendmail은 가상 호스트 기반의 메일 처리를 지원한다), http, pop-3 모두 이름 기반 가상 호스팅을 적용할 수 있으므로 굳이 주소 기반의 가상 호스팅을 할 필요는 없다. 그러나 웹서버가 이름 기반의 가상 호스팅을 지원하지 않았을 때 만들어 둔 웹페이지 내에 호스트명이 아닌 주소방식으로 참조 링크를 건 페이지가 많거나, 독립적인 ftp가 필요하거나, 서버를 분리할 예정인 여러개의 웹서비스를 하고 있을 때에는 주소 기반 가상 호스팅이 필요하다. 그 방법을 살펴 보자. 리눅스에서는 물리적인 한개의 서버가 여러개의 IP를 가질 수 있다. 이더넷 카드를 여러개 꼽아서 할 수도 있고 한개의 이더넷카드에 여러 아이피를 줄 수도 있다. 2.2에서는 IP Alias라는 개념이 조금 변화되기는 했지만 마찬가지로 쓸 수 있다. 지금 여러분의 리눅스 서버에서 ifconfig라고 쳐보기 바란다. 이더넷 카드에 192.168.1.2를 주고 있었다면 다음 명령으로 한개의 장치에 또하나의 IP를 추가할 수 있다. (2.0에서의 모습, 2.2에서는 같은 방식이지만 결과 파일은 조금 다름)
# ifconfig eth0:0 192.168.1.98 # ifconfig
lo Link encap:Local Loopback inet addr:127.0.0.1 Bcast:127.255.255.255 Mask:255.0.0.0 UP BROADCAST LOOPBACK RUNNING MTU:3584 Metric:1 RX packets:26 errors:0 dropped:0 overruns:0 frame:0 TX packets:26 errors:0 dropped:0 overruns:0 carrier:0 collisions:0
eth0 Link encap:Ethernet HWaddr 00:10:4B:9E:4E:CE inet addr:192.168.1.2 Bcast:192.168.1.255 Mask:255.255.255.0 UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:16674 errors:0 dropped:0 overruns:0 frame:0 TX packets:12308 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 Interrupt:10 Base address:0xe000
eth0:0 Link encap:Ethernet HWaddr 00:10:4B:9E:4E:CE inet addr:192.168.1.98 Mask:255.255.255.0 UP RUNNING MTU:1500 Metric:1 RX packets:0 errors:0 dropped:0 overruns:0 frame:0 TX packets:0 errors:0 dropped:0 overruns:0 carrier:0 collisions:0
eth0:0에 대해서 영구적으로 이 IP를 할당하기 위해서는 linuxconf를 쓰던지 webmin을 사용하거나 혹은 엑스메니저를 띄워서 /etc/sysconfig/network-script/ifcfg-eth0를 /etc/sysconfig/network-scripts/ifcfg-eth0:0 로 복사하고 다음과 같이 편집하면 된다. (레드헷을 사용한다면 netcfg를 쓸 수도 있다) /etc/sysconfig/network-scripts/ifcfg-eth0 의 내용
DEVICE=eth0 IPADDR=192.168.1.2 NETMASK=255.255.255.0 NETWORK=192.168.1.0 BROADCAST=192.168.1.255 ONBOOT=yes
/etc/sysconfig/network-scripts/ifcfg-eth0:0 의 내용
DEVICE=eth0:0 IPADDR=192.168.1.98 NETMASK=255.255.255.0 NETWORK=192.168.1.0 BROADCAST=192.168.1.255 ONBOOT=yes 이렇게 IP 주소를 할당했다면 httpd.conf에 다음과 같이 추가한다. # for www.newaddress.com Listen 192.168.1.98:80 <VirtualHost 192.168.1.98:0> ServerName www.newaddress.com ServerAdmin webmaster@newaddress.com DocumentRoot /home/httpd/newaddress <Directory "/home/httpd/newadress"> Options Indexes FollowSymLinks AllowOverride None Order allow,deny Allow from all </Directory> <Directory "/home/httpd/newaddress/cgi-bin"> AllowOverride None Options ExecCGI Order allow,deny Allow from all </Directory> ErrorLog /var/log/httpd/newaddress_error_log TransferLog /var/log/httpd/newaddress_access_log </VirtualHost> 192.168.1.98에 대한 Listen 옵션을 새로 주고 나서 서버 이름, 다큐먼트 루트, 루트 디렉토리에 대한 설정, cgi-bin 디렉토리에 대한 설정을 해 주면 된다. 자세히 보지 않더라도 이름 기반의 가상 호스팅과 크게 차이가 나지 않는다는 것을 알 것이다. 설정 파일의 튜닝 이제 기본적으로 아파치에서 호스트 설정에 대해서 할 수 있는 작업은 모두 끝났다. 여기까지 성공적으로 했다면 서버 관리자로서 손색이 없다고 할 수 있다. 이제 아파치를 사용하면서 속도, 성능, 안정성에 영향을 미칠 수 있는 몇가지 설정을 살펴 보도록 하자. 우선 설정 파일에서 성능을 변화 시킬 수 있는 사항은 다음과 같다. Timeout 300(초단위) 한 번의 GET 요청에 소요되는 총시간등의 설정값이다. 1200에서 300으로 디폴트값이 내려왔는데 문서에 의하면 이 값도 상당히 큰 값이라고 한다. KeepAlive On 접속한 클라이언트의 요청을 처리한 후에 연결을 계속 유지하고 있으면 클라이언트의 다음 번 요청에 대해서 초기 시간을 절약할 수 있다. 이 것을 Off로 두면 상당한 성능상의 저하를 보인다. 참고로 최근에 윈도우 NT와 리눅스의 자체 성능 비교를 행한 Mindcraft사에서 리눅스 웹서버 성능 테스트를 하면서 이 값을 Off로 두고 했다고 한다. 가희 넌센스가 아닐 수 없다. 이 값은 디폴트로 On으로 설정되어 있으며 대부분의 웹서버에서 그렇게 쓰고 있다. MaxKeepAliveRequests 100 한 번의 접속에 대해서 접속을 끊지 않고 몇 번까지 요청을 받을 것인가에 대한 설정이다. 한 번의 접속에서 100번의 요청을 받은 후에는 접속을 끊고 다시 처음부터 접속 과정을 거치게 된다. 물론 내부 과정이 클라이언트측에 보여지는 것은 아니다. 문서에 의하면 대규모 사이트라면 이 값을 가능한 높일 것을 권하고 있다. 0으로 하면 클라이언트가 스스로 접속을 끊기 전까지 계속 연결되어 있게 된다. KeepAliveTimeout 15 클라이언트가 15초 내에 다음번 요청을 하지 않으면 접속을 끊는다. 사용자들이 웹페이지를 읽는 시간을 고려하면 이 값을 증가시켜도 좋을 것이다. MinSpareServers 2 아파치는 자식 프로세스를 분기(fork)해서 http 요청을 처리한다. 동시에 많은 요청이 들어오면 그 때마다 자식 프로세스를 분기해야 하는데 한 번의 분기에 많은 시스템 자원이 필요하며 지연 시간이 생긴다. 요청이 없어도 미리 자식을 만들어 놓으면 이런 지연 없이 서비스를 빠르게 처리할 수 있다. 물론 너무 많은 여유 프로세스를 많들어 놓는 것도 시스템 자원의 낭비를 가져온다. 히트수가 많은 사이트라면 이 값을 늘이면 상당한 성능의 증가를 가져올 수 있다. 앞에서 말한 Mindcraft사에서는 이 값을 1로 두고 NT와 성능 비교를 했다. 아래의 MaxSpareServers와 비교해서 적당한 값을 쓰면 된다. MaxSpareServers 10 최대로 생성할 수 있는 여유 자식 프로세스 수, 자원을 낭비하므로 너무 큰 값은 사용하지 말 것. MaxClients 128 한 서버가 감당할 수 있는 최대 동시 접속 수, 이 값을 크게 해야 할 필요가 생기고 그만큼 동시 접속이 많아 진다면 하드웨어의 업그레이드도 생각해야 할 것이다. MaxRequestsPerChild 100 아파치 데몬이 뜬 후에 자식 프로세스를 생성하면 자식 프로세스는 여기에 적힌 갯수 만큼의 접속을 처리한 후에 죽는다. 이렇게 하면 자식 프로세스가 점유한 자원이 깨끗하게 청소가 되므로 아파치가 오래 떠 있어도 문제가 없게 된다. 이 값을 0으로 하면 한 번 뜬 자식 프로세스는 결코 죽지 않으므로 속도의 증가가 있겠지만 잘못된 코드가 실행되면서 메모리 누수등이 있었을 때 대책이 없어지므로 가능하면 적절한 값을 사용하도록 권고하고 있다. 디폴트 값은 0이지만 100혹은 그 이상의 값을 써주는 것이 좋을 것이다. HostnameLookups Off 아파치가 접속을 받아 들였을 때 어디에서 접속이 들어왔는지 확인하기 위해서 호스트명에 대해 IP 주소를 확인하고 다시 IP 주소에 대해 호스트명을 확인하는 작업을 네임서버에게 의뢰한다. 이 때 상당한 시간이 필요하기 때문에 이 값을 반드시 Off로 설정해야 한다. On으로 해 놓으면 눈에 띄는 성능의 감소를 볼 수 있다. 로그 파일의 정리 아파치 로그파일은 계속적으로 증가하며 히트수가 많아지면 일주일에 100M 까지 증가할 수 있다. 로그 파일이 커지면 성능에 영향을 미치므로 짧은 주기로 정리하는 것이 좋다. 다음은 필자가 만들어 쓰고 있는 웹서버용 로그 파일 정리 프로그램이다. # crontab -e ---------- # 한시간 마다 로그 파일을 정리한다. 1 * * * * /root/bin/logfiles /root/bin/logfiles
#!/bin/sh export PATH=$PATH:/bin:/usr/bin:/sbin:/usr/sbin:/root/bin
logrotate /root/bin/syslog.httpd killall -HUP httpd if [ $? -ne 0 ]; then /etc/rc.d/init.d/httpd start fi
/root/bin/syslog.httpd
daily size 100k rotate 4 # send errors to root errors root # create new (empty) log files after rotating old ones create # uncomment this if you want your log files compressed #compress /var/log/httpd/access.log { }
/var/log/httpd/agent.log { }
/var/log/httpd/error.log { }
/var/log/httpd/suexec_log { }
한시간 마다 logfiles 파일이 실행되고 이 프로그램은 syslog.httpd를 읽어서 access.log등의 이름을 바꾼다. 그 후에 httpd에 HUP 시그널을 주어서 새 파일을 열도록 만든다. HUP 시그널에 잘못된 반응을 하게 되면 /etc/rc.d/init.d/httpd start로 아파치를 다시 띄운다. 사실 필자의 프로그램은 짤라낸 로그를 따로 한 곳으로 모으고 일정 크기 이상이 되면 압축하여 백업본을 만들도록 구성했지만 복잡한 것은 보이기가 부적당하여 생략했다. 이 부분을 생략했기 때문에 필자가 보여준대로 하면 syslog.httpd에서 rotate 값이 4이므로 최대 4시간의 로그만 남는 문제가 있다. rotate 값을 24로 늘여서 하루분의 로그를 남기던지 crontab에서 logfiles가 실행되는 시간을 늘여주기 바란다. 나머지 이야기 아파치는 PHP혹은 perl을 이용하면 자연스럽게 데이타베이스 프로그램과 연동할 수 있다. 현재 가장 빠른 성능을 보이는 mysql(mysql은 상용 제품이지만 개인 사용자에게는 소스까지 제공한다)를 연계해서 웹데이타베이스로 꾸밀 수 있고 다양한 서드파티 모듈(물론 GPL이다)을 컴파일해서 추가하면 또다른 능력을 발휘할 수 있다. 필자는 이런 응용 프로그램 사용법까지 일일이 설명할 생각은 없지만 원하는 모듈이 있을 때 이를 컴파일하는 방법에 대해서 알아 보기로 하자. 또한 아파치를 컴파일 하면서 성능 증가를 위해서 고려해야 할 것들이 있으므로 아파치 컴파일 방법에 대해서도 다음 호에 쓰도록 하겠다. 그리고 기본적인 설정외에 본격적인 설정에 대해서도 알아보기로 하자. 다음 호는 지난 호 센드메일과 같이 조금 전문적인 이야기도 들어가게 될 것이므로 이 글을 읽고 있는 윈도우 사용자들은 아파치 설정을 하면서 http://www.apache.org(혹은 /home/httpd/html/manual 아래쪽의 파일들)을 방문해서 가능하면 이 설명서들을 숙독해 주기 바란다. 이 글은 리눅스와 아파치에 대해서 개념이 하나도 잡히지 않은 사용자를 대상으로 쓴 글이지만 일정 정도 지식이 있는 사용자들이라면 중간 과정은 생략할 예정이다.
필자는 이 글을 쓰면서 여러번 앞에서부터 다시 읽고 있다. 가능하면 간단하고 쉬우면서 필요한 것들을 적으려고 했다. 리눅서들에게 기본적인 사항으로 거론할 필요가 없는 것이 윈도우 사용자들에게는 어렵다는 것을 깨닫고 있는 중이다. 최근에 윈도우만 사용하던 어떤 사람에게 지난 기사를 보여주면서 삼바를 설정하도록 시켜 보았는데 며칠동안 끙끙 앓으면서도 해내지 못했기 때문이다. 기본 지식이 없는 상태에서는 그래픽 방식이 전혀 도움이 되지 않는다는 것을 깨닫고 이제 가능하면 기본 지식을 쉽게 전달하고자 한다. 이 글도 어렵다면 필자에게 연락하기 바란다. 좀 더 단순하고 명확한 방법을 같이 찾아 볼 수 있으면 좋겠다고 생각하며 이글을 마친다. 8.8 이달의 숙제 NT의 IIS에서 주로 작업했기 때문에 각 디렉토리의 디폴트 페이지로 index.html보다 default.html을 쓰는게 더 편하다. 그리고 일부 웹페이지 작성자는 아파치의 약속에 따라 어떤 디렉토리는 index.html을 두고 있다. 그래서 명시적으로 파일명을 적지 않고 디렉토리를 요청하면 index.html과 default.html 둘 중에 하나가 있으면 그 것을 보내주려고 한다. 앞으로는 리눅스에서 작업할 것이므로 index.html이 증가하게 될 것이니까 둘 다있으면 index.html을 먼저 서비스 하자. 어떻게 하면 될까? 8.9 박스 기사 : 리눅스 킬링 소프트웨어 아파치 NCSA에서 개발한 웹서버의 한 패치 버전(A PAtCH)으로 태어난 아파치 웨서버는 오프소스 개발 방식을 채택하여 수많은 개발자를 끌어 안게 됨으로써 현재 가장 강력한 인터넷 웹서버 프로그램으로 부상했다. 상용 서버가 설 자리를 잃고 IIS또한 계속 무료로 제공하도록 만들었으며 NT의 ASP에 필적하는 PHP는 편리한 프로그래밍, 뛰어난 속도를 자랑하며 아파치의 지배적인 동적 웹페이지 프로그래밍 툴로 자리 잡았다(현재 ASP 소스를 PHP로 바꾸어 주는 프로그램도 나와있다). 여기에 1.3으로 넘어 오면서 DSO(Dynamic Shared Object)모델을 채택하여 데몬 재컴파일 없이 각각의 모듈만 재컴파일하여 필요할 때 동적으로 삽입할 수 있게 함으로써 수많은 지원 모듈이 생겨났다. perl 코드를 오버헤드 없이 실행하도록 해 주는 mod_perl, 보안 웹페이지를 사용하게 해 주는 mod_ssl등이 지원된다. 최근에는 NT에까지 포팅되어 ISAPI를 따르는 NT용 모듈도 실행 시킬 수 있다. 인터넷 연결기능이 중요한 개발 주제가 되면서 그 핵심인 http 프로토콜을 서비스하며 웹 DB와의 연동까지 가능한 아파치가 최고의 인터넷 프로그램이 되었다(웹서버 점유율 아파치 57%, MS-IIS 23%, http://www.netcraft.com/survey/). 아파치는 오픈소스 운영체계인 리눅스 배포본에 포함되어 있고 배포본의 기본 설정을 거의 손대지 않고도 웹페이지를 만들 수 있으므로 리눅스가 인스톨되어 있는 컴퓨터는 아파치 웹서버 머신이라고 부를 수 있을 정도이다. 실제로 아파치는 인터넷에서 가장 높은 점유율을 자랑하며 아파치가 동작 중인 서버의 대부분이 리눅스이다. 아파치 사용자가 많아지면서 유틸리티가 쏟아져 나오고 있고 모듈개발이 활성화 되어 있다. 한국내에서도 아파치 사용자 그룹이 결성되어 있고 여러가지 설정기법과 튜닝법에 대한 한글 문서도 많이 나와 있다. 물론 뉴스그룹등에 관련 질문과 답변도 활발한 편이다. 리눅스에 대한 최소한의 지식만 있으면 이미 설치되어 있는 아파치를 이용해 바로 웹서비스를 할 수 있다는 점, 전혀 추가 비용이 들지 않는다는 점, 쉽게 가상 호스팅을 할 수 있다는 점, NT보다 우수한 리눅스의 안정성은 이런 가상 호스팅 사이트수가 증가해도 전혀 문제가 없다는 점, 그리고 유닉스의 사용권한 모델에 따라 가상 호스팅에 있어서도 각 사이트간의 보안 문제가 전혀 없다는 점등으로 아파치와 리눅스는 최고의 조합이라고 얘기 할 수 있다. 현재 한국내 대부분의 웹호스팅 업체는 리눅스를 기본 플랫폼으로 사용하고 있다. 리눅스의 서버 점유율은 1998년말 기준으로 17%이며 NT는 36%의 점유율을 가지고 있는데, 성장률은 리눅스가 단연 압도적이다. 윈도우가 오피스 프로그램으로 데스크탑 시장을 점령했듯이 리눅스는 1999년에 아파치와 삼바를 무기로 서버 시장을 석권하게 될 것이다.
이 글은 인쇄본만 남아서 타이핑을 부탁해서 전자 문서화 했습니다. 나름대로 교정을 봤지만 워낙 복잡한 문서라서 오타가 난무합니다. 보시다가 알고 계신 사실과 다른 부분이 보이면 이 문서가 틀린 것이라고 생각해 주시기 바랍니다. 9. 기업 환경을 위한 리눅스 블랙박스 만들기[9]
네임서버 설정 자체가 별로 어려운 일은 아니고 네임 서버에 관한 좋은 책도 판매되고 있으며 인터넷에서 잘 정리된 한글 문서를 구할 수 있기 때문에 특별히 정리할 필요성이 있을지 의문이다. 이 글에서는 네임 서버를 설정해야 하는 당위성을 설명한 후 기존 문서와의 중복을 피하는 방향에서 네임 서버를 설정하는 과정에 대해 언급하겠다. 또한 네임 서버를 운용하면서 고려해야 할 점도 살펴 보기로 하자.
9.2 숙제 풀이
지난 호 숙제풀이는 네임 서버에 대한 지식을 쌓은 후 설명하는 것이 훨씬 효율적이므로 후반부에서 언급하겠다. 숙제는 한 도메인의 지정되지 않은 호스트를 질의했을 때 에러를 내지 않고 기본 호스트로 넘겨주는 방법과 가상 호스트를 위해 하나의 zone 파일로 여러 도메인을 관리하는 방법을 알아보는 것이었다.
9.3 네임서비스 형태의 선택
숫자로 구성된 IP주소는 기억하기 쉽지 않으므로 보통 www.my.com과 같은 문자 방식으로 이름(호스트명과 도메인 명)을 지정한다. 문자이름과 실제의 IP주소를 연결시키기 위해 인터넷에서는 네임 서버를 운용하는데, 이 서버가 하는 일은 사용자가www.my.com을 연결할 때 그 호스트가 1.2.3.4. 라는 IP주소를 갖고 있다는 사실을 알려주는 역할이다.
인터넷이 100개 이하의 컴퓨터가 연결되어있을 때 모든 정보를 /etc/hosts에 적는 것이 가능했지만(컴퓨터가 많지 않은 로컬 서브넷에서는 /etc/hosts를 활용할 수 있다) 이제는 감당할 수 없을 만큼 컴퓨터가 증가했기 때문에 별도의 네임 서버가 필요하다. 네임 서버로 대부분 BIND(Berkeley Internet Name Daemon)를 사용하고 있다. 이 글은 기업체에서(소규모든 대기업체이든) 리눅스를 활용하는 방안에 대한 내용이므로 먼저 '리눅스를 이용한 네임 서버 설정'이 필요한 이유에 대해 생각해 보자.
9.3.1 외부 네임 서버를 사용하는 잇점
회사의 네트웍이 작고 인터넷 접속에 주로 윈도우 박스를 사용한다면 네임 서버를 설정할 필요가 없다. 만약www.my.com으로 회사 홈페이지를 서비스하고 있다면 대규모 ISP의 네임 서버를 이용하는 것이 보다 나은 방법이다.
왜냐하면 인터넷이 연결된 임의의 컴퓨터가 네임 서버에 질의할 때 My.com에 대한 SOA(Start Of Authority. 도메인에 대해 우선권을 가진 호스트)가 ns.my.com (이는 회사의 내부 네트웍에 있다)인 경우 네임 서버를 질의를 위해 회사 내부 네트웍의 트래픽을 사용하기 때문이다.
하지만 SOA가 대형 ISP에 있다면 회사 네트웍을 낭비하지 않아도 된다. 대형 ISP는 성능과 안정성이 우수한 네임 서버 전용 시스템을 운용하므로 보다 빠른 응답 시간을 보장한다. 그 이유는 내부 네트웍보다 훨씬 빠른 물리적 속도를 갖고 있으며 하드웨어 성능 또한 우수하고 무차별적인 질의가 하나의 네임 서버에 집중되므로 이렇게 들어오는 추가적인 질의를 네임 서버가 대규모 메모리에 기억하고 있다가 빠르게 답변 할 수 있기 때문이다.
그에 반해 My.com의 물리적 회선은 대형 ISP에 비해 안정성이 떨어지며 대형 서버에 비해 소프트웨어, 하드웨어 안정성 또한 크게 뒤쳐진다. 만약My.com에 대한 네임 서버가 회사의 ns.my.com에 있다면 이 시스템이 다운될 경우에 복구하기 전까지는 관련 사이트를 외부에서 찾을 수 없어 my.com이 살아있어도 서비스할 수 없게 된다.
하지만 my.com에 대한 네임 서버가 외부에 있다면 이런 일이 일어날 경우가 거의 없다. 윈도우는 서브넷의 다른 윈도우(삼바가 설치된 리눅스 박스 포함)를 찾기 위해 네임 서버를 사용하지 않는다. Netbios 프로토콜은 서브넷의 IP 주소만으로도 충분하고 이 프로토콜이 라우터를 통과해 사용할 목적으로 만든 것이 아니므로 외부 네트웍을 인식해야 할 필요가 없다. 그렇기 때문에 1.2.3.0(0~225)까지의 서브넷에 있는 컴퓨터는 윈도우 이름(네트웍 환경에서 정해준 Netbios 이름)만 구별할 수 있으면 된다. 즉 내부 클라이언트를 위해 네임 서버를 사용하는 것은 아니라는 의미이다.
만약 회사에 여러 대의 리눅스 서버가 있다면 각 /etc/hosts에 관련 이름을 만들어주면 된다. 즉
이라고 적어주면 대부분의 프로그램과 데몬이 호스트를 인식하고 정상적으로 서비스한다.
그러나 회사의 내부 윈도우 박스를 위해 win1.my.com같은 호스트 명을 부여하는 행위는 이 호스트를 외부에서 침입할 수 있는 빌미를 제공하는 것이다. 가능하면 클라이언트는 IP주소만 부여 받는 것이 좋다. 결론적으로 네임 서버는 인터넷에 서비스할 서버를 외부에 알리는데 필요하므로 윈도우가 설치된 클라이언트에게는 불필요하며 클라이언트에는 호스트 명이 필요 없다는 것을 인식해야 한다.
인터넷에 열려있는 서비스는 언제나 해킹의 위험이 있다. 네임 서버도 예외가 아니어서 자주 보안 문제가 생긴다. 크래커가 네임 서버의 보안 허점을 알아내고 서버를 공격하기 시작한 경우라도 이 문제가 공식 적으로 보고되어 해결책이 나오기까지는 일정 기간이 소요된다. 이때는 모든 서버가 위험에 노출되어 있는 시기이다. 또한 버그 보고와 해결책이 발표되었지만, 여러분이 보안에 주의를 기울일 시간이 없어 미처 업그레이드하지 못했다면 문제는 심각하다. 그러므로 위험성이 높은 서비스는 외부의 전문 사이트에 의뢰하는 것이 좋다는 것도 명심해야 한다.
현재 회사에 하나의 리눅스 서버를 웹서버, 메일 서버로 사용하고 있으며 회사 전체에 윈도우 95/98/NT를 사용하는 250대 이하의 컴퓨터가 있다. 그리고 리눅스 서버의 호스트 명이 www.my.com이고 이 도메인이 외부 ISP에 등록되어 있다면 이 글의 나머지 부분을 전혀 읽을 필요가 없다. 필자의 판단으로는 현재 상태가 최적이라고 생각되기 때문이다.
9.3.2 자체 네임 서버를 사용하는 이유
앞에서 다뤘듯이 외부의 무차별적인 질의를 처리할 용도라며 당연히 네임 서버를 둬야 할 정도로 로컬 네트웍(로컬 네트웍이란 자신이 관리하고 할당 받은 IP주소라고 하자)의 IP 주소와 도메인이 많을 경우일 것이다. 대형 ISP가 이런 경우에 속하는데 이 글은 이런 도메인 관리자를 위한 내용이 아니므로 그에 관한 부분은 고려하지 않는다.
만약 로컬 네트웍에서 사용하는 프로그램이 네임 서버에 질의를 많이 해야 한다면 네임 서버를 로컬에 두는 것이 좋다. 프로그램이 수많은 호스트의 IP 주소를 알아야 할 필요가 있는 경우는 회원에게 전자메일을 대량으로 전송하거나 co.kr 아래의 사이트를 검색하는 경우 등이다.
메일 서버가 전자메일을 전송하기 위해 네임 서버에 질의를 보내는데 횟수가 수천, 수만 번을 넘으면 외부의 네임 서버에 보내는 질의가 회사 네트웍을 점유하게 된다. 이때는 캐싱 전용 네임 서버를 설치하는 것이 효율적이다. 또한 캐싱 전용 네임 서버는 회사의 네트웍이 느릴 때 쓸모 있는 경우가 많다. 인터넷을 사용해 특정 사이트를 방문한다면 다른 직원도 같은 사이트를 방문할 가능성이 높기 때문이다. 물론 이런 경우 프록시 서버를 구성할 수도 있는데 여기서 언급하지 않겠다. 전화 접속 방식으로 리눅스서버에 접근하는 개인 사용자도 캐싱 전용 네임 서버를 사용하면 좋을 것이다.
회사에서 여러 도메인을 관리하는 경우에도 네임 서버가 필요하다. 20개 이상의 도메인을 관리하고 있다면 도메인 변경이나 서버 교체작업을 위해 해당 도메인에 대한 정보를 하나씩 바꿔야 하는데 네임 서버가 외부에 있다면 그 작업이 쉽지 않을뿐더러 변경 내용도 즉시 반영되지 않는다. 최근에 리눅스가 웹호스팅 서버로 많이 사용되고 있는데 네임 서버가 외부에 있을 경우 가상 도메인을 하나의 IP 주소에 수백, 수천 개씩 설정한 다음에는 사이트 분리, IP주소 변경 등이 거의 불가능 하게 된다.
그리고 서버 프로그래밍을 하면서 테스트 사이를 번번히 만들고 없애는 경우에 자체 네임 서버를 구성할 필요가 있다. 외부에 알려지지 않는 비공식 네임 서버지만 내부 컴퓨터가 이 네임 서버를 프라이머리 네임 서버로 지정하고 있으면 프로그램이 테스트를 위해서 임시로 만든 호스트 명을 찾지 못해 에러가 발생하는 문제가 없이 회사 내부 컴퓨터를 찾을 수 있다.
9.3.3 네임 서버, 효율성과 편리함 사이의 선택
필자가 회사에 리눅스 서버를 도입하면서 당연히 회사 도메인을 위한 네임 서버를 설치하려고 했다. 하지만 기존 웹서버 관리자와 경험을 공유한 후 리눅스 서버가 도입된다고 네임 서버까지 설치할 필요는 없다는 것에 동의했다. 현재는 외부에 서비스하는 웹사이트는 외부 네임 서버를 이용하고 회원에게 밤새 수만 통의 전자메일을 보내야 하는 메일 서버에는 전자메일만을 위한 캐싱 전용 네임 데몬을 설치했다. 그리고 웹 호스팅 서버에는 해당 도메인이 매우 많으므로 웹 호스팅용 네임 데몬을 설치했다. 그리고 개발 작업을 위해 번번히 임시 호스트가 증설되는 데 이들 설정을 모든 리눅스 윈도우 클라이언트에 수동으로 적용하기 힘들어 회사 내부용 네임 서버도 구축해 놓았다. 그 외에도 윈도우 박스는 접속하지 않지만 서버 간의 작업을 위해 (주로 백업) 임시로 만든 호스트는 관련 서버의 /etc/hosts에 필요할 때마다 기록해 사용하고 있다.
소규모 회사에서 리눅스 서버를 도입한다면 이보다는 덜 복잡할 것이다. 무조건 네임 서버를 설치하기 전에 효율과 편리성을 비교해보는 일이 필요하다. 네임 서버에 대한 질의가 내부적으로 많이 이뤄진다면 자체 서버를 구성하고 그렇지 않고 외부의 무차별적인 질의가 많다면 ISP를 이용하는 것이 유리하다. 또한 한 회사에 하나의 네임 서버만 있어야 하는 것도 아니다. 앞에서 보았듯이 각 경우에 필요한 만큼의 네임 서버를 필요한 곳에 두고 서로 독립적으로 사용해도 된다.
9.4 네임 서버에 대한 기초자료
네임 서버를 구성하는데 필요한 기초 지식과 각 필드의 의미 등에 대해 필자가 지루하게 다시 설명할 필요가 없을 정도로 잘 정리된 문서들이 있다.
우선 한 회사의 도메인을 위해 빨리 네임 서버를 설정하는 작업이 필요 할 뿐 구체적인 기술은 알 필요가 없다면 http://linux.sarang.net/paper/nameserver/namesever-0.2를 참고하기 바란다. 이 것은 김병찬씨의 기초 강좌인데 네임 서버를 설치할 때 필요한 용어조차 모르는 사용자들을 위해 쉽게 설명되어 있다. 이 문서를 읽고 그대로 따라 하면 제대로 동작하는 네임 서버를 훌륭하게 만들 수 있을 것이다.
보다 구체적이고 상세하며 네임 서버의 기본 동작과 다른 데몬과의 관계, 복잡한 상황을 위한 지식 등이 필요하다면 http://www.kr.freebsd.org/doc/PoweredByDns를 권한다. 김승영 씨의 더 없이 훌륭한 강좌로 이 문서를 꼼꼼히 읽고 나면 네임 서버의 전문가 소리를 들을 수 있을 것이다.
물론 근본 바탕을 충실히 하고 나름대로 응용하고자 한다면 DNS and BIND (O'Reilly & associates)도 읽어보기를 권한다. 그리고 Http://www.isc.org에 있는 BIND 패키지의 자체 문서도 놓칠 수 없다. 어떤 문서에도 볼 수 없는 최신 옵션과 변경 사항을 찾을 수 있기 때문이다. 이와 함께 전문 지식을 갖고 싶으면 RFC 문서 (1101,1122,1123등 BIND 소스트리의 DOC/rfc에 서 찾을 수 있다)도 읽어볼 것을 권한다.
9.5 네임 서버의 기본사항
나머지 부분을 읽기 전에 반드시 김병찬씨와 김승영씨의 강좌를 읽어야 하며 그 문서에서 다룬 내용은 가능한 언급하지 않겠다. 그 강좌를 이해하고 있다고 가정하고 그 문서에서 다룬 내용 이외에 필요한 중요 몇 가지 내용을 소개 하겠다.
9.5.1 IP주소와 도메인
IP 주소와 도메인은 전혀 상관이 없다. 마찬가지로 호스트명과 IP 주소도 전혀 상관없다. 하나의 호스트명이 여러 IP주소를 가질 수 있고 하나의 IP주소가 여러 호스트명(혹은 도메인)을 가질 수도 있다. 즉 IP주소가 물리적인 번지라면 도메인은 논리적인 번지라고 할 수 있다.
9.5.2 도메인과 존
도메인과 존(ZONE) 은 서로 다른 개념이다. 도메인은 하나의 모든 줄기(예를 들면 a.com아래의 모든 도메인) 라고 할 수 있는데 반해 존은 줄기의 일부분이나 여러 줄기에 걸친 데이터로 생각할 수 있다. 즉 a.b.c.com 도메인 아래 256개 호스트가 있다면 1.a.b.c.com부터 256.a.b.c.com까지 모든 호스트는 이 도메인에 속한 것이다. 하지만 이를 나눠 1.a.b.c.com ~ 100.a.b.c.com까지를 한 존으로, 나머지 101.a.b.c.com ~ 256.a.b.c.com 을 다른 존으로 나누고 이들 존을 각각 다른 네임 서버가 관리하도록 할 수도 있다. 예를 들어 co.kr 도메인의 네임 서버는 다음과 같다고 하자
;;AUTHORITY SECTION:
co.kr. 6H IN NS ns.kornet.ne.kr. co.kr. 6H IN NS kr21d.dacom.co.kr. co.kr. 6H IN NS ns.krnic.net. co.kr. 6H IN NS ns.roucuj.re.kr. co.kr. 6H IN NS ns.kren.ne.kr.
그런데 a.co.kr 은 ns.kornet.ne.kr에서는 발견 되지만 kr21d.dacom.co.kr에서는 발견되지 않는 경우가 있다. 즉 co.kr도메인은 x.co.kr등 모든 하위 도메인을 포함하지만 각 네임 서버는 co.kr의 일부 도메인 데이터, 다시 말해 co.kr 존 데이터를 관리하고 있는 것이다.
9.5.3 BIND 4.x와8.x
BIND는 현재 4.x 버전과 8.x 버전이 함께 관리된다. 하지만 4.X버전에 대한 지원은 앞으로 없어질 예정이므로 새로 네임 서버를 구축한다면 8.x버전을 권한다. 8.x 버전은 4.x버전 보다 많은 기능이 추가되었고 설정이 편하며 보안 문제에 대한 대책이 많기 때문이다. 4sx버전은 8.x 버전으로 이전하기 위해 새로 바뀐 설정 파일에 맞게 데이터를 변경하는 작업이 어려워 여전히 4.x버전에 머무르는 사이트를 위한 관리 버전이다. 물론 아직도 많은 사이트가 4.x버전을 사용하고 있다는 것도 하나의 이유가 될 것이다. 참고로 레드햇 리눅스 6.0과 이를 기 반으로 하는 한글 배포 본은 모두 8.x버전으로 사용하고 있다.
이제 MY.com을 설정하도록 하자. 회사에는 몇 대의 리눅스 서버가 있으며 (1대라도 상관없다.) 빈번하게 호스트가 달라지므로 서버의 간단한 변경 사항이 인터넷에 전파되기를 원하고, 이를 위해 네임 서버를 만들고자 한다. 번번하게 네임 서버를 사용하는 서버를 위해 캐싱 전용 네임 서버도 두기로 했다. 회사명에 따라 My.com과 My,co,kr모두 신청해 사용자가 my만 기억하면 모두 접속 할 수 있도록 했다.
my.co.kr 을 신청하기 위해 http://www.krnic.net 에 접속하면 된다. 6월까지는 도메인 신청을 WSP4와 ISP 자격을 가진 업체만 가능하지만 pe.kr도메인의 공개와 함께 co.kr도메인도 누구나 신청할 수 있다. 대신 무료로 사용할 수 있던 것과 달리 이제는 유료로 바뀌었다. 이 사이트에서 링크를 따라가며 신청서를 작성하면 1~2일 내에 등록이 완료된다. 신청 과정에서 인증키가 필요한데, 전자메일을 받을 계정을 입력하면 신청서를 작성하는 동안 전자 메일로 보내진다. 인증 키를 제대로 처리하면 어려운 일은 없을 것이다. 신청이 끝난 후 접수 번호가 주어지는데 이것을 잘 적어놔야 한다. 나중에 도메인 등록 진행 상황을 보는데 필요하다. 도메인 등록 진행 상황 은 http://domain.nic.or.kr/status에서 알아볼 수 있다. my.com은 미국 사이트에 신청해야 한다. com 도메인을 신청하는 회사가 미국 회사이어야 한다는 특별한 규제는 없다. 등록을 받는 사이 트 가 많 지 만 필 자 가 아 는 곳 은 http://www.networksolutions.com 이다. 여기서 my.co.kr 등록과 비슷한 방법으로 링크를 따라가면 되며 마찬가지로 유료이다. 영어로 되어 있으니 영문을 주의 깊게 읽고 신청 절차를 밟는다면 큰 어려움이 없을 것이다. 주의할 점은 도메인 관리자를 정할 때 회사를 떠날 확률이 거의 없는 사람을 선택해야 한다는 것이다. 신청을 완료한 후 돠메인에 필요한 정보를 바꿀 때는 이 사람만이 가능하기 때문이다. 물론 직접 사람을 확인 하는 것은 아니고 전자 메일 주소를 이용하지만 회사를 떠날 가능성이 많은 사람을 관리자로 정하면 나중에 복잡한 일이 발생할 수도 있다. 이 것은 com과 co.kr모두에 해당되는 사항이다.
9.6.2 네임 서버 프로그램의 설정
#mount /dev/cdrom /mnt #rpm -ivh /mnt/redhat/rpms/bind-8.2.6.1386.rpm #rpm -ivh /mnt/redhat/rpms/bind-utils-8.2-6.i386.rpm
설정 파일은 /etc/named.conf인데 이 파일에서 나머지 설정을 조정할 수 있다. rpm패키지를 사용하는 것이 마음에 들지 않는다면 http://www.isc.org에서 소스 코드를 가져와 컴파일 해도 된다. 컴파일 방법 등에 대한 것은 해당 소스 트리를 참고할 것.
options { directory "/var/named" check-names master warn; /* defauit. */ datasize 20; }; ///////////////////////////////////////////////// zone "." IN{ type hint: file "root.hint"; }; ///////////////////////////////////////////////// zone"loca1host" IN{ type master; file "localhost"; check-names fail; allow-update{ none;}: allow-transfer { any; };
/etc/named.conf의 options항목에는 여러 가지 선택 사항을 만들 수 있다. 자세한 내용은 소스 트리의 설명을 참고하기 바란다. "."은 인터넷 최상위 도메인을 지칭하는 것으로, 모든 도메인의 루트 도메인이다. localhost는 네임 서버 자체의 호스트명이며, zone에서는options와같이 개별적인 존에 따른 옵션을 선택할 수 있다.
42 ; serial (d. adams) 3H ; refresh 15M ; retry 1M ; expiry
XXX 11 11:11:11 XXX NAMED[6082]: ZONE "LOCALHOST" (FILE NS.MY.COM): NO DEFAULT TTL SET USING SOA MINIMUM INSTEAD
nameserver 127.0.0.1 nameserver 168.126.36.1 nameserver 164.124.107.9
9.6.4 로컬 네트웍에 대한 네임 서버
options { directory "/var/named"; check-names master warn; datasize 20M;
}: ///////////////////////////////// zone "." IN { type hint; file "root.hint"; }; ///////////////////////////////// zone "localhost" IN { type master; file "localhost"; check-names fail; allow- update { none; }; allow- transfer {any; }; }; /////////////////////////////////// zone "my.com: IN { type master; file "my.com"; check-names fail; allow- update {none;}; allow- transfer {any}; }; zone "my.co.kr" IN { Type master; file "my.com"; check-names fail; allow-update { none; } ; allow-transfer { any;} ; };
그리고 /var/named/my.com은 다음과 같다.
@ 10 IN SOA ns.my.com. root.ns.my.com. (
1D IN A 1.2.3.4. 1D IN NS ns 1D IN MX 10 mail localhost 1D IN A 127.0.0.1 gate 1D IN A 1.2.3.1 ns 1D IN A 1.2.3.2 www 1D IN cname ns mail 1D IN A 1.2.3.3 ftp 1D IN A 1.2.3.4
설정이 끝나면 다음 명렁을 실행한다. 네임 서버는 한 번 질의받은 호스트명에 대한 내용을 메모리에 저장하므로 일단 서버가 동작 중이라면 가능한 다시 시작하지 않는 것이 좋다. 네임 서버를 다시 시작하기 위해 종료하며 캐시를 모두 버리기 때문에 재기동한 후 일정 기간동안 질의가 들어올 때마다 호스트를 찾기 위해 인터넷을 뒤지기 때문이다. 그러므로 로컬의 zone 파일을 고쳤다면 캐시를 폐기하지 않고 설정 파일만 다시 읽어 들이도록 하는 것이 좋다.
# killall -HUP named
제대로 되었는지 확인하려면 리눅스에서 nslookup 명령을 내려보기 바란다.
#nslookup -type=soa my.com ns.my.com
제대로 응답하고 그 결과가 my.com의 내용과 차이가 없으면 원하는 대로 설정된 것이다. 다음 명령으로 네임 서버가 관리하는 호스트 데이터에 이상이 없는지 알아볼 수 있다.
#host ns.my.com
윈도우라면 네임 서버를 이 설정을 가진 네임 서버가 아닌 168.126.63.1 등으로 맞추고 my.com에 대한 질의를 할 수 있을 것이다. 윈도우에서 로컬 네임 서버를 직접 사용하도록 설정하면 인터넷에서 보이지 않아도 로컬에서는 바뀐 내용을 볼 수 있으므로 테스트 중인 데이타를 보게 될 위험이 있다. 때문에 단순 클라이언트 윈도우의 네임 서버는 외부로 맞춰 놓을 필요가 있다. 그외 각 필드에 대한 자세한 설명은 생략한다. RTFM!!
9.7 네임 서버 설정에서의 주의할 점
www 1D IN A 1.2.3.4 ftp 1d2h33m2s IN CNAME 1.2.3.5
원한다면 다음과 같은 생략형을 사용할 수 있다.
ns IN A 1.2.3.6 mail A 1.2.3.7
mail A 1.2.3.7 처럼 가장 단순한 형태도 통용되지만 실은 대단히 게으르고 위험한 방법이므로 가능하면 완전한 형태를 갖춰 사용하기 바란다. 표준에 의하면 3com.com, 012.sktelecom.co.kr 처럼 숫자로 시작하는 (숫자로만 된 111.com 같은 경우 포함) 도메인이 가능한 상태인데, 문제는 이런 숫자 필드를 zone파일에서 호스트(도메인) 명의 일부인지 TTL값인지 구별할 방법이 애매하다는데 있다. 다음과 같은 y.com의 일부를 생각 해 보자
012 1D IN A 1.2.3.4 012 IN NS 1.2.3.4 012 NS 1.2.3.4
첫째는 012.my.com 이라는 호스트명임을 알 수 있지만, 둘째는 012가 필드의 TTL값인지 012.my.com도메인의 네임 서버가 1.2.3.4.인지 확인할 방법이 없다. 물론 셋째도 마찬가지다. 현재 네임 서버 zone 파일 파서는 하나의 레코드가 공백으로 시작하는지 여부로 모든 것을 판단한다. 즉 앞의 데이터를 다음과 같이 만들었을 때 정상적인 인식이 가능하다.
012 1D IN A 1.2.3.4 012 IN NS 1.2.3.4 012 NS 1.2.3.4
9.7.2 Sendmail과 네임 서버
feature (accept_unresolvable_domains)
sendmail 설정 파일. M4 사용법에 대해서는 해당 문서를 참고하기 바란다.
9.8 대용량 네임서버
…………… ////////////////////// zone "1.com" IN { type master; file "common.zone"; check-names fail; allow-update { none; }; allow-transfer { any; }; }; /////////////////////////////////
zone "2.net" { type master; file "common.zone"; check-names fail; allow-update { none; }; allow-transfer { any; }; }; //////////////////////////// zone "500.org" IN { type master; file "common.zone"; check-names fail; allow-update { none; }; allow-transfer { any; }; }; 그리고 /var/named/common.zone을 이에 맞게 설정한다.
@ 1D IN SOA ns.my.com. root.ns.my.com. ( 8H 2H 1W 1D) 1D IN A 1.2.3.4 1D IN NS ns.my.com. 1D IN MX 10 mail.my.com. www 1D IN CNAME @ ftp 1D IN CNAME @ mail 1D IN CNAME @
@ 1D IN SOA ns.my.com. root.ns.my.com. { 199811251 8H 2H 1W 1D) 1D IN A 1.2.3.4 1D IN NS ns.my.com. 1D IN MX 10 mail.my.com. www 1D IN CNAME @ * 1D IN A 1.2.3.4
9.8.3 대규모 질의에 대한 대책
options { directory "/var/named": check-names master warn: /* default. */ Forwarders { 168.126.63.1; 164.124.107.9; };
};
9.8.4 캐시된 데이터
9.8.5 네임 서버 다운에 대한 대책
#crontab-e
다음의 named를 확인하는 쉘 프로그램 (/root/bin/chech_named)이다
#!/bin/sh
/etc/rc.d/init.d/named stop /etc/rc.d/init.d/named start
#dig alzzalinux.com soa in
이에 대한 출력 결과는 다음과 같다
: <<>> DiG 8.2 <<>> alzzalinux.com soa in ;; res options: init recurs defnam dnsrch ;; got answer: ;; ->>header<<- opcode: QUERY, status: NOERROR, id:6 ;; flags: qr rd ra: QUERY: 1, ANSWER: 1, AUTHORITY 2, ADDITIONAL: 2 ;; QUERY SECTION ;; alzzalinux.com, type = SOA, class = IN ;; ANSWER RECTION: alzzalinux.com. 12h30m47s IN SOA ns.alzzalinux.com. root.alzzalinux.com. { ;; AUTHORITY SECTION: alzzalinux.com. 13h57m29s IN NS ns.wdb.co.kr. alzzalinux.com. 13h57m299s IN NS ns.alzzaIlinux.com.
ns.wdb.co.kr. 1h11m20s IN A 210.108.24.201 ns.alzzalinux.com. 13h15m35s IN A 201.182.137.58
;; FROM: xxx.xxxxxxx.com to sever: default ? 111.111.111.1 ;; WHEN: xxx xxx 11 11:11:11 1111 ;;MSG size sent: 32 rcbd: 148
; (1 sever found) $ORIGIN alzzalinux.com. @ 1D IN SOA ns root { 12H ; refresh 1H ; retry 2W ; expiry 1D ) ; minimum 1D IN NS ns 1D IN NS ns.wdb.co.kr. 1D IN MX 10 mail 1D IN A 210.182.137.58 mail2 1D IN A 210.182.137.58 obiwan 1D IN A 210.182.137.58 mail 1D IN A 210.182.137.58 www 1D IN CNAME obiwan ftp 1D IN A 210.182.137.58 ns 1D IN A 210.182.137.58 @ 1D IN SOA ns root ( 1999071502 ; serial 12H ; refresh 1H ; retry 2W ; expiry 10 ) ; minimum ;; received 12 answers ( 12 records) ;; FROM: xxx.xxxxxxx.com to sever: 210.182.137.58 ;; when: xxx xxx 11 11;11;11 1111
여기서 alzzalinux.com 아래에는 mail2,obiwan, ftp, ns가 있음을 알 수 있고 www는 obiwan의 CNAME임을 알아낼 수 있다. zone 파일을 설정에 어려움을 느낀다면 모범적인 사이트의zone데이터를 가져다 자신에게 맞게 고쳐도 될 것이다. 사실 zone데이터를 전송하는 것은 장려할 만 하지 않지만 필자가 작업한 검색 엔진용 dnsrobot 프로그램도 이 방식으로 Kr 아래의 모든 도메인을 검색하면서 호스트 명을 모으도록 되어있다. 따라서 개인적으로는 특별한 문제가 없다면 zone 전송을 막지 않았으면 한다.
9.11 이달의 숙제
2008년 추가: 드림위즈 블로그에서 티스토리 블로그로 옮김. 이 글을 하나 짜리 통 파일로 만들었기 때문에 이 마지막 글을 볼 사람은 극히 드물 것으로 생각된다. 이 문장을 읽는 사람에게 행운이 있기를! 기술도 능력도 미움도 절망도 모두 함께 뭉뚱그려진채 미래로만 나아가는 것이 인생인 듯, 내일은 또 다시 새로움을 향해 달려가야 한다. 아아, 나는 지금 어디에 서 있는 것일까?
김인성. |










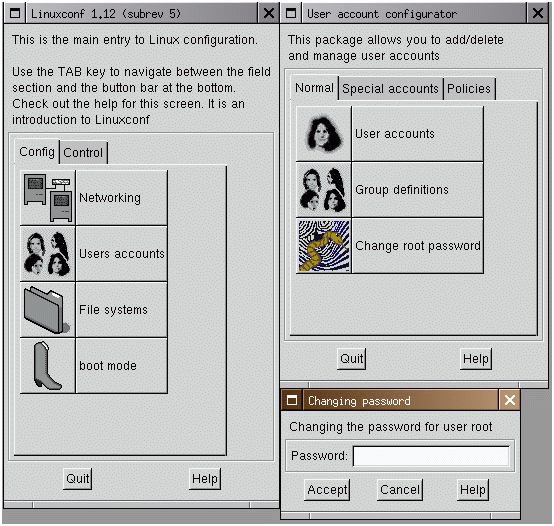




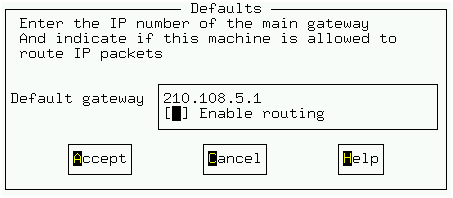
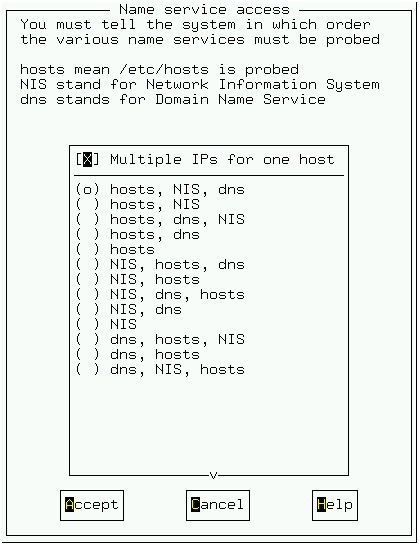

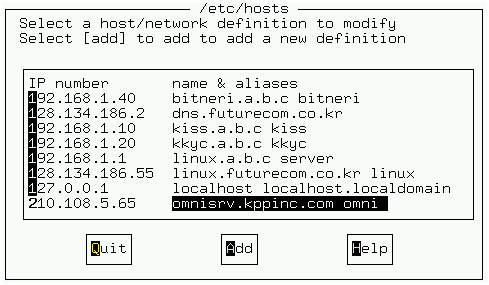
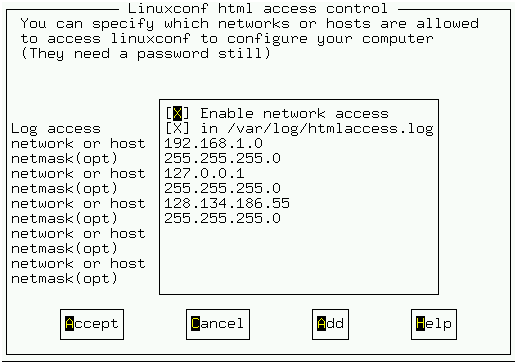

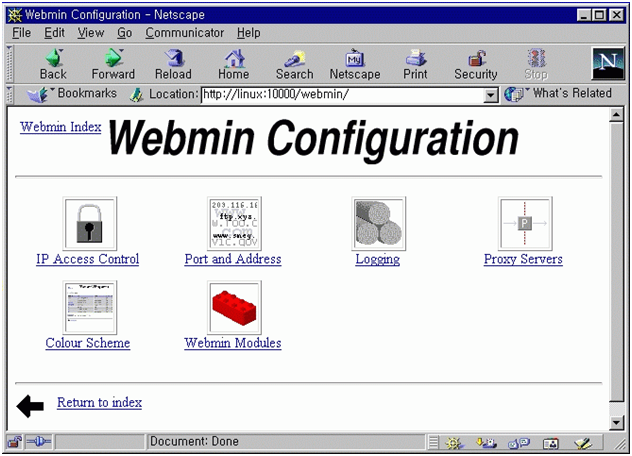
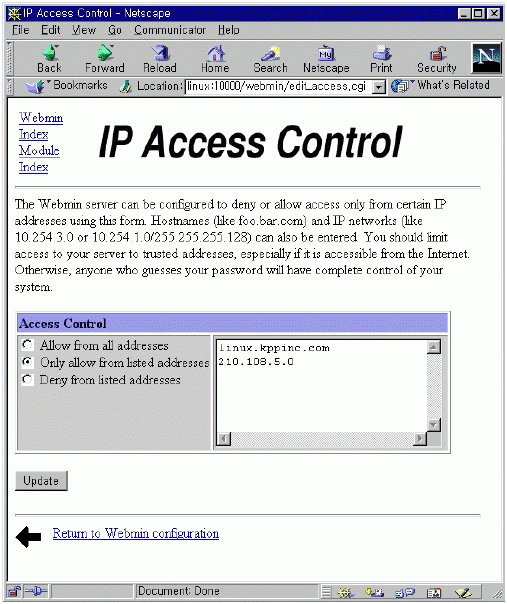
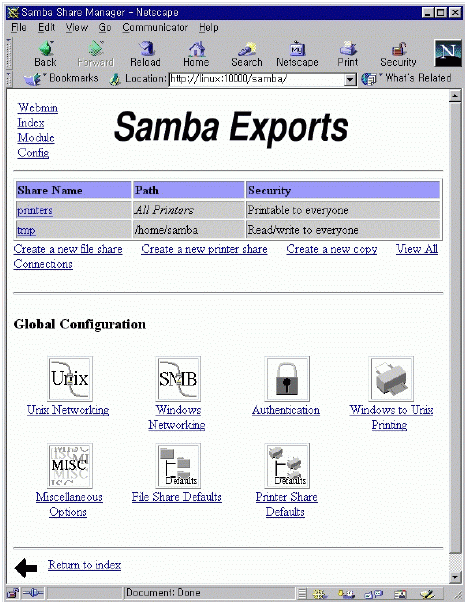
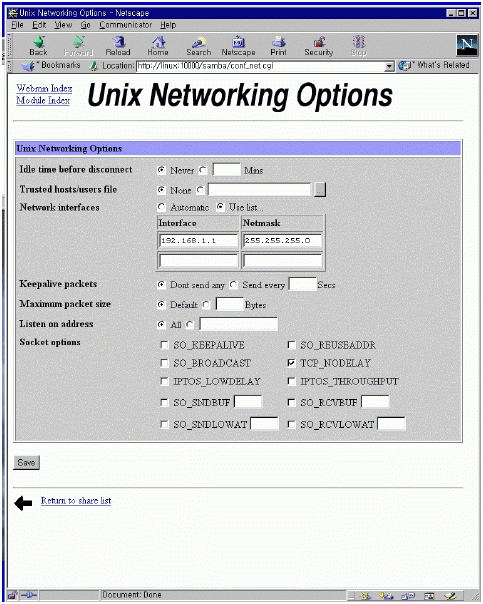
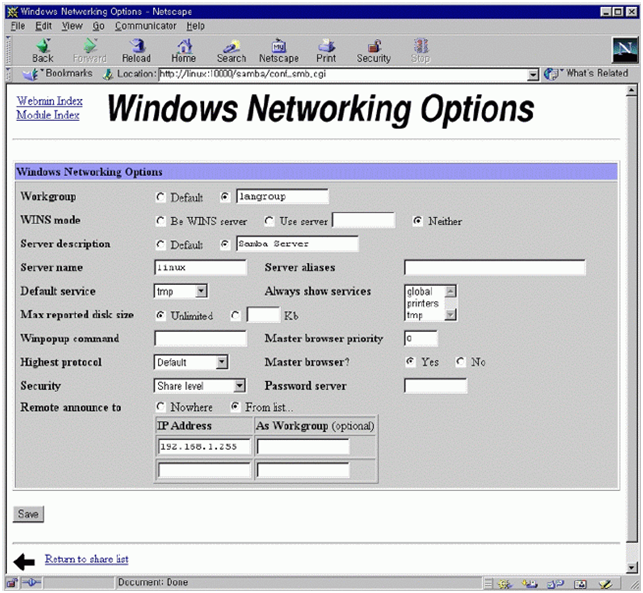
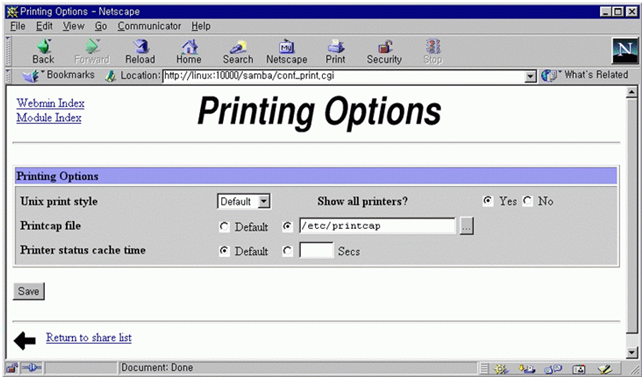
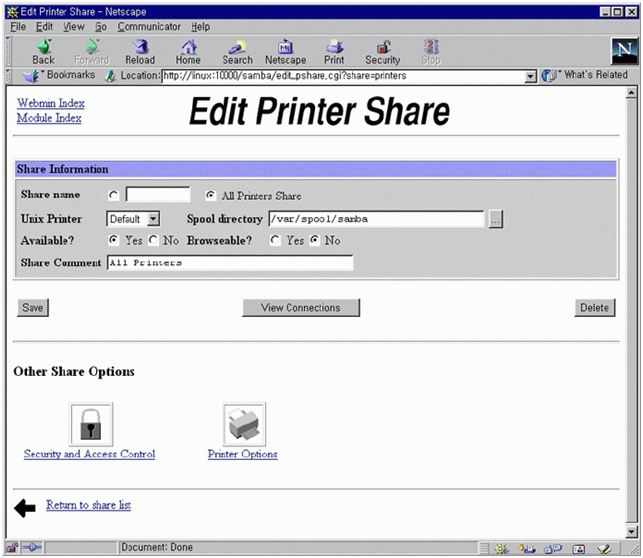
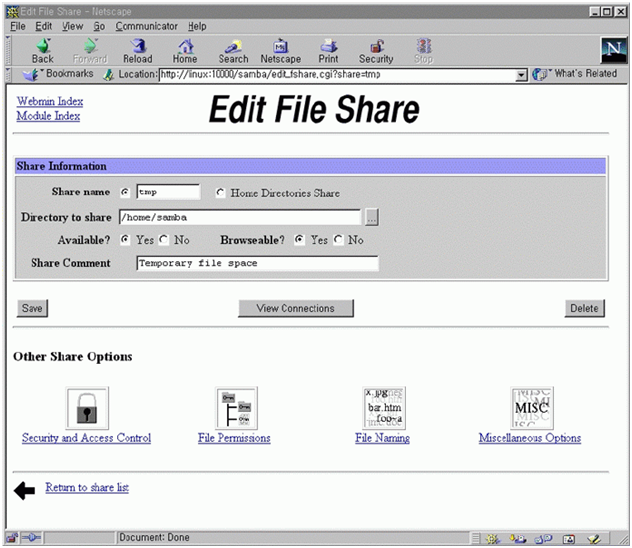
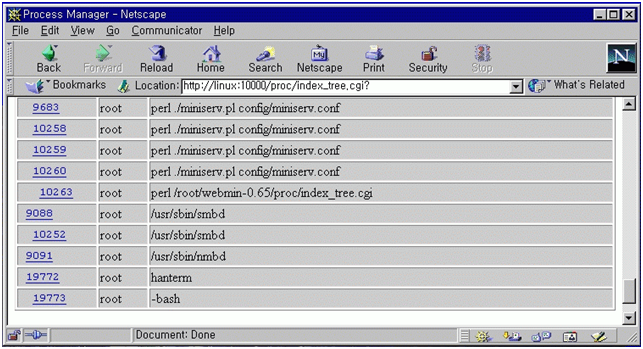
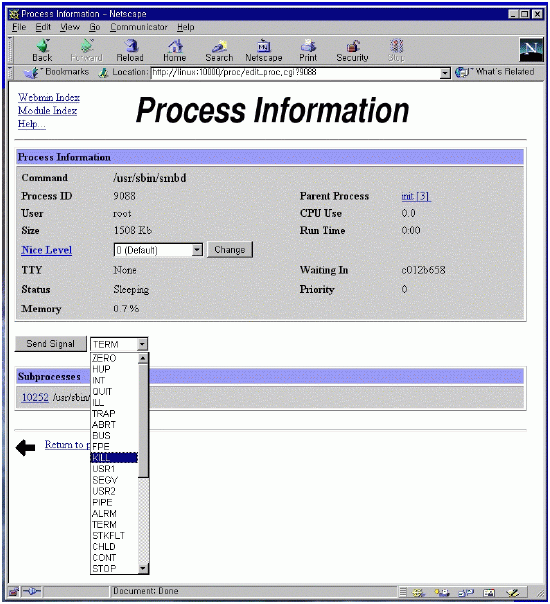
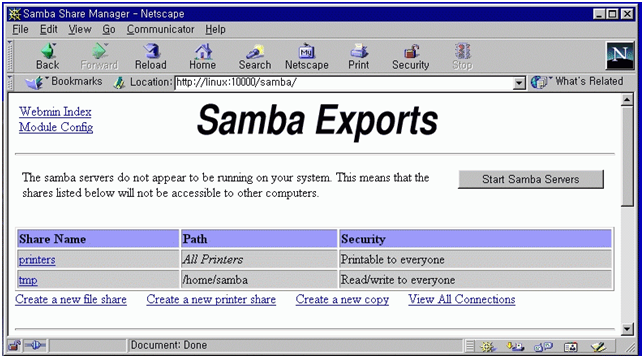
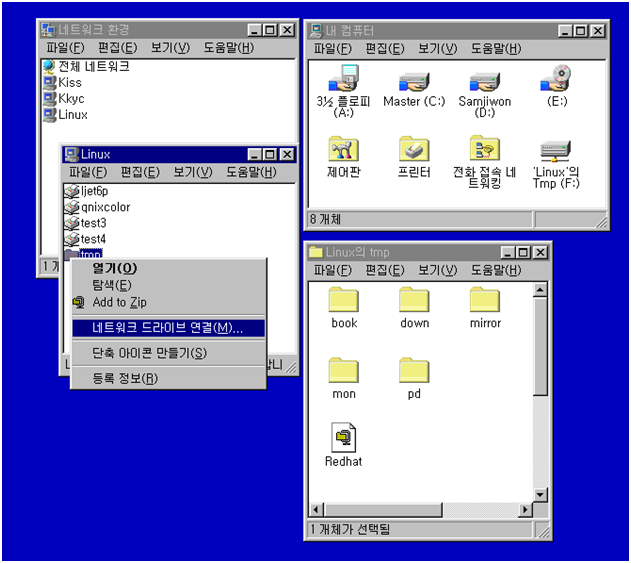
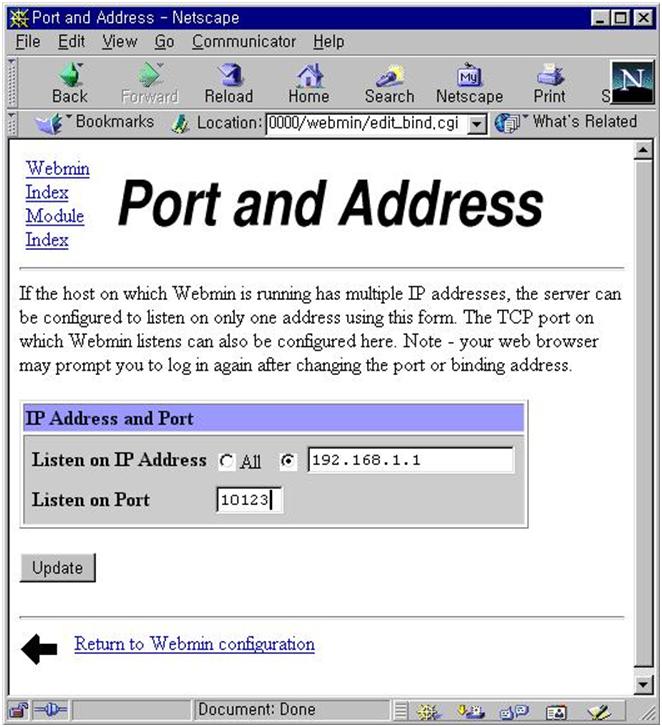
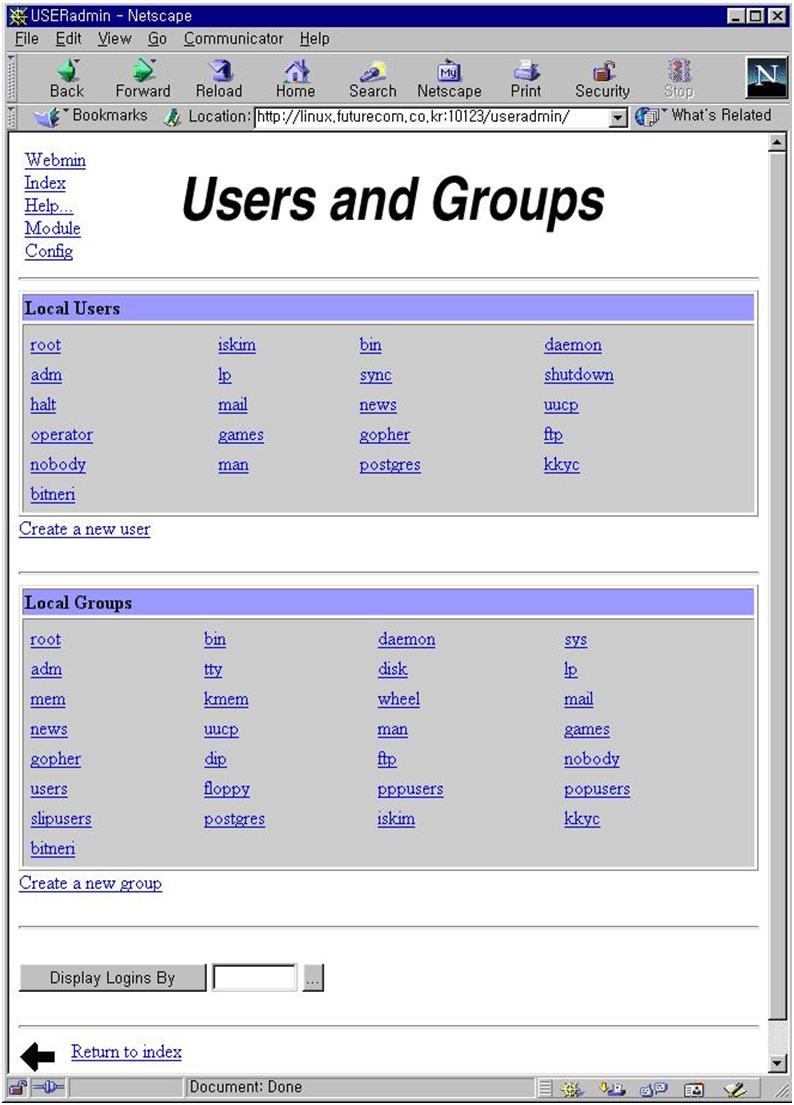
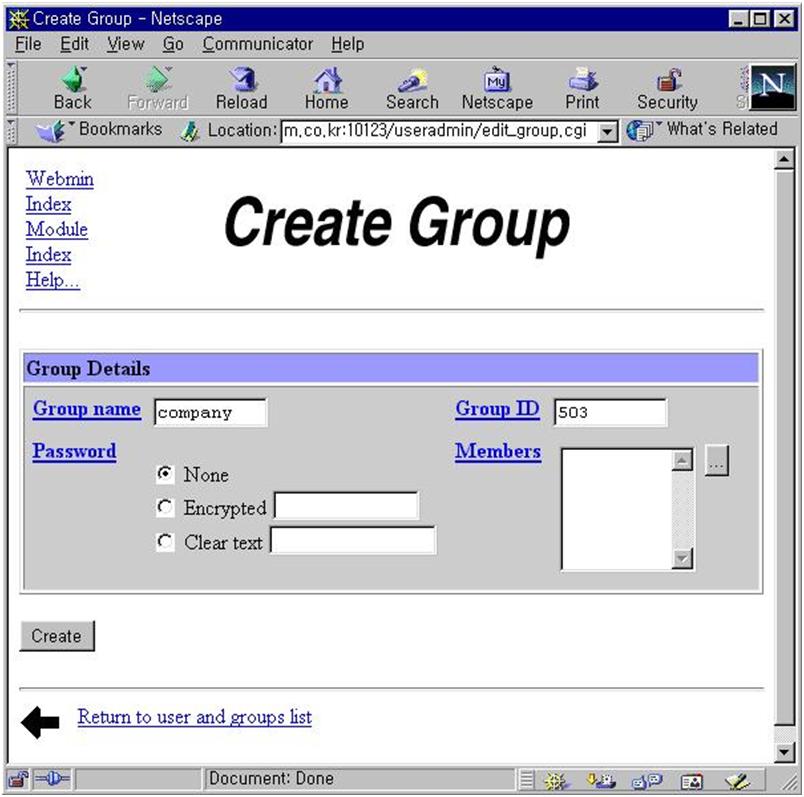
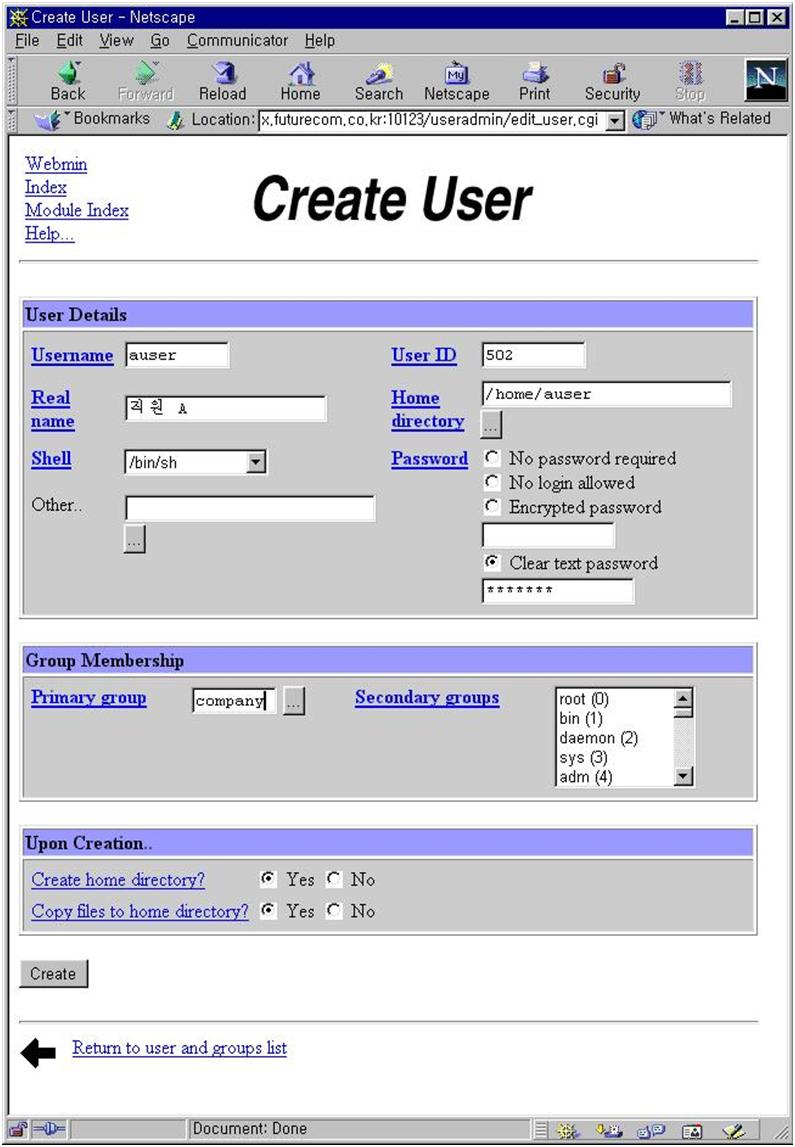

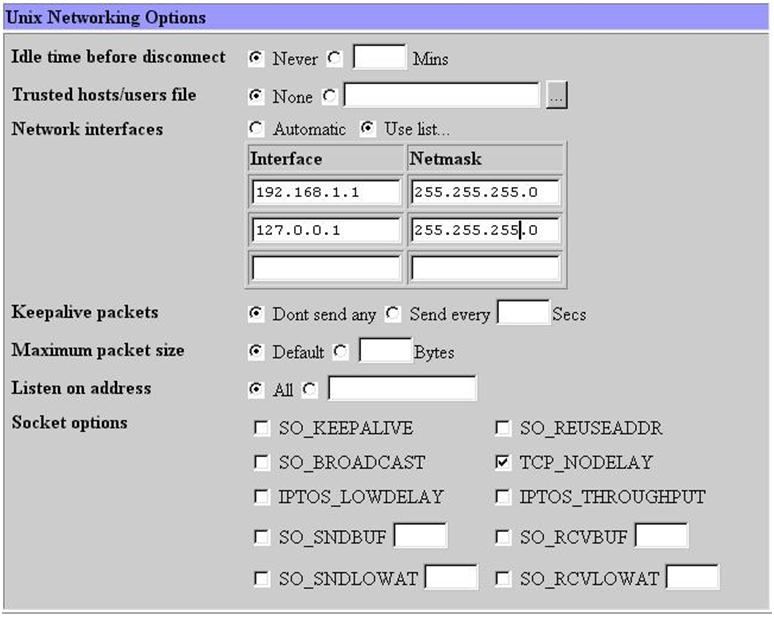
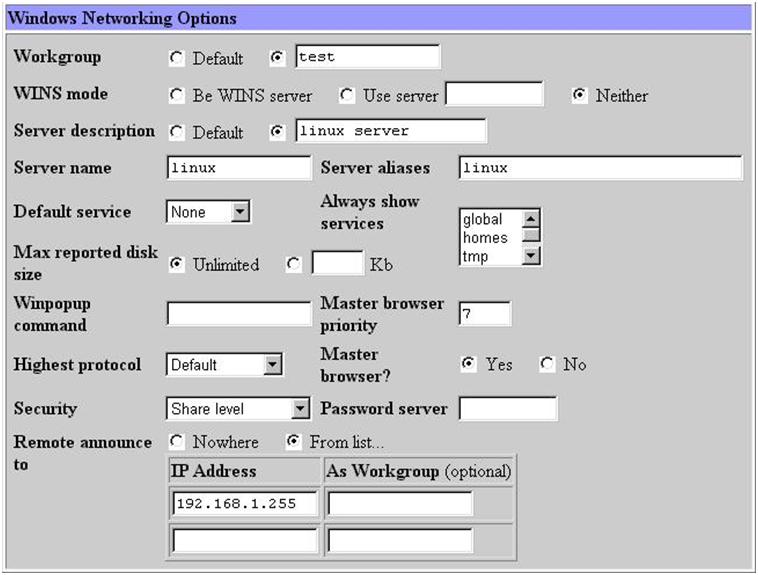


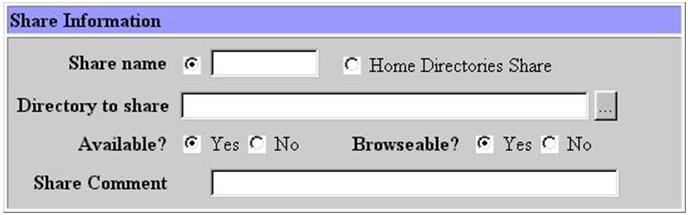
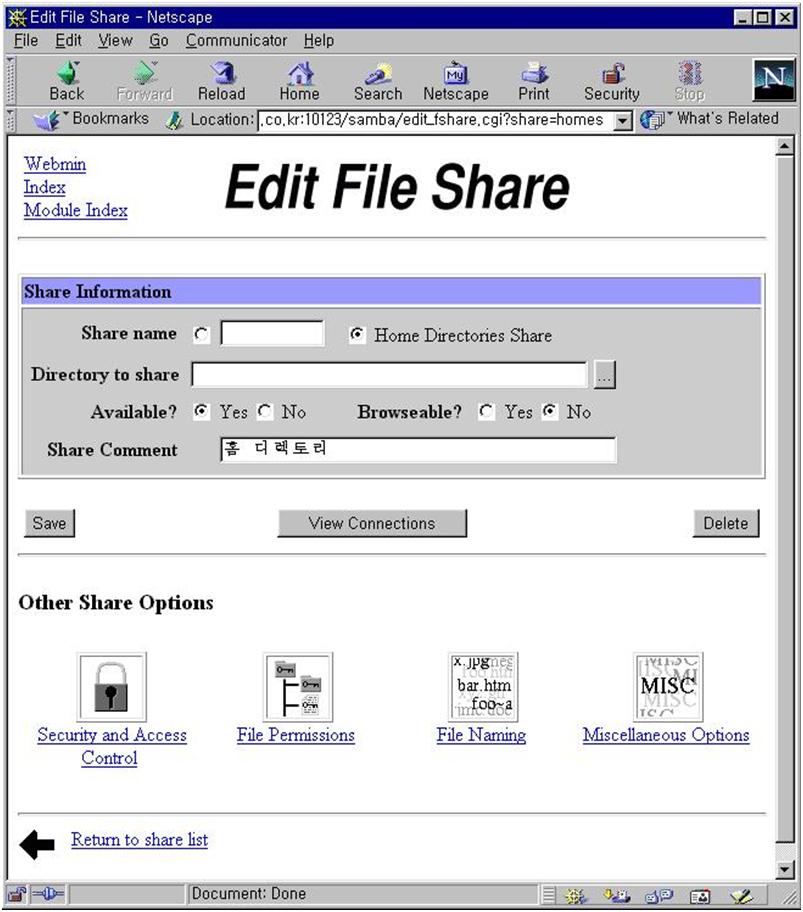
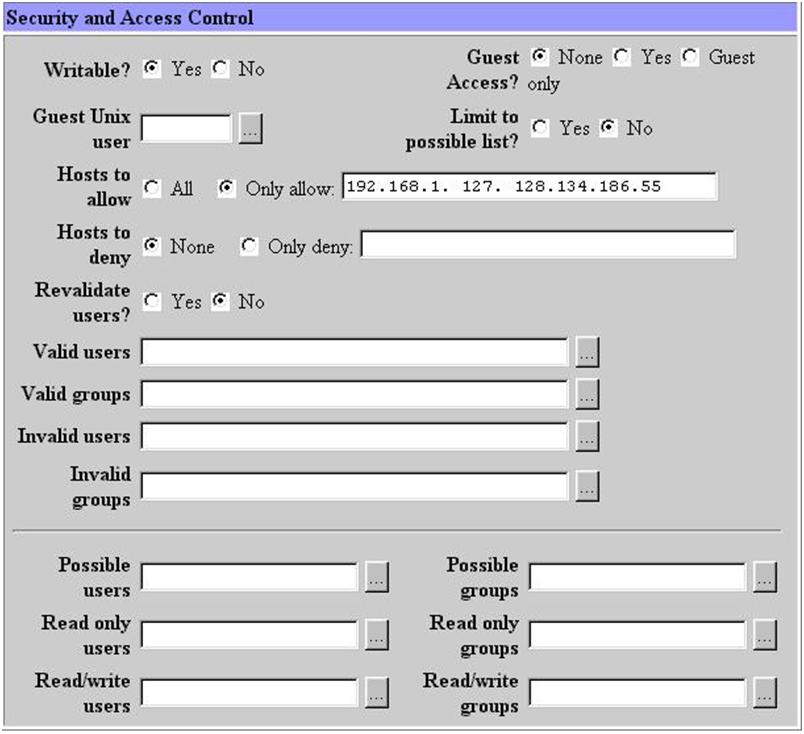
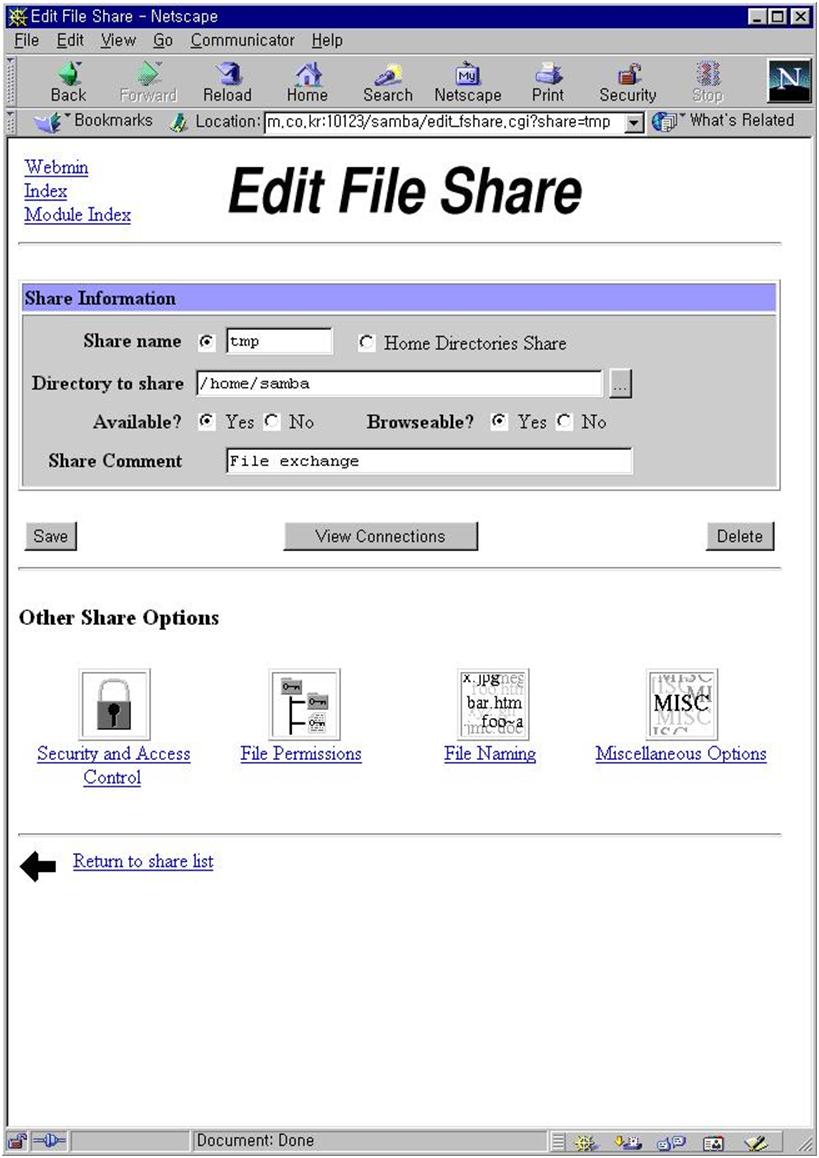
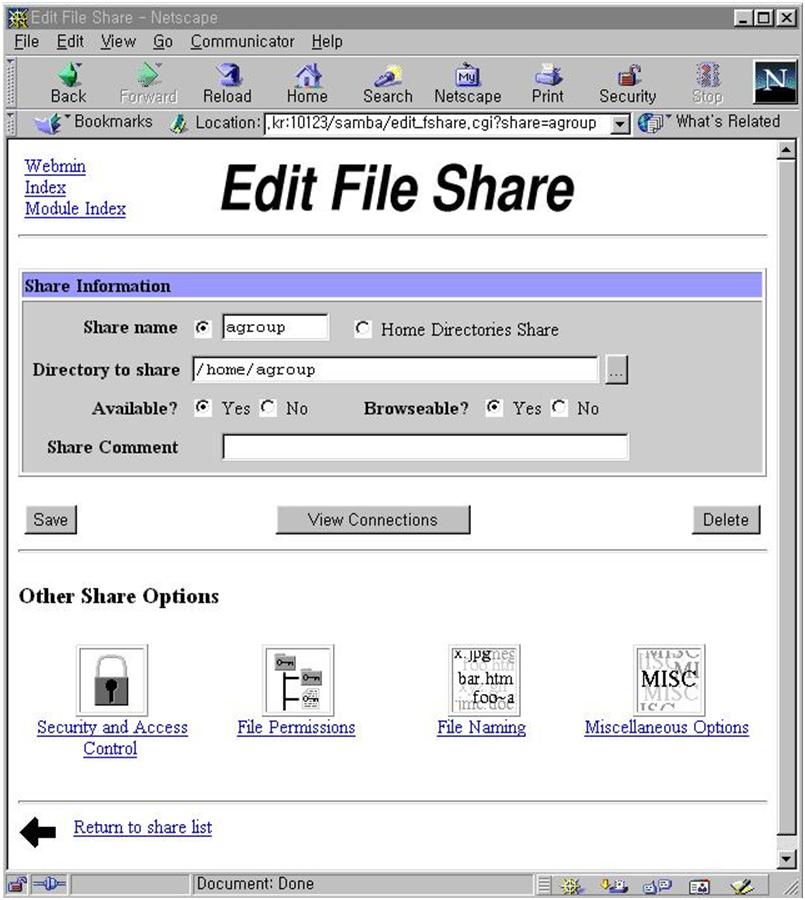
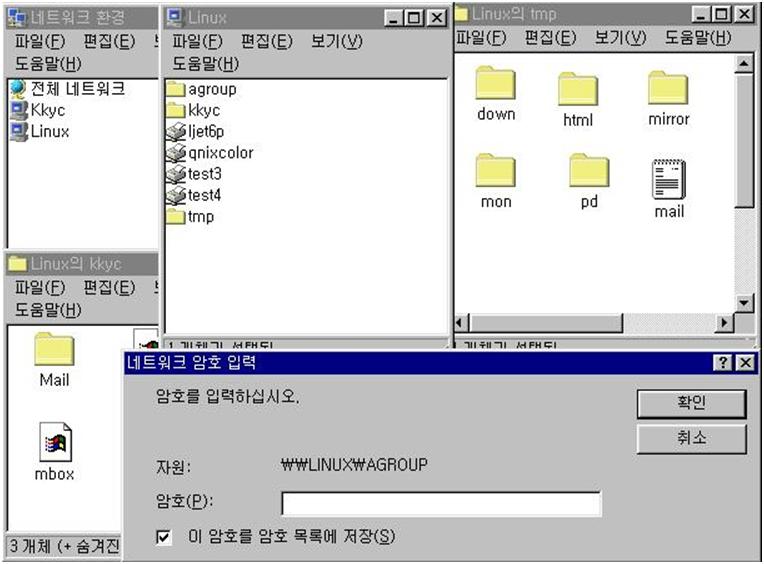
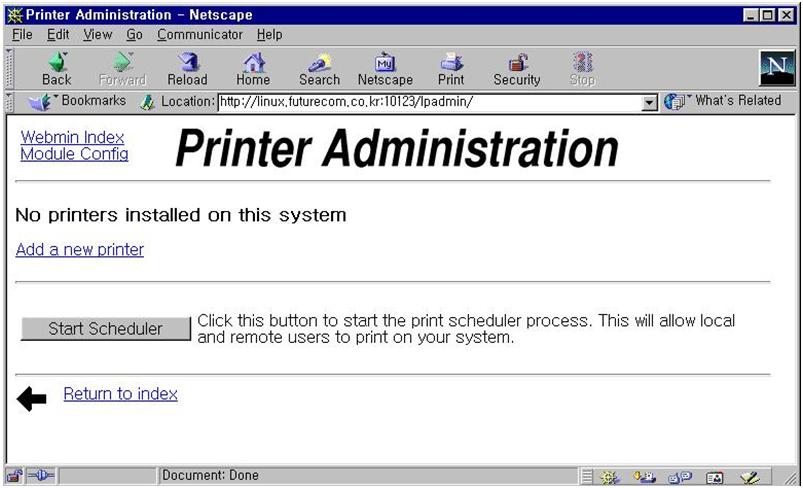
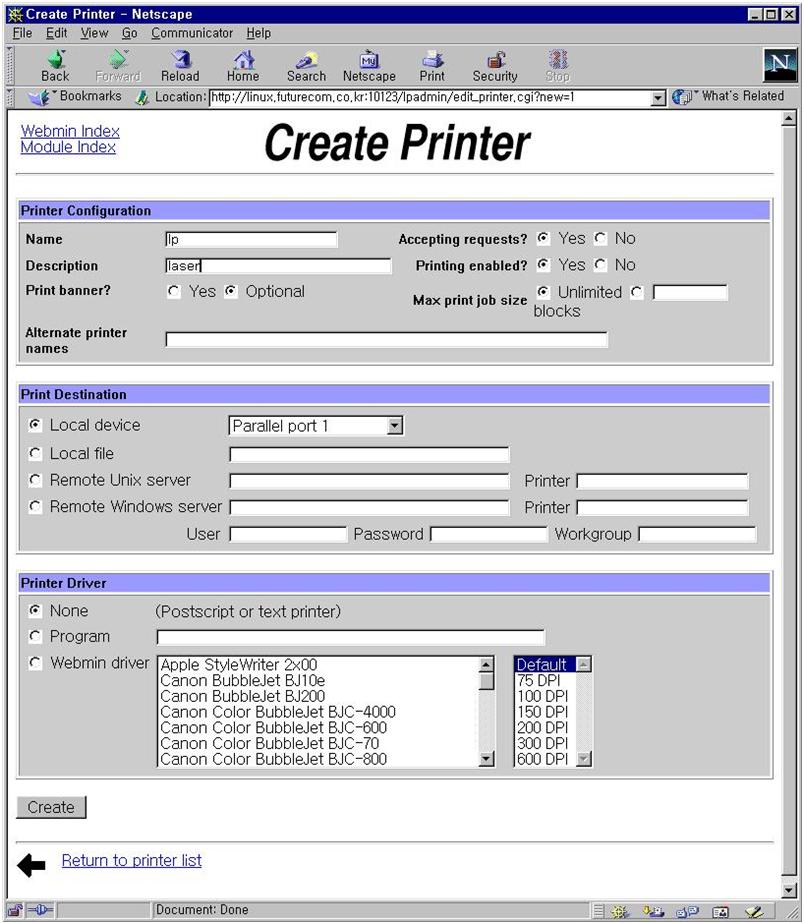
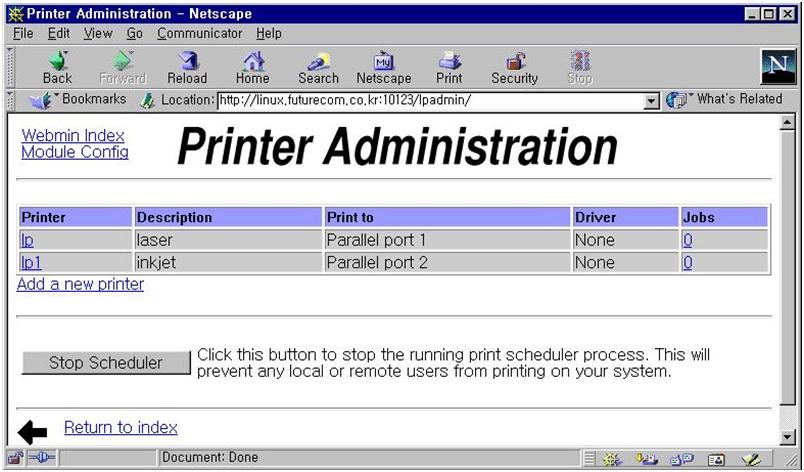
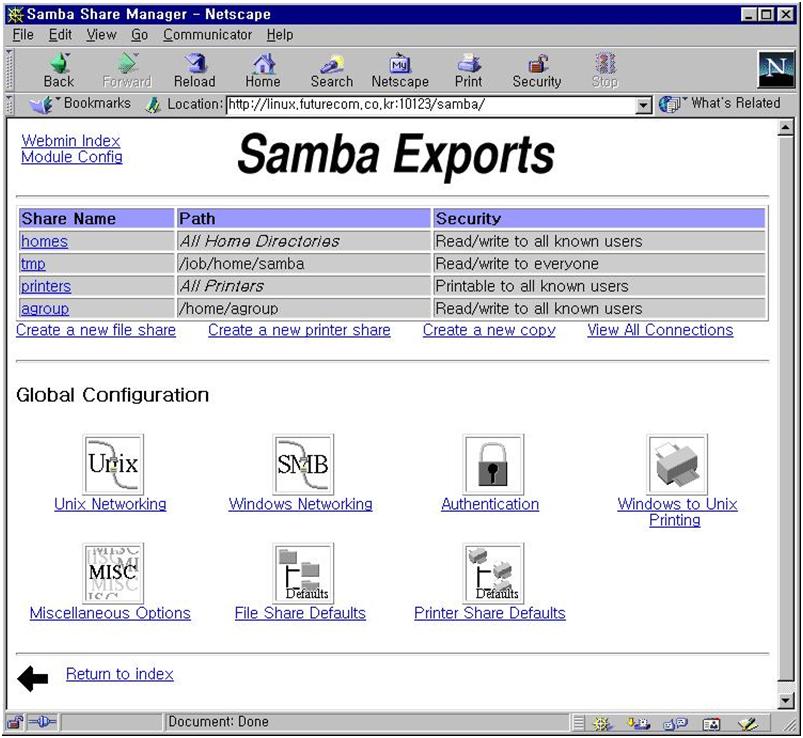
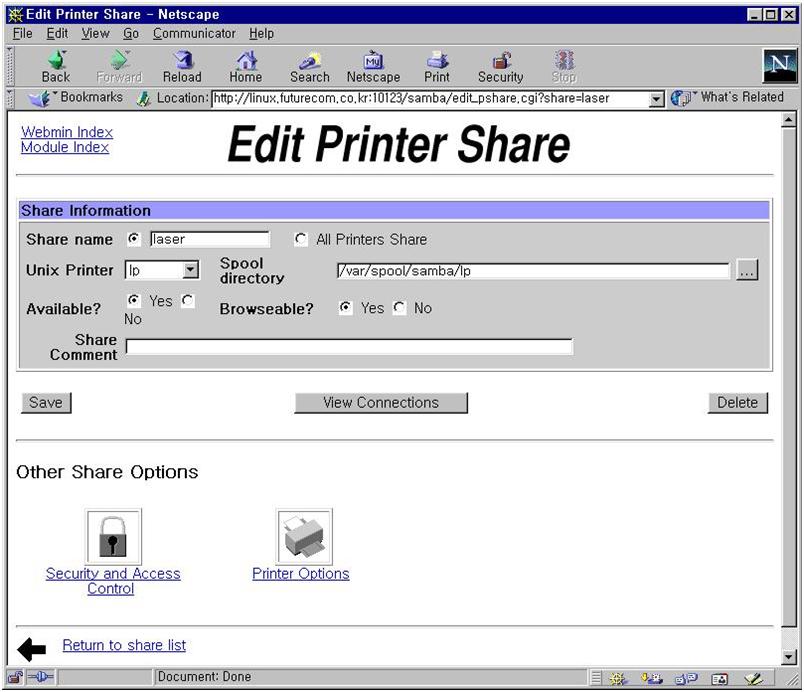
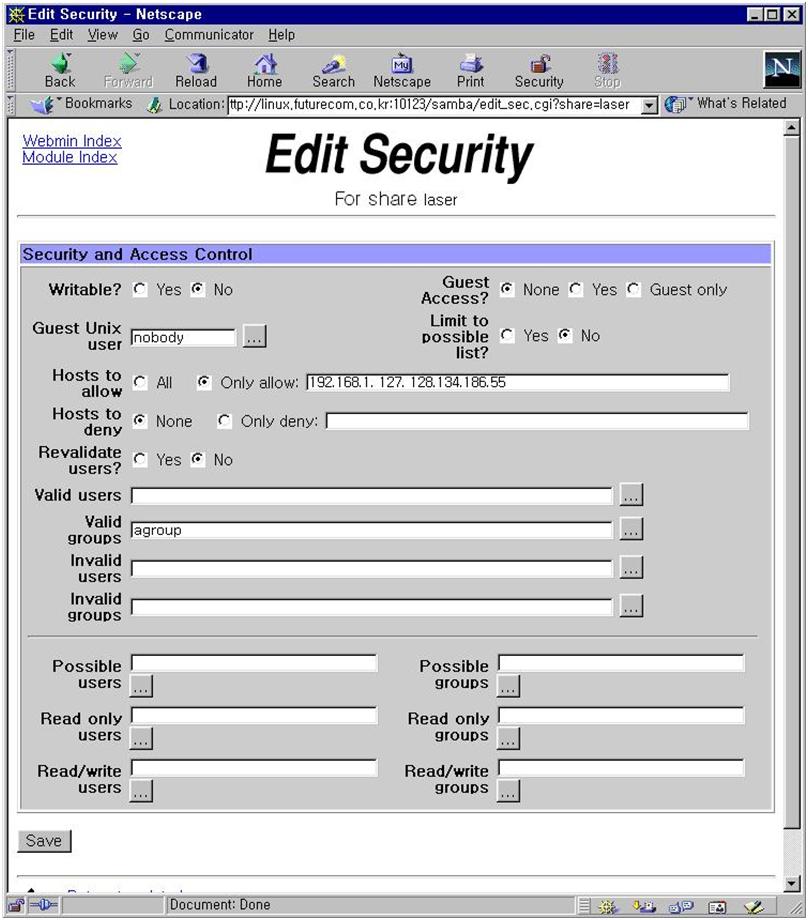
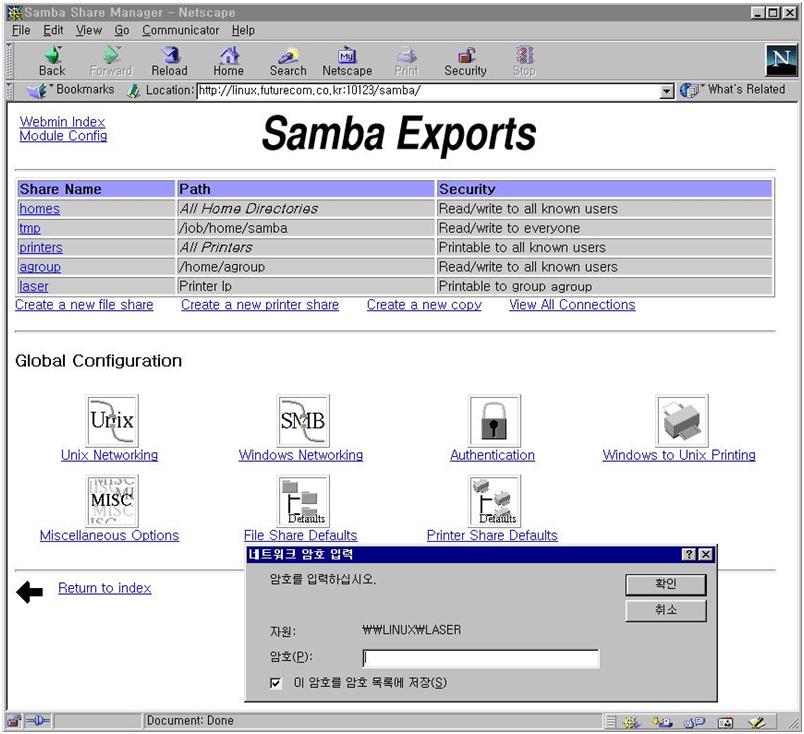
 화면 10 : 윈도우위의 엑스 메니저
화면 10 : 윈도우위의 엑스 메니저
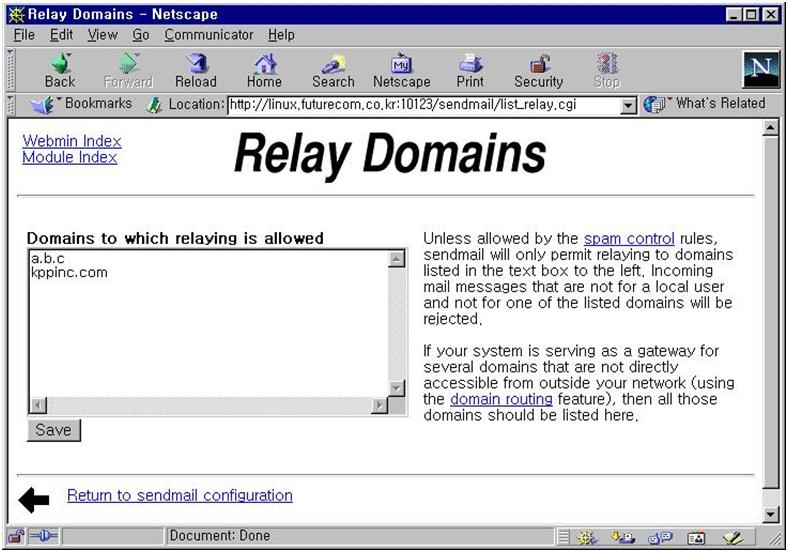
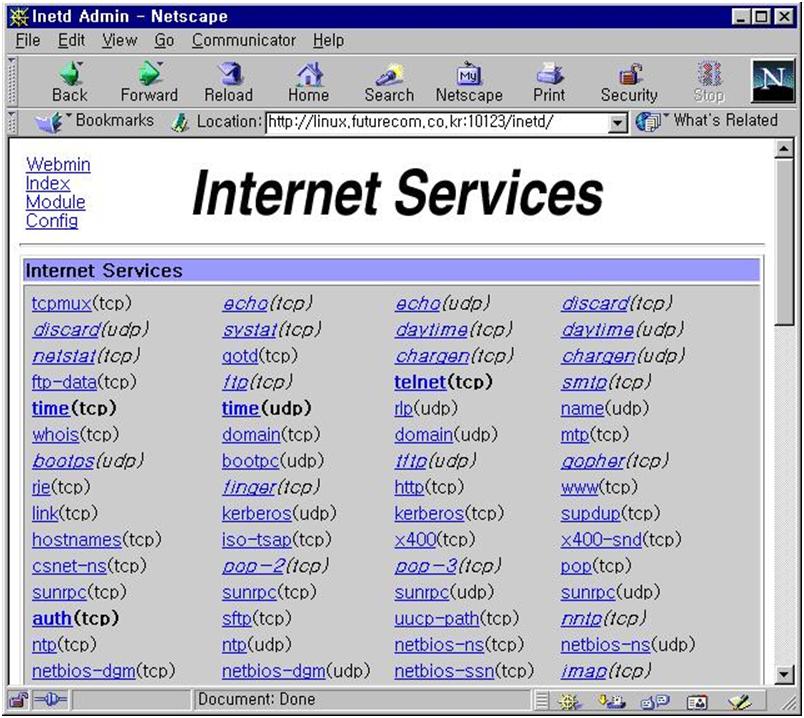














'기술과 인간 > IT로 본 세상' 카테고리의 다른 글
| 짱깨에 대한 인식을 바꾸게 만든 한마디 (6) | 2019.01.24 |
|---|---|
| 중소기업 텔레비전 구입, 그 후 (2) | 2018.06.26 |
| 물어야만 하는 질문 (8) | 2013.05.15 |
| 유시민은 범죄자다 (67) | 2013.04.01 |
| 2009년 10월, 남조선과 북괴의 차이점들 (2) | 2009.10.14 |
| 시스템 엔지니어 (10) | 2008.09.15 |
| 리눅스 디바이스 드라이버 만들기 (0) | 2008.09.15 |
| 리눅서는 어떻게 크는가? (2) | 2008.09.15 |
| 티벨리 언덕에서 -- 까탈박을 위하여 (3) | 2008.09.15 |
| 오픈소스 모델과 한국적 상황 (1) | 2008.09.15 |