미닉스의 작은 이야기들
점점 더 개 쓰레기가 되어 가고 있는 네이버 본문
한민족은 유구한 기록 문화를 가지고 있습니다.
고려의 팔만 대장경과 조선의 조선왕조실록은
한민족이 세운 국가 역시
깊은 철학에 바탕하고 있음을 보여 줍니다.
물론 일제 강점기 이후
역사 청산이 제대로 이루어지지 않아
친일파가 득세한 대한민국은
이런 전통과 단절되어 있습니다.
명박이가 하드디스크를 망치로 깨부수고,
ㄹ혜가 문서 파쇄기로
모든 서류(범죄 증거)를
신나게 잘라 버릴 수 있었던 것이 이 때문입니다.

네이버 트렌드 연감 2008년 머리말
네이버도 마찬가지입니다.
네이버는 "네이버 트렌드 연감"이란 책을 만들고
이를 pdf 파일로 무료 배포를 했습니다.
네이버는 "네이버 트렌드 연감"을 만들면서
"조선왕조 실록과 같은 가치를 가진 책을 만들었다"고
자랑했지만,
이 자료가 검색 조작의 증거로 사용되자
다운로드 링크를 제거하더니,
10년이 지나기도 전에
무료로 제공하던 pdf 파일 자체를
아예 삭제해 버렸습니다.

그 뿐만 아닙니다.
인터넷의 데이터는 시간에 따라 달라지기 때문에
매 시기마다 그 상태를 저장해 놓을 필요가 있습니다.
이 기록이 쌓이면 역사가 되기 때문입니다.
이미 1990년대 초반부터
인터넷의 역사에 대해 관심을 가지고
기록 작업을 한 사이트가 있습니다.
http://archive.org 란 사이트가 그 곳입니다.

이 사이트에서는
검색할 수 있는 거의 모든 사이트에 대해
매년, 매월, 매일, 매 시간
웹 페이지를 가져가서 저장해 놓고 있습니다.
그래서 관심 있는 사이트의
10년 전 모습도 쉽게 찾아 볼 수 있습니다.

예를 들어 archive.org 사이트는
포털 "다음"의 웹 페이지도
1998년부터 수집해 왔습니다.

그래서 1990년대 초반의
다음 포털 초기 모습을 지금도 확인할 수 있습니다.
저는 인터넷에 관한 글을 쓸 때
이 사이트의 도움을 많이 받았습니다.
이 지면을 빌어
다시 한 번 이 사이트에 대해 감사하다는 말씀 드립니다.
얼마전까지는 네이버의 지난 자료들도
여기서 찾아 볼 수 있었습니다.
하지만 최근 네이버가 네이버 자체에 대한
외부 사이트의 데이터 수집 허용 정책을 바꾸었는지
이 사이트에서 네이버의 지난 자료가
하나도 나오지 않고 있습니다.

외부 검색 엔진이
내 웹 페이지를 수집해 가는 것을 허용할 지 여부는
robots.txt란 파일로 정할 수 있습니다.
이 파일에 "전면 허용, 일부 허용, 수집 금지" 등
원하는 설정을 지정할 수 있습니다.
외부의 웹 페이지 수집 프로그램은
내 웹사이트의 robots.txt 에 지정된 정책에 따라
데이터 수집을 진행합니다.

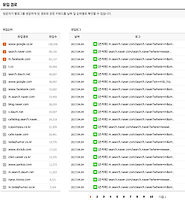
현재 네이버는 robots.txt 설정으로
외부 검색 엔진에게
네이버 내부 자료는 한 개도, 단 한 개도,
그림 하나,
웹 페이지 하나도 허용하지 않겠다고 선언했습니다.
수 많은 인터넷 사이트의 데이터를
긁어가서 돈을 버는 포털이,
robots.txt 규약도 무시하고
중소 인터넷 사이트의 데이터를
매 번 통째로 긁어 가던 것들이,
(https://ja.wikipedia.org/wiki/NaverBot)
돈 내고 인터넷 쓰는 중소 사이트 허용 트래픽을
지네들 웹 수집기로 다 소모 시키고 있는 작자들이,
외부 콘텐츠를 내부로 불법 복제해서
떼 돈을 벌고 있는 쓰레기 같은 업체가,
자신의 콘텐츠는
단 한 개도 외부에게 제공하지 않겠다고
선언하고 있는 것입니다.
그래서 인터넷 역사를 저장하고 있는 archive.org 에서도
이 따위 개 쓰레기 사이트의 역사는
기록할 필요도 없다고 판단해서
최근까지 보유하고 있던 네이버의 과거 기록까지
보여 주지 않기로 결정한 것으로 판단됩니다.
역사를 말살하고 과거 기록을 은폐한다는 점에서
명박이와 ㄹ혜와 네이버는 아무런 차이가 없습니다.
이 따위 기업이 한국에서 1위를 한다는 것은
대한민국의 천박함을
상징적으로 보여 주는 것이란 점을
기록으로 남기기 위해서
2017년 4월, 이 글을 씁니다.
김인성.
추가 : naver.com 으로 검색하면 안 나오지만
http://www.naver.com 으로
검색하면 잘 나온다는 반론에 대해서

http://www.naver.com,
http://naver.com으로는
여전히 나오지 않습니다.

https://www.naver.com으로는
과거 데이터가 나옵니다.
하지만 과거 데이터 중에도
나오는 경우가 있고 나오지 않는 경우도 있습니다.

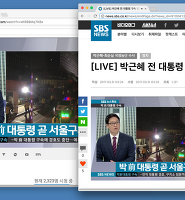
예를 들어 2003년 2.11일자는 이렇게 나오지만

2003.2.17일자는 나오지 않습니다.
이 것도 robots.txt 때문입니다.

특히 2017년 4월 자료는 하나도 나오지 않습니다.
이렇게 과거 자료 뿐만 아니라
최근 자료가 완전히 나오지 않는 것은
네이버의 robots.txt 때문입니다.
네이버의 정책이 바뀌지 않는다면
archive.org에서 2017년(또는 2016년 이전까지)의
네이버 모습을 되돌아 볼 방법은 없습니다.
제보자께서 네이버 직원이라면
하루빨리 네이버의 robots.txt 정책을 바꾸라고
건의해 주시기 바랍니다.
'창작자의 나라' 카테고리의 다른 글
| <창작자의 나라> 후원자의 밤 행사 안내 (4) | 2017.05.13 |
|---|---|
| 후원만 하고 메일도 안 주신 분 자수하세요. (3) | 2017.05.02 |
| 파이널 펀딩 안내입니다 (0) | 2017.04.28 |
| 안타깝게도, 이래서 댓글 알바를 쓰는 모양입니다. (0) | 2017.04.13 |
| 출간 펀딩 조금 심각하네요. (0) | 2017.04.12 |
| 아놔... 네이버... (0) | 2017.04.04 |
| 대한민국이 망하고 있다는 증거 (6) | 2017.03.31 |
| 또 자전거 페달을 밟습니다. (2) | 2017.03.29 |
| 당신은 천사를 본 적이 있나요? - 출간 펀딩 프로젝트 (0) | 2017.03.26 |
| 헉... 하루 만에 8분이 참여를...ㅠㅠ (0) | 2017.03.24 |